
von Uwe Ricken | März 12, 2025 | 300, DB Engine, SQL Blog
When using table hints, a few rules should be recommende, which – if ignored – can quickly lead to performance problems. In the database of one of our customer’s software, UPDLOCK is used as a table hint to force a serialization of processes....
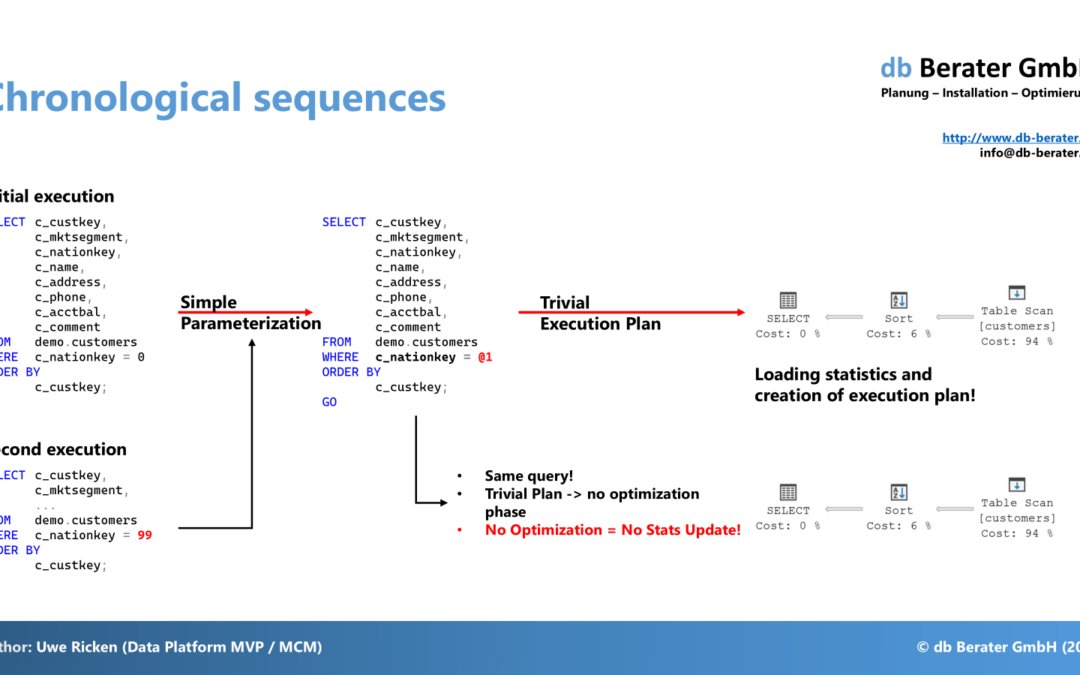
von Uwe Ricken | Jan. 19, 2025 | 300, DB Engine, SQL Blog, Statistiken
Do you know when stale statistics are automatically updated in Microsoft SQL Server? What happens to stale statistics if your queries generate/use trivial execution plans? This article describes how SQL Server handles Auto Update Statistics in combination with Trivial...
von Uwe Ricken | Dez. 21, 2024 | 300, DB Engine, SQL Blog, Statistiken
This week I was called out twice to an incident at a customer’s site where a massive blocking problem occurred in the web shop. The root cause was the AUTO_UPDATE STATISTICS option. One blog article is not enough to explain the complexity of this problem....
von Uwe Ricken | Mai 6, 2024 | 300, DB Engine, SQL Blog
Ich hatte vor kurzem das Vergnügen, eine eintägige Beratung bei einem langjährigen Kunden durchzuführen. Unter anderem wurde gezeigt, dass man die Performance von Schnittstellen optimierte, indem man die Option ALLOW_SNAPSHOT_ISOLATION für die Datenbank aktivierte....
von Uwe Ricken | Dez. 24, 2020 | 300, Administration, DB Engine, Optimierung, SQL Blog
Transaktionale Replikationen können eine wahre Herausforderung sein, wenn es darum geht, die Daten effizient zu den Subscribern zu übertragen. Letzte Woche ergab es sich, dass ein Kunde in einer Datenbank sehr große Datenvolumen änderte. Die Datenbank ist der...
von Uwe Ricken | Apr. 19, 2020 | 300, DB Engine, Indexierung, SQL Blog
Im vorherigen Artikel „Heaps – Lesen von Daten“ wurden die Möglichkeiten beschrieben, wie die Performance für das Auswählen von Daten aus einem Heap optimiert werden kann. Dieser Artikel beschreibt die Möglichkeit, mit Hilfe von NonClustered Indexes...





