Aktuell entwickeln wir eine Log Shipping Lösung für einen Kunden, der sehr viele Datenbanken (>100) auf einem Server hostet. Das standardisierte Log Shipping ist für diese Umgebung nicht geeignet, da für jede Datenbank Log Shipping separat konfiguriert werden muss. Werden die Datensicherungen automatisiert mittels Code in der DR-Site eingespielt, können Fehler auftreten, die nur als „Error 3013“ in einem TRY CATCH Block abgefangen werden können. Daraus lässt sich nicht ableiten, warum die Operation tatsächlich fehlgeschlagen ist.
Inhaltsverzeichnis
Probleme mit Backup / Restore
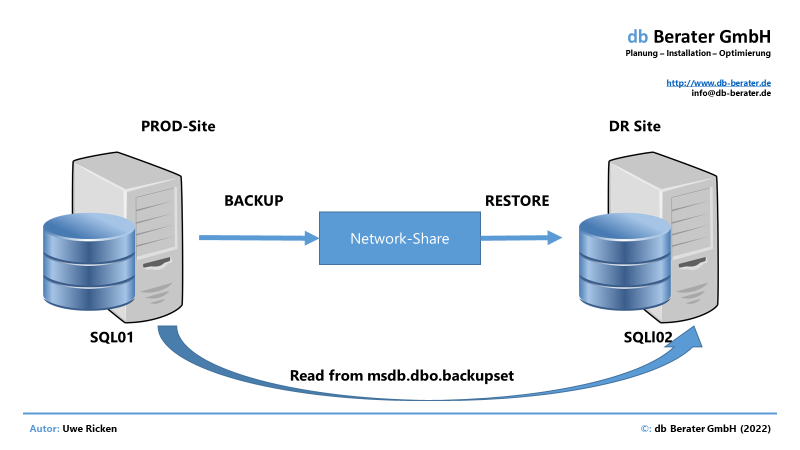
Auf der Produktionsseite werden regelmäßig Voll- und Protokollsicherungen durchgeführt. Die Informationen zu den durchgeführten Sicherungen werden in der Systemdatenbank msdb gespeichert. Eine Routine auf der DR-Site liest (über Linked Server) die Infromationen aus und stellt auf dieser Basis die Daten aus den Sicherungsdateien auf der DR-Site wieder her.
Die Wiederherstellung erfolgt in einem TRY-CATCH Block. Schlägt die Wiederherstellung fehl, erhält man – LEIDER – nur den Fehler 3013, der darauf hinweist, dass ein Fehler aufgetreten ist. Na super!
BEGIN TRY
RESTORE DATABASE Test FROM DISK = N'Z:\transfer.bak';
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS error_number,
ERROR_MESSAGE() AS error_message;
END CATCH

Führt man hingegen den RESTORE-Befehl unmittelbar – ohne TRY-CATCH – aus, wird die tatsächliche/ursprüngliche Fehlermeldung ausgegeben, die darauf hinweist, dass z. B. die Quelle nicht existiert!
RESTORE DATABASE Test FROM DISK = N'Z:\transfer.bak';

Die Ursache dieses Problems liegt darin, dass die Funktionen ERROR_NUMBER() und ERROR_MESSAGE() nur die LETZTE Fehlerinformation speichern! Schaut man sich die Ausgabe an, sieht man, dass zunächst der Fehler 3201 ausgegeben wird. Im Anschluss daran wird Fehler 3013 ausgegeben; genau die Fehlernummer, die dann in von den Fehlerfunktionen zurückgegeben werden. Gleiches gilt natürlich auch für BACKUP Befehle.
Tritt ein Fehler auf, musste das fehlerhafte RESTORE-Command aus der Historie herausgesucht und manuell ausführt werden. Nur so konnte die eigentliche Fehlermeldung erkannt werden, die den Weg zu einer entsprechenden Lösung zeigte.
Diese Einschränkung hat mich schon länger gestört und ich habe mal ein wenig im Internet nach möglichen Lösungen gesucht. Es versteht sich von selbst, dass ich mit dieser Problemstellung nicht der einzige Entwickler bin :)
Mögliche Lösungsansätze von geschätzten Kollegen
| Author | Blogartikel |
| Erland Sommarskog | Error and Transaction Handling in SQL Server (Chapter 7) |
| David Fowler | The dreaded SQL Server error 3013… |
Erland Sommarskog geht detailliert auf das Error Handling selbst ein. Seine Artikel sind recht umfangreich, aber sie beleuchten die Thematik dafür auch sehr ausführlich. Die von David Fowler vorgeschlagene Lösung habe ich ursprünglich favorisiert; jedoch stört mich an der Lösung, dass jedes Mal das Error Log eingelesen werden muss. Das schien mir dann doch zu viel des Guten :)
Extended Events – Lightweight Monitoring
Ich habe mich für eine Lösung mit Extended Events entschlossen, da sie zwei Vorteile bietet. Extended Events belasten das System nicht so stark, wie andere Operationen (z. B. xp_readerrorlog) und es wird nicht zwingend ein Dateimedium benötigt, um Protokolle zu speichern. Extended Events bieten den Ring Buffer als Speichermedium; ein flüchtiges Speichermedium, dass nur im Arbeitsspeicher existiert während das Extended Event aktiv ist.
Implementierung
CREATE EVENT SESSION [db Catch Errors]
ON SERVER
ADD EVENT sqlserver.error_reported
(
ACTION (sqlserver.session_id)
WHERE [severity] >= 16
AND [destination] = N'USER'
AND [is_intercepted] = 0
AND [error_number] <> 3013
)
ADD TARGET package0.ring_buffer
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
STARTUP_STATE = ON
);
Wird ein Fehler aufgezeichnet, der zu einem Ausführungsabbruch führt (severity >= 16), wird das entsprechende Event erfasst und im Ring Buffer (Zeile 11) gespeichert. Der Abbruch einer RESTORE / BACKUP Operation führt immer zu zwei Fehlern! Der erste Fehler beschreibt das eigentliche Problem während der zweite Fehler die Standardmeldung (3013) ausgibt. Da Fehler 3013 irrelevant ist, wird dieser Fehler bereits in der Extended Event Session herausgefiltert (Zeile 9). Um später die Fehlermeldungen des ausführenden Prozesses zu ermitteln, wird die session_id (Zeile 5) des aktuellen Prozesses benötigt, nach dem im Ergebnis gesucht werden kann!
Test mit „Live Data“
Um zu testen, ob das Event die gewünschten Informationen aufzeichnet, lasse ich während eines BACKUP / RESTORE Befehls die aktuellen Daten des Extended Events anzeigen.

Die bei der Ausführung der Befehle aufgezeichneten Fehler durch das Extended Event stellen sich wie folgt dar:

Implementierung in Code
Die große Herausforderung bei Extended Events besteht darin, die Daten (unerheblich ob aus Ring Buffer und/oder Files) auszulesen und tabellarisch so darzustellen, dass sie auszuwerten sind. Extended Events verwenden XML-Strukturen – für mich ein wahrer Graus. Leider aber die einzige Möglichkeit, die Daten auszuwerten. Den nachfolgenden Code habe ich (exemplarisch) in meine Lösung implementiert, um Fehler zu protokollieren, die sich aus BACKUP / RESTORE ergeben.
/* Variables for extraction of data from ring buffer */
DECLARE @StartTime DATETIMEOFFSET;
DECLARE @EndTime DATETIMEOFFSET;
DECLARE @Offset INT = DATEDIFF(MINUTE, GETDATE(), GETUTCDATE());
DECLARE @target_data XML;
/* table variable for storage of XML data from Extended Event */
DECLARE @EventData TABLE
(
[TimeStamp] DATETIMEOFFSET NOT NULL,
Event_Data XML NOT NULL
);
BEGIN TRY
/* Before we start the backup we save the start of the process */
SET @StartTime = DATEADD(MINUTE, @Offset, GETDATE());
/* now we force the error 3201 - no such backup device */
BACKUP DATABASE CustomerOrders TO DISK = N'Z:\Test.bak';
END TRY
BEGIN CATCH
/* Wait a second to dispatch the error to the ring buffer */
SET @EndTime = DATEADD(MINUTE, @Offset, DATEADD(SECOND, 10, GETDATE()));
/* Get the XML data from the ring buffer for the active Extended Event */
SELECT @target_data = CONVERT(xml, target_data)
FROM sys.dm_xe_sessions AS s
JOIN sys.dm_xe_session_targets AS t
ON (t.event_session_address = s.address)
WHERE s.name = N'db Catch Errors'
AND t.target_name = N'ring_buffer';
/* Save the data in table variable */
;WITH src AS
(
SELECT xm.s.query('.') AS xe
FROM @target_data.nodes('/RingBufferTarget/event') AS xm(s)
)
INSERT INTO @EventData
(Event_Data, [TimeStamp])
SELECT src.xe,
src.xe.value('(/event/@timestamp)[1]', 'datetimeoffset(7)')
FROM src;
/* Extraction of data in tabular mode */
;WITH R
AS
(
SELECT event_data.value ('(/event/@timestamp)[1]', 'DATETIME') AS [Time],
event_data.value ('(/event/action[@name=''session_id'']/value)[1]', 'SMALLINT') AS [session_id],
event_data.value ('(/event/data[@name=''error_number'']/value)[1]', 'SMALLINT') AS [error_number],
event_data.value ('(/event/data[@name=''message'']/value)[1]', 'NVARCHAR(2048)') AS [message]
FROM @EventData
)
SELECT DISTINCT
R.Time,
R.error_number,
R.message
FROM R
WHERE R.session_id = @@SPID
AND R.time >= @StartTime
AND R.time <= @EndTime;
END CATCH
Mit diesem Codeblock ist es möglich, den Fehler abzufangen und – wie auch immer – zu verwerten. Im konkreten Projekt wird die Fehlermeldung in einer Protokolltabelle gespeichert.
Herzlichen Dank fürs Lesen!





