This blog post was inspired by a post by Eric Darling on LinkedIn, where he shared his video on the topic of [NOT] EXISTS. A pleasant side effect of using EXISTS over JOIN concerns automatically created statistics in Microsoft SQL Server.
Task description
Find all customers who placed an order on January 1, 2023. Who doesn’t know such requirements. The requirement seems trivial and – at least I – have always solved it with an INNER JOIN instead of EXISTS.
/*
All customers who ordered at 01/01/2023
*/
SELECT DISTINCT
c.*
FROM dbo.customers AS c
INNER JOIN dbo.orders AS o
ON (c.c_custkey = o.o_custkey)
WHERE o_orderdate >= '2023-01-01'
AND o_orderdate <= '2023-01-02';
GO
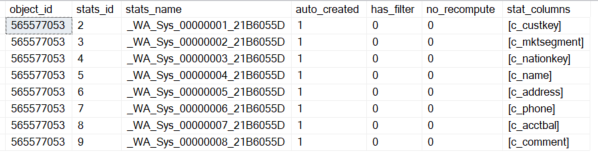
I have already described the unpleasant side effect of DISTINCT in my article „Automatically Created Statistics – know the caveats„. If output attributes previously had neither an index nor a statistics object, Microsoft SQL Server automatically creates a new statistics object.
Solution
The task only requires the output of the attributes of dbo.customers. The JOIN (a customer can have multiple orders) makes the use of DISTINCT unavoidable. However, if you rewrite the SQL statement, you no longer need to use DISTINCT.
SELECT c.*
FROM dbo.customers AS c
WHERE EXISTS
(
SELECT 1/0
FROM dbo.orders AS o
WHERE o.o_custkey = c.c_custkey
AND o_orderdate >= '2023-01-01'
AND o_orderdate <= '2023-01-02'
);
GO

Because DISTINCT is no longer required, Microsoft SQL Server no longer creates automatic statistics objects for ALL attributes of dbo.customers. Instead, a statistics object is only required for the [c_custkey] attribute. At first glance, it may not seem very significant that you have „saved“ a few statistics objects. This pleasant side effect of EXISTS over JOIN can reduce the maintenance tasks and your DBA will thank you for it.
Thank you very much for reading.





