In LinkedIn wurde eine interessante Frage diskutiert, die in ihrem Ursprung zwar nicht unmittelbar mit dem Titel dieses Artikels zusammenhängt, mich aber auf Grund der abgebildeten Datenstruktur zu der Fragestellung dieses Artikels anregte. Dieser Artikel beschreibt, warum ein Clustered Index nach Möglichkeit immer einen Datentypen mit fester Länge besitzen sollte.
Der Clustered Key ist das Ordnungskriterium für einen Clustered Index. Der Schlüssel kann aus einem oder mehreren Attributen einer Tabelle bestehen. Bei der Definition des Index können bis zu 16 Spalten in einem einzigen zusammengesetzten Indexschlüssel kombiniert werden. Die maximal zulässige Größe der Werte des zusammengesetzten Index beträgt 900 Byte. Die Datentypen ntext, text, varchar(max), nvarchar(max), varbinary(max), xml oder image dürfen nicht als Schlüsselspalten für einen Index angegeben werden.
Struktur eines Datensatzes
Um zu verstehen, welche Nachteile ein Index mit variabler Datenlänge besitzt, muss man wissen, wie ein Datensatz in Microsoft SQL Server “strukturiert” ist. Der nachfolgende Code erstellt eine Tabelle mit einem Clustered Index auf “Customer_No”.
IF OBJECT_ID('dbo.Customer', 'U') IS NOT NULL
DROP TABLE dbo.Customer;
GO
CREATE TABLE dbo.Customer
(
Customer_No CHAR(10) NOT NULL,
Customer_Name CHAR(1000) NOT NULL,
CONSTRAINT pk_Customer_No PRIMARY KEY CLUSTERED (Customer_No)
);
GO
Die Tabelle wird anschließend mit 1.000 Testdatensätzen für weitere Analysen der Datenstruktur befüllt. Um die Struktur eines Datensatzes zu analysieren, werden Informationen zur gespeicherten Position benötigt.
SELECT sys.fn_PhysLocFormatter(%%physloc%%), * FROM dbo.Customer;

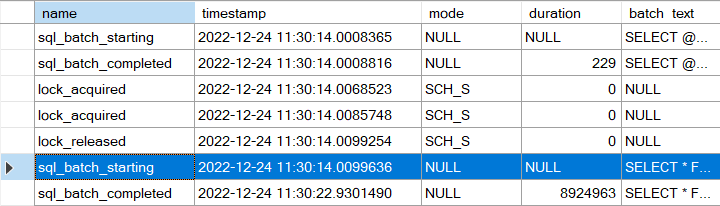
Auf Datenseite 156 werden sieben Datensätze gespeichert. Um die Datenseite – und damit die Struktur der Datensätze – einzusehen, wird mit DBCC PAGE der Inhalt der Datenseite untersucht. Wichtig bei der Verwendung von DBCC PAGE ist die vorherige Aktivierung des Traceflags 3604, um die Ausgabe vom Fehlerprotokoll in SQL Server Management Studio umzuleiten.
DBCC TRACEON (3604);
DBCC PAGE ('demo_db', 1, 156, 3);

In der Abbildung wird der erste Datensatz der Datenseite angezeigt. Der blau gerahmte Bereich repräsentiert die tatsächlich auf der Datenseite gespeicherten Informationen. Es ist erkennbar, dass der Datensatz eine Länge von 1.017 Bytes besitzt; berechnet man jedoch die Länge des Datensatzes basierend auf der Tabellendefinition, wird man bemerken, dass die Länge eigentlich nur 1.010 Bytes sein müssten. Die zusätzlichen Bytes werden für die Definition der Metadaten eines Datensatzes benötigt. Die Anzahl der zusätzlichen Informationen (Overhead) ist von den Datentypen einer Tabelle abhängig.
Datensatz-Metadaten
Die ersten zwei Bytes (0x10 00) speichern Informationen über die Eigenschaften eines Datensatzes. Da es sich um einen “gewöhnlichen” Datensatz handelt, spricht man von einem “PRIMARY RECORD”. Die nächsten zwei Bytes (0xf6 03) bestimmen das Offset zur Information über die Anzahl der Spalten in einem Datensatz. Zwischen dem Header (4 Bytes) und dem Offset befinden sich die Daten aller Attribute mit festen Datentypen.
Fixed Length Bereich
Der Hexadezimalwert 0xf6 03 ergibt umgerechnet den Dezimalwert 1.014. 4 Bytes für den Header + 10 Bytes für das Attribut [Customer_No] + 1.000 Bytes für das Attribut [Customer_Name] ergeben den Wert von 1.014 Bytes.

Die obige Abbildung zeigt den Datenbereich ab dem Byte 1.014 (rot).
Anzahl der Attribute (Spalten)
Die nächsten zwei Bytes (0x02 00) geben Aufschluss über die Anzahl der Spalten.
NULL-Bitmap
Nach den Informationen über die Struktur des Datensatzes folgen die Informationen über über Attribute, die NULL Werte enthalten dürfen (NULL Bitmap). Hierbei gilt, dass pro 8 Attribute einer Tabelle jeweils 1 Byte belegt wird. Erlaubt eine Spalte einen NULL Wert so wird das entsprechende Bit gesetzt. Da für das obige Beispiel kein Attribut einen NULL Wert zulässt, ist dieser Wert 0 (0x00).
Variable Length Bereich
Das Ende der Datensatzstruktur ist der Datenbereich für Attribute mit variabler Länge. Spalten mit variabler Länge sind mit einem deutlich höheren Aufwand von Microsoft SQL Server zu verwalten; ein Datensatz wird – bedingt durch die zusätzlichen Informationen – deutlich größer (siehe nächstes Beispiel). Für JEDES Attribut mit einem variablen Datentypen werden zwei Bytes für das Offset gespeichert, an dem der Wert für das Attribut endet. Erst zum Schluss werden die Daten selbst gespeichert. Das obige Beispiel besitzt KEINE Attribute mit variablen Datentypen; Informationen über variable Datentypen müssen nicht gespeichert werden.
Clustered Index mit variablem Datentyp
Um die Datenstruktur eines Clustered Index mit variabler Datenmenge zu untersuchen, werden die Daten der bestehenden Tabelle [dbo].[Customer] in eine neue Tabelle übertragen.
IF OBJECT_ID('dbo.Customer_Variable', 'U') IS NOT NULL
DROP TABLE dbo.Customer_Variable;
GO
CREATE TABLE dbo.Customer_Variable
(
Customer_No VARCHAR(10) NOT NULL,
Customer_Name CHAR(1000) NOT NULL,
CONSTRAINT pk_Customer_Variable_Customer_No PRIMARY KEY CLUSTERED (Customer_No)
);
GO
-- Übertragung aller Daten aus dbo.Customer
INSERT INTO dbo.Customer_Variable WITH (TABLOCK)
SELECT * FROM dbo.Customer;
GO
Mit der folgenden Abfrage werden aus jeder Tabelle der jeweils erste Datensatz ausgegeben. Zusätzlich werden Informationen zur Datenseite ausgegeben, auf der die Datensätze gespeichert wurden.
SELECT TOP 1 'Fixed length' AS ClusterType, sys.fn_PhysLocFormatter(%%physloc%%), * FROM dbo.Customer
UNION ALL
SELECT TOP 1 'Variable length' AS ClusterType, sys.fn_PhysLocFormatter(%%physloc%%), * FROM dbo.Customer_Variable;
GO

Der zu untersuchende Datensatz befindet sich auf Datenseite 1.144 und hat folgende Struktur:

Der “identische” Datensatz ist um 4 Bytes “gewachsen”. Statt 1.017 Bytes benötigt der Datensatz 4 weitere Bytes. Diese vier weiteren Bytes resultieren aus der geänderten Datensatzstruktur. Die nächste Abbildung zeigt den betroffenen Ausschnitt vergrößert an.

Die Abbildung zeigt das Ende der Datensatzstruktur. Die ersten zwei markierten Bytes repräsentieren die Anzahl der Spalten des Datensatzes. Das nächste Byte repräsentiert das NULL Bitmap. Der anschließende Bereich (2 Bytes) ist eine der Ursachen für das Wachstum der Datensatzgröße.
Der Hexadezimalwert 0x01 00 bestimmt die Anzahl der Spalten mit variablen Datensätzen. Die nächsten zwei Bytes (0xfd 03) bestimmen das Offset für das Ende des Datenbereichs für die erste Spalte mit variabler Datenlänge. Da keine weiteren Spalten vorhanden sind, beginnen unmittelbar im Anschluss die Daten des Clustered Keys.
Wer mehr Informationen zu den Strukturen eines Datensatzes wünscht, dem sei natürlich das Buch “Microsoft SQL Server 2012 Internals” von Kalen Delaney (b | t) empfohlen. Alternativ gibt es zu diesem Thema auch einen sehr guten Artikel von Paul Randal (b | t) unter dem Titel “Inside the storage engine: Structure of a record” .
Overhead
Bedingt durch die Struktur eines Datensatzes wächst die Datenlänge um maximal vier weitere Bytes. Hat die Tabelle bereits Attribute mit variabler Datenlänge gehabt, sind es lediglich zwei weitere Bytes für das Offset.
Neben der Vergrößerung des Datensatzes haben variable Datentypen noch andere Nachteile als Clustered Index:
- Der Overhead von maximal 4 Bytes ist – auf den einzelnen Datensatz reduziert – unerheblich. Die zusätzlichen 4 Bytes können aber dazu führen, dass weniger Datensätze auf einer Datenseite gespeichert werden können.
- CPU Zeit für die Evaluierung des Datenwertes, da erst das Offset für die variablen Bereiche und anschließend das Offset für den Datenbereich errechnet werden muss. Es ist sicherlich kein nennenswerter Zeitverlust aber – wie in vielen Dingen – ist die Menge der Datensätze für den Overhead entscheidend.
- Das Schlüsselattribut eines Clustered Index wird in jedem non clustered Index gespeichert. Somit verteilt sich der Overhead auch auf non clustered Indexe.
Herzlichen Dank fürs Lesen!
Hinweis
Wer Kalen Delaney live erleben möchte, dem sei die SQL Konferenz in Darmstadt vom 03.02.2015 – 05.02.2015 sehr ans Herz gelegt. Die Agenda der SQL Konferenz liest sich wie das Who ist Who der nationalen und internationalen SQL Community.
Ich bin ebenfalls als Sprecher mit einem interessanten Thema “Indexing – alltägliche Performanceprobleme und Lösungen” vertreten.

Anmerkung
Dankenswerter Weise wurde ich durch einen Kommentar des von mir sehr geschätzten Kollegen Torsten Strauss darauf aufmerksam gemacht, dass der Artikel einige Voraussetzungen “unterschlagen” hat und somit zu Fehlinterpretationen führen kann.
Die Grundvoraussetzung zur Idee zu diesem Artikel ist, dass immer mit “gleichen” Karten gespielt wird – soll heißen, dass unabhängig vom Datentypen IMMER der gleiche Datenbestand verwendet wird. Ein fairer Vergleich wäre sonst nicht möglich! Spreche ich im ersten Beispiel vom Datentypen CHAR mit einer Länge von 10 Bytes, setzt das Beispiel mit dem Datentypen VARCHAR und einer maximalen Zeichenlänge von 10 Bytes voraus, dass ebenfalls 10 Zeichen pro Datensatz im Clustered Index gespeichert werden!