Do you know when stale statistics are automatically updated in Microsoft SQL Server? What happens to stale statistics if your queries generate/use trivial execution plans? This article describes how SQL Server handles Auto Update Statistics in combination with Trivial Execution Plans.
Inhaltsverzeichnis
Thresholds for automatic statistics updates
Updating statistics in Microsoft SQL Server is subject to certain thresholds. I have described these thresholds in the article „AUTO_UPDATE_STATISTICS and thresholds„. To calculate the threshold, I wrote a function „dbo.get_statistics_update_info“ that is stored in my GIST repository. What happens to the automatic update process if your queries use trivial compilations? To better understand the problem, you first need to know two basic concepts of the functionality of the Query Optimizer.
Note: The concepts are presented very briefly to understand the basics. If you want more information about the complexity, I highly recommend the exceptional blog by Paul White.
Trivial Execution Plans
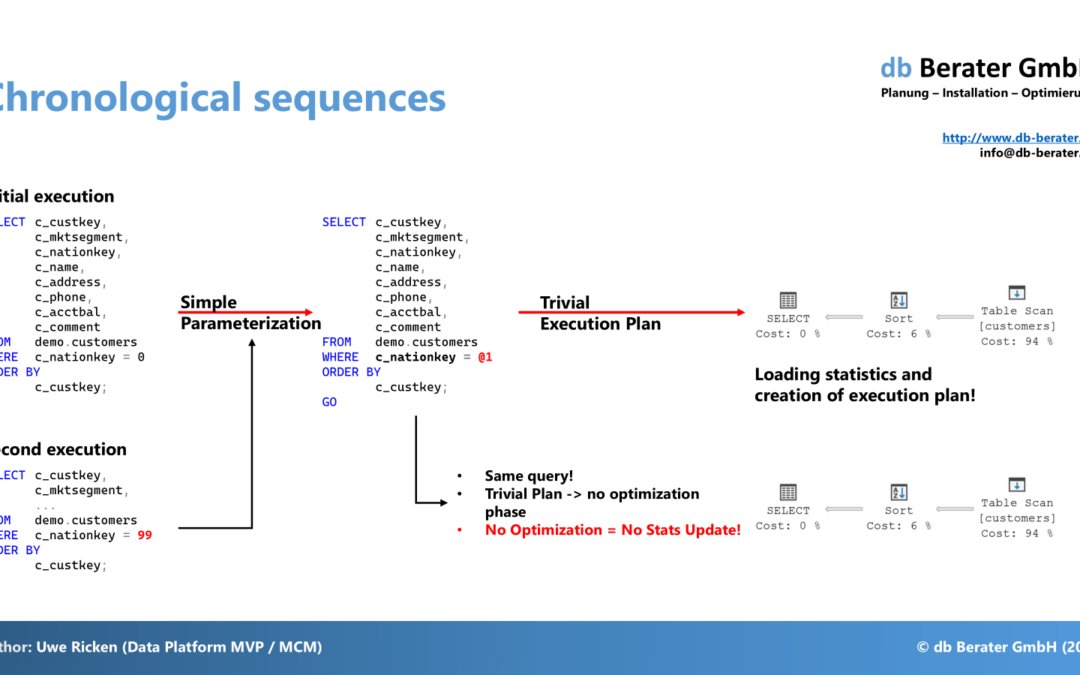
A trivial execution plan is used for very simple queries where the query optimizer determines that there is only one possible execution plan. The optimizer skips the detailed cost-based analysis and generates a simple plan. Trivial Execution Plans are typically used for queries that involve straightforward operations like single-table retrievals with simple predicates. Trivial execution plans attempt to generate a generic „prepared plan“ that is reusable using Simple Parameterization.
Simple Parameterization
Simple Parameterization is a feature that automatically parameterizes queries to improve performance. When you execute a SQL statement with literals, SQL Server internally adds parameters where needed so that it can reuse a cached execution plan.
/*
In the first step we clear the plan cache and execute the same query
with two different literals.
*/
DBCC FREEPROCCACHE;
GO
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 0
ORDER BY
c_custkey;
GO
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 1
ORDER BY
c_custkey;
GO
/* Get an inside into the cached plans! */
SELECT CP.usecounts,
CP.cacheobjtype,
CP.objtype,
CP.size_in_bytes,
ST.[text],
QP.query_plan
FROM sys.dm_exec_cached_plans AS CP
OUTER APPLY sys.dm_exec_sql_text (CP.plan_handle) AS ST
OUTER APPLY sys.dm_exec_query_plan (CP.plan_handle) AS QP
WHERE ST.[text] NOT LIKE '%dm_exec_cached_plans%'
AND ST.[text] LIKE '%customers%'
ORDER BY
CP.usecounts ASC;
GO

The execution plans of the Adhoc queries are smaller than the prepared statement.

The reason is, that Microsoft SQL Server does not save the full execution plan but a reference to the prepared statement. Both Adhoc queries are using the same prepared execution plan!
Creation of the Demo Environment
For the demos in this article, I use my database ERP_Demo, which I use for my workshops and sessions at conferences. The database contains a framework of stored procedures and user-defined functions that I use for analysis and recurring tasks.
Creation of the demo table
/* Let's create a new table in a schema called [demo] */
IF SCHEMA_ID(N'demo') IS NULL
EXEC sp_executesql N'CREATE SCHEMA [demo] AUTHORIZATION dbo;';
GO
DROP TABLE IF EXISTS demo.customers;
GO
/* Now we insert 100,000 rows into the table demo.customers */
SELECT TOP (100000)
c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
INTO demo.customers
FROM dbo.customers
ORDER BY
c_custkey;
GO
The newly created table [demo].[customers] is filled with 100,000 records.
Automatically created statistics for all columns
/*
Create the statistics objects by using DISTINT.
Than we get for each column a statistics object!
*/
SELECT DISTINCT
c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers;
GO
The last preparation step is to generate automatically generated statistics. The easiest way to do this is to use a DISTINCT on all attributes of the table.
Run the Demo
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 0
ORDER BY
c_custkey;
GO
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 1
ORDER BY
c_custkey;
GO
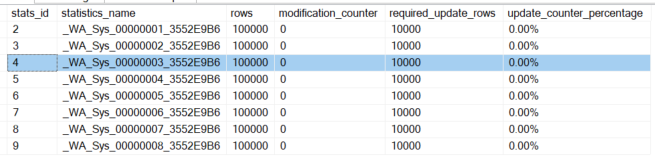
Two queries with literals (0, 1) are executed independently of each other. It is noticeable that the statistics (without updating!) are only loaded once.
The reason is that it is a Trivial Execution Plan that uses Simple Parameterization. For the second query, this means that the query optimizer does not have to compile the query again, but uses the „prepared execution plan“!

The depiction shows the execution plan and its properties. You can see the Trivial Plan Optimization and the parameter value which caused the compilation. It’s 0! that was the literal from the first execution.

Update 10,000 rows to reach the threshold for triggering the stats update
/*
Let's run 10,000 modifications on c_nationkey and check the modification counters
The CASE statement distributes the values for [c_nationkey]:
99: 10 values
0: 9.990 values
*/
;WITH l
AS
(
SELECT ROW_NUMBER() OVER (ORDER BY c_custkey) AS rn,
c_custkey
FROM demo.customers
)
UPDATE dc
SET dc.c_nationkey = CASE WHEN rn % 1000 = 0
THEN 99
ELSE 0
END
FROM demo.customers AS dc
INNER JOIN l
ON (dc.c_custkey = l.c_custkey)
WHERE l.rn <= 10000;
GO
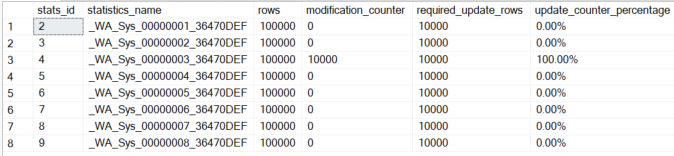
Now we run the queries with the new values in [c_nationkey] again and will face a surprise! Although the threshold for the statistics update has reached it will not update the statistics!
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 0
ORDER BY
c_custkey;
GO
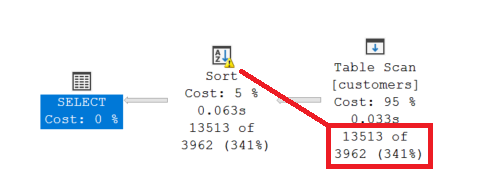
Why are the statistics not updated?
The behavior seems illogical. It is often said that Microsoft SQL Server has to recompile when the query text is changed because the hash value of the query text has to be unique. If any literal is changed, the hash value of the query text changes and a recompilation should be carried out. This concept is not taken into account in this example.
The reason for the change in behavior lies in the handling of the compilation process. SQL Server can only identify ONE suitable strategy for the query (TABLE SCAN) and classifies the optimization as Trivial. In addition, „Simple Parameterization“ replaces the literal with a variable and the – actual – query text is replaced by a text with a variable. This text does not change any further and a recompilation is no longer carried out.

How can one solve the dilemma?
Now that we know why this behavior occurs, it is up to us to find suitable solutions to always use the most up-to-date statistics possible. I don’t want to discuss the possibilities in depth in this article. That would make the blog post much too long. But I would like to briefly outline one possible solution.
Make the Trivial plan a Full Optimized Plan
If an optimization is initiated, statistics are also checked and updated if necessary. However, optimization only takes place if full optimization is achieved. To do this, the query optimizer must be „offered“ the query in such a way that it has a decision to make between at least two options.
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM demo.customers
WHERE c_nationkey = 0
AND EXISTS (SELECT 1)
ORDER BY
c_custkey;
GO
Shall I add (SELECT 1) to all my queries?
The answer is a clear NO. Before you analyze your queries and decide that all trivial queries should be modified, consider your workloads and whether it is even necessary to always have up-to-date statistics.
The case underlying this article required adjusting the query; but it was the first time in my career that I have ever seen such problems.
Thank you very much for reading.




