Deadlocks kennt fast jeder DBA, der täglich Datenbanken betreuen muss. Der klassische Deadlock wird – meistens – durch falsche Aufrufe von Prozessen verursacht. Diese Art von Deadlocks sind schnell und relativ einfach zu lösen. Wie aber sieht es aus, wenn zwei Prozesse identische – wiederholende – Aufrufe des gleichen Objekts ausführen?
Inhaltsverzeichnis
Problemstellung
Ein Kunde beobachtete häufig auftretende Deadlocks auf einem Objekt. Obwohl nur dieses eine Objekt in einer Prozedur verwendet wurde (serielle Bearbeitung), wurde einer der beiden konkurrierenden Prozesse immer wieder Opfer eines Deadlocks.
/* Create the test table for processing */
CREATE TABLE dbo.testtable
(
id INT,
scancode VARCHAR(10),
ship_id VARCHAR(10),
istate INT
);
GO
/* Create a nonclustered index on the predicate attributes */
CREATE NONCLUSTERED INDEX nix_TestTable_scancode_ship_id
ON dbo.testtable (scancode, ship_id);
GO
/* Insert a demo record into the test table */
INSERT INTO dbo.testtable
(scancode, ship_id, istate, id)
VALUES
('0000000000', '4711', 0, 1);
GO
Die Tabelle wird für die serielle Verarbeitung von Prozessen verwendet und ändert in einer Prozedur das Attribut [isstate] zu Beginn des Prozesses und – sobald der Prozess abgeschlossen ist – am Ende des Prozesses
CREATE OR ALTER PROCEDURE dbo.StartProcess
@scancode VARCHAR(10),
@ship_id VARCHAR(10)
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION
/* We lock the resource to prevent other activity */
UPDATE dbo.testtable
SET istate = 1
WHERE scancode = @scancode
AND ship_id = @ship_id;
/* Now we start our activity which takes app. 10 seconds */
WAITFOR DELAY '00:00:10';
/*
and release the lock when the process is done
AT THIS POINT WE RUN INTO A DEADLOCK!
*/
UPDATE dbo.testtable
SET istate = 0
WHERE scancode = @scancode
AND ship_id = @ship_id;
COMMIT TRANSACTION;
END
GO
Ausführung und Problembeschreibung
Sobald die Stored Procedure von zwei konkurrierenden Prozessen gestartet wird, ergibt sich – IMMER – das folgende Bild:

Der später ausgeführte Prozesse (62) wird nach ca. 10 – 15 Sekunden mit der folgenden Fehlermeldung beendet:
Msg 1205, Level 13, State 45, Procedure dbo.StartProcess, Line 11 [Batch Start Line 3]
Transaction (Process ID 62) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.

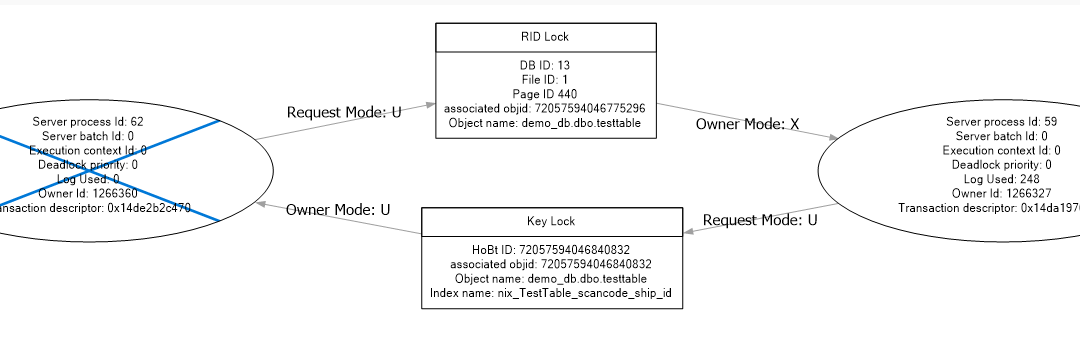
Der Deadlock-Graph zeigt, dass Prozess 62 als Opfer ausgewählt wurde und Prozess 59 erfolgreich ausgeführt wurde. Betrachten wir zunächst die gesetzten Sperren von Prozess 59 während der Ausführung:

Prozess 59 hält eine e(X)klusive Sperre auf den in der Testtabelle befindlichen Datensatz [RID]. Bei der Tabelle handelt es sich um einen Heap, der durch einen Nonclustered Index unterstützt wird. Diese akquirierte Sperre wird ebenfalls im Deadlock Graph (oben links) als „Owner Mode: X“ angezeigt. Prozess 62 möchte eine (U)pdate-Sperre setzen und muss warten, bis Prozess 59 die e(X)klusive Sperre freigibt. Gleichzeitig hält Prozess 62 aber bereits eine (U)pdate-Sperre auf dem Index, den auch Prozess 59 für sich beansprucht. Diese Situation ist nicht auflösbar und somit wählt Microsoft SQL Server einen Prozess aus, der beendet werden muss. Hierbei überprüft Microsoft SQL Server das Transaktionsvolumen beider Prozesse und als Opfer wird standardmäßig der Prozess gewählt, der das geringste Transaktionsvolumen aufweist.
Deadlockanalyse
Bei primitiven Deadlocks benötigt man kein tieferes Verständnis für die Sperrmechanismen von Microsoft SQL Server. Prozess 1 sperrt Tabelle A und Prozess 2 sperrt Tabelle 2 ist eine Trivialität und kann durch ändern der Geschäftsprozesse schnell gelöst werden. Hier sieht es aber etwas anders aus, da eben nicht mehrere Tabellen in Konkurrenz zueinander stehen. Wirklich nicht? Eigentlich schon, wenn man einen Index wie eine Tabelle behandelt. Letztendlich ist ein Index nichts anderes als eine Kopie von Daten der Tabelle an einem anderen Speicherort. Dennoch erfordert die Analyse eines solchen Problems tiefere Kenntnisse von Sperren und Sperrketten in Microsoft SQL Server.
sys.dm_tran_locks
Während beide Prozesse um die begehrten Ressourcen konkurrieren, werden die Sperren der Prozesse in der Datenbank und – mögliche – Konflikte analysiert. Ein sehr guter Einstieg dazu ist die Systemview [sys].[dm_tran_locks].
[sys].[dm_tran_locks] ist eine Systemkatalogansicht, die Informationen über die gesperrten Ressourcen in einer SQL Server-Datenbank bereitstellt. Sie wird verwendet, um Details zu den unterschiedlichen Arten von Sperren und den beteiligten Transaktionen abzurufen. Diese Informationen können bei der Analyse von Konflikten, der Überwachung der Datenbankleistung und der Diagnose von Sperren in Multi-User-Umgebungen nützlich sein.
SELECT request_session_id,
resource_type,
CASE WHEN resource_type = N'OBJECT'
THEN OBJECT_NAME(resource_associated_entity_id)
ELSE CAST (NULL AS NVARCHAR(100))
END AS resource_associated_entity_id,
resource_description,
request_mode,
request_type,
request_status
FROM sys.dm_tran_locks
WHERE resource_database_id = DB_ID()
AND resource_type <> N'DATABASE'
ORDER BY
request_session_id,
resource_type;

Die Analyse zeigt, dass Prozess 62 darauf wartet, dass der Datensatz 0 auf Datenseite 440 für eine Schreiboperation gesperrt werden kann (Zeile 8). Dieser Datensatz wird aber durch Prozess 59 mit einer exklusiven Sperre verwaltet. Bleiben wir zunächst bei den angeforderten Sperren, die durch den Deadlock-Graphen sichtbar gemacht wurden. Es sind zwei unterschiedliche Sperren, die Microsoft SQL Server für den Prozess anwendet:
LCK_M_U
Die Sperre LCK_M_U steht für „Lock Mode Update“. Eine LCK_M_U-Sperre wird verwendet, wenn ein Prozess eine Ressource exklusiv sperren muss, um eine Aktualisierung durchzuführen. Dies bedeutet, dass während dieser Sperre kein anderer Prozess Schreibzugriff auf die gesperrte Ressource hat. Durch die Verwendung dieser Sperre wird sichergestellt, dass andere Prozesse während des Updatevorgangs nicht gleichzeitig schreibend auf die Ressource zugreifen und somit Konflikte und Inkonsistenzen vermieden werden. Ein immer wieder unterschlagender – aber wichtiger – Punkt ist, dass Microsoft SQL Server IMMER zunächst eine (U)pdate-Sperre verwendet, die für den eigentlichen Schreibprozess anschließend in eine e(X)klusive Sperre umgewandelt wird.
LCK_M_X
Die Sperre LCK_M_X steht für „Lock Mode Exclusive“ in Microsoft SQL Server. Diese Sperre wird verwendet, um einen exklusiven Sperrenmodus auf einer Ressource, wie z.B. einer Datenbankressource oder einer Datenseite, zu setzen. Der exklusive Modus verhindert, dass andere Transaktionen gleichzeitig auf die gesperrte Ressource zugreifen können. Für eine LCK_M_X Sperre gilt, dass sie vorher mit einer LCK_M_U-Sperre abgesichert wird!
Bewertung des Deadlock-Graphen
Wenn man um die Bedeutung der unterschiedlichen Sperren weiß, kann man die Deadlocksituation entschlüsseln:
- Prozess 59 hält eine exklusive Sperre auf den Datensatz im Heap
- RID Lock = Datensatz
- LCK_M_X Sperre = exklusiver Schreibzugriff
- Prozess 59 möchte einen Eintrag im Index vor schreibenden Zugriffen schützen
- Key Lookup = Indexierter Eintrag
- LCK_M_U Sperre = nicht schreiben aber vor anderen Schreibprozessen schützen
- Prozess 62 hat bereits den Eintrag im Index vor anderen Schreibprozessen geschützt
- Key Lookup = Indexierter Eintrag
- LCK_M_U Sperre = nicht schreiben aber vor Änderungen durch andere Prozesse schützen
- Prozess 62 möchte, nachdem der Indexeintrag geschützt wurde, den eigentlichen Datensatz im Heap aktualisieren
- RID Lock = Datensatz
- LCK_M_U Sperre = Anfrage für Änderungen, eine Konvertierung zu einer LCK_M_X Sperre wäre bei Erfolg der nächste Schritt
Extended Event für die Überwachung von Sperren
Um das Sperrverhalten der beiden Prozesse genauer zu beleuchten, wird die nachfolgende Extended Event Session implementiert. Mit ihr lassen sich angeforderte und freigegebene Sperren protokollieren. Das Extended Event filtert explizit auf die beiden Prozesse, die in der Testumgebung verwendet werden.
CREATE EVENT SESSION [demo]
ON SERVER
ADD EVENT sqlserver.lock_acquired
(
ACTION(sqlserver.session_id)
WHERE (
(
[Mode] = 'U'
OR [Mode] = 'X'
OR [Mode] = 'IU'
OR [Mode] = 'IX'
)
AND [database_id] = 13
)
),
ADD EVENT sqlserver.lock_released
(
ACTION(sqlserver.session_id)
WHERE (
(
[Mode] = 'U'
OR [Mode] = 'X'
OR [Mode] = 'IU'
OR [Mode] = 'IX'
)
AND [database_id] = 13
)
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION [demo] ON SERVER STATE = START;
GO
Nachdem das Extended Event implementiert und gestartet wurde, wird die Prozedur erneut von zwei Prozessen simultan gestartet. Prozess 59 ist der führende Prozess. Die Aufzeichnungen des Extended Events ergeben das nachfolgende Bild
Prozess 59 – Konvertierung der Sperren

Da ein Update durchgeführt werden soll, wird mit einem (I)ntent E(X)CLUSIVE Lock auf die Tabelle eine Sperrkette initialisiert. Sobald die Sperre gesetzt wurde, wird mit einer IU Sperre die Datenseite auf die exklusive Sperre vorbereitet. Gleiches gilt für den Datensatz selbst. Aber Achtung – es handelt sich hierbei NICHT um den Datensatz im Heap sondern um den Index!
Diese Vorgehensweise ist logisch, da Microsoft SQL Server sowohl die Daten im Index als auch in der Tabelle selbst vor anderen Schreibprozessen absichern muss! Sobald der Datensatz im Index erfolgreich geschützt wurde, kann Microsoft SQL Server den Datensatz im Heap vorbereiten. Durch eine IU-Sperre wird die Datenseite geschützt um im anschließenden Prozessschritt den Datensatz (RID) zu schützen. Erst, wenn die komplette Strukturkette geschützt ist, kann Microsoft SQL Server die Datenseite als auch den Datensatz mit einer exklusiven Sperre versehen. Damit ist die vollständige Struktur abgesichert und Microsoft SQL Server führt die Änderung am Datensatz aus.
Besondere Beachtung gilt den letzten beiden Einträgen. Sobald der Schreibprozess des Datensatzes abgeschlossen ist, wird der Schutz für den Index wieder entfernt. Das geschieht nur, wenn die Aktualisierung nicht auch Einträge des Indexes betreffen. Die Sperre auf dem Datensatz im Heap bleiben bestehen da die Transaktion noch nicht abgeschlossen ist.
Prozess 62 – Blockierung durch Prozess 59
Prozess 62 führt die gleichen Prozessschritte aus, wie Prozess 59. Jedoch zeigt die Aufzeichnung jetzt das Problem.

Nachdem der Prozess 62 die Datenseite mit einer (U)pdate-Sperre versehen hat, konnte der Datensatz selbst nicht mehr geschützt werden; er wird ja immer noch von Prozess 59 blockiert. Erst ca. 10 Sekunden später beginnt Prozess 59 mit der weiteren Abarbeitung des Prozesses während Prozess 62 die gesetzten Sperren wieder freigibt.
Problembehebung
Das Szenario zeigt, wie komplex der Schutz der transaktionalen Sicherheit ist. Im obigen Szenario ist das Problem ein „falscher“ Index, der durch die Transaktion mit einem LCK_M_U vor ungewollten Änderungen geschützt wird. Letztendlich zeigt das Szenario, dass Deadlocks immer zwei Partner benötigten. Dabei ist es unerheblich, ob es sich um zwei voneinander unabhängige Tabellen oder eine Tabelle und einen unterstützenden Index handelt.
Die Lösung für dieses Problem liegt in der Reduktion der beteiligten Objekte.
Tabelle ohne Index (HEAP)
Sicherlich würde diese Option funktionieren. Das setzt aber voraus, dass nur sehr wenige Datensätze vorhanden sind und die Prozesse möglichst schnell beendet werden. Es wäre eine Option, die ich persönlich nur ungern implementieren würde.
Clustered Index auf [id]
Letztendlich ebenfalls eine valide Lösung mit den gleichen Schwächen, wie sie der HEAP hat. Die Attribute, auf denen gesucht wird, werden durch einen Clustered Index nicht abgedeckt. Daraus ergibt sich erneut ein FULL SCAN auf die Tabelle selbst. Auch diese Option wäre zwar machbar aber ich würde sie so nicht implementieren.
Clustered Index auf [scancode] und [ship_id]
Diese Option verspricht den größten Erfolg, da in diesem Fall die Prädikate vollständig durch die Schlüsselattribute des Index abgedeckt wären und kein dedizierter Index mehr für die Suche nach dem Datensatz benötigt wird.
Nonclustered Index auf [scancode], [ship_id] und [is_state]
Diese Lösung würde ebenfalls funktionieren, da in diesem Fall (egal, ob [is_state] als Schlüsselattribut oder mittels INCLUDE hinzugefügt wird) der Index selbst ebenfalls aktualisiert werden muss. Somit bleibt in der Transaktion auch der Index mit einer e(X)klusiven Sperre versehen, bis die Transaktion beendet ist.
Herzlichen Dank fürs Lesen!





