
Wenn es um die Speicherung von „Large Object Data“ in Microsoft SQL Server geht, gehen viele Entwicklungen in die falsche Richtung. Applikationen speichern Dokumente, Bilder, .. immer noch IN der Datenbank. Microsoft stellt dazu die Datentypen (N)VARCHAR(MAX) und VARBINARY(MAX) zur Verfügung. Antiquierte Datenbanksysteme verwenden TEXT oder IMAGE. Diese Datentypen haben jedoch Schwächen, die performancerelevant sind.
Inhaltsverzeichnis
Was sind LOB-Daten?
In Microsoft SQL Server bezieht sich der Begriff LOB-Daten (Large Object Data) auf Daten, die in speziellen Datentypen gespeichert werden, die dafür ausgelegt sind, große Mengen an binären oder textuellen Daten zu speichern. LOB-Datentypen sind für Daten vorgesehen, die größer sind als die typischen Größenbeschränkungen von Standarddatentypen wie VARCHAR oder VARBINARY. Es gibt zwei Hauptkategorien von LOB-Datentypen:
Textbasierte LOBs
| TEXT | Wird verwendet, um sehr große alphanumerische Datenmengen zu speichern. Dieser Datentyp ist veraltet und sollte in neuen Anwendungen vermieden werden. |
| NTEXT | Ähnlich wie TEXT, aber für Unicode-Daten. Auch dieser Datentyp ist veraltet. |
| VARCHAR(MAX) | Empfohlen für sehr lange Zeichenfolgen, die größer sind als 8.000 Bytes. |
| NVARCHAR(MAX) | Für sehr lange Unicode-Zeichenfolgen. |
Binäre LOBs
| IMAGE | Wird verwendet, um große binäre Datenmengen (z. B. Bilder oder Dokumente) zu speichern. Auch dieser Datentyp ist veraltet. |
| VARBINARY(MAX) | Empfohlen für sehr große binäre Daten, z. B. Dokumente, Bilder, Audio, Video. |
Wie werden LOBs gespeichert
LOB-Daten können innerhalb der Zeile (in-row) oder außerhalb der Zeile (out-of-row) gespeichert werden. SQL Server speichert kleinere LOB-Daten in der Regel innerhalb der Zeile, sofern ein Datensatz inklusive der LOB vollständig auf eine Datenseite passt. Passt ein vollständiger Datensatz nicht auf eine Datenseite, werden LOB außerhalb der Zeile gespeichert.
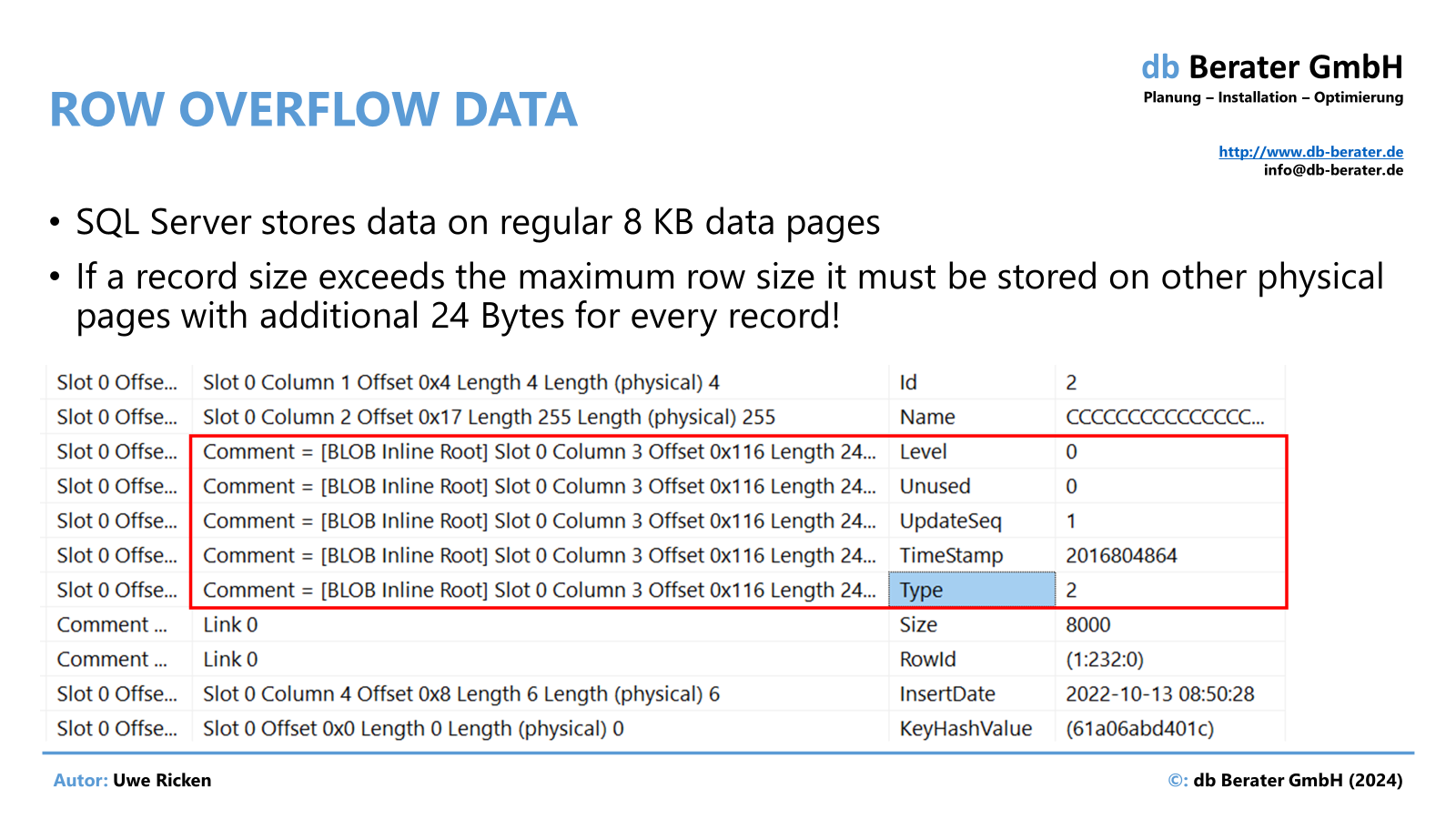
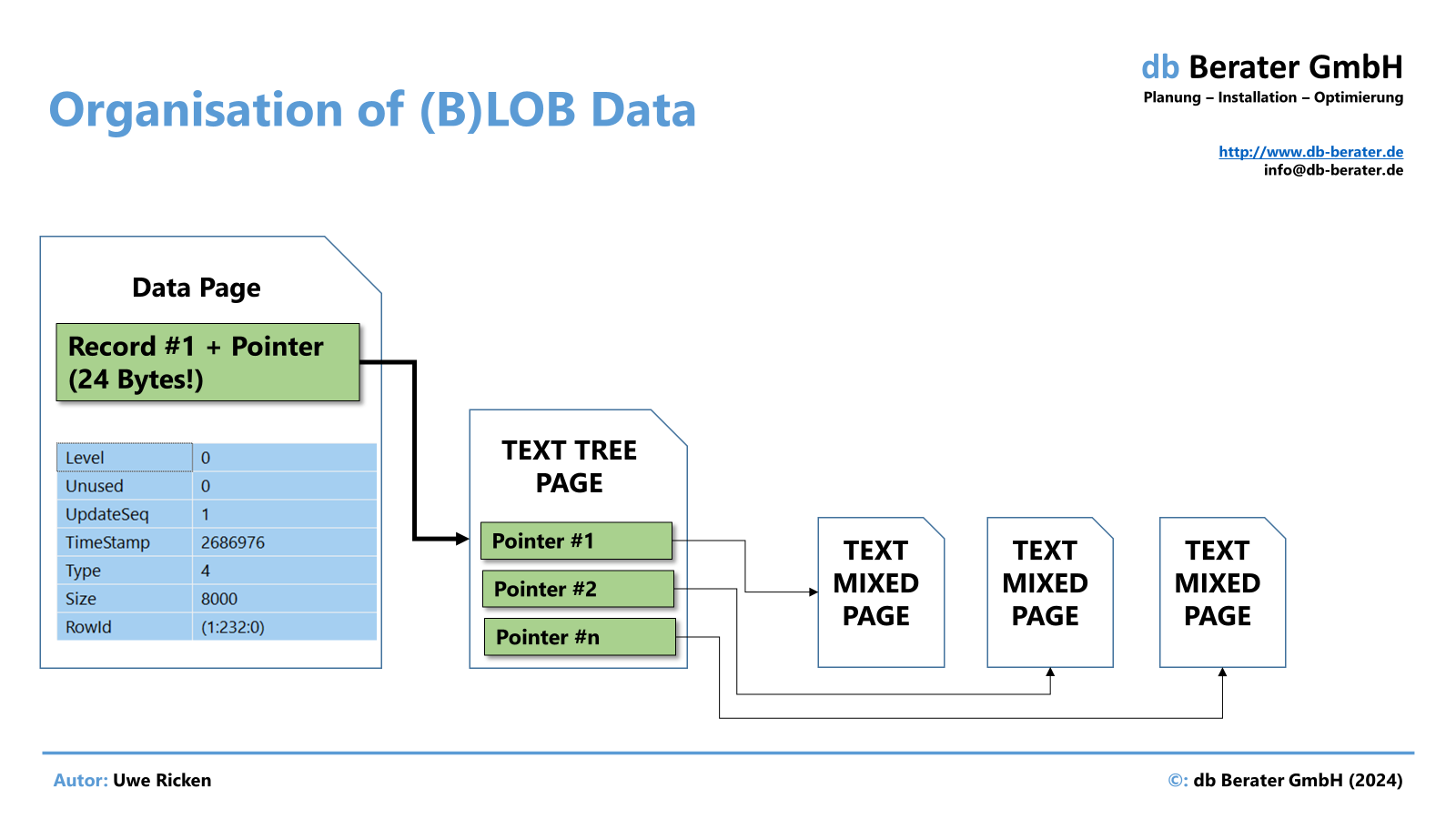
Können die LOBs nicht mit dem Datensatz auf einer Datenseite gespeichert werden, sorgt ein Pointer im Datensatz für die Zuordnung zu den – auf anderen Datenseiten – gespeicherten LOB.
Nachteile von LOB-Daten
Die Performance bei der Arbeit mit LOB-Daten kann durch deren Größe und Speicherort beeinflusst werden. Ebenfalls stellen LOBs die DBA vor große Herausforderungen, wenn es um die Verwaltung der Datenbankgröße geht. Werden Datensätze und deren LOBs gelöscht oder geändert, wird der Speicherplatz nicht sofort freigegeben. Auch ein SHRINKFILE hilft nicht zwingend, den freien Platz wieder zur Verfügung zu stellen. Um den Speicher wieder für andere Objekte zur Verfügung zu stellen, muss ein INDEX REORGANIZE mit der Option (LOB_COMPACTION = ON) ausgeführt werden.
LOB-Daten und Nonclustered Indexe
Unser Kunde hatte neben einem geclusterten Index einen weiteren – nonclustered – Index erstellt, in dem mit INCLUDE die LOBs ebenfalls vorhanden waren. Hier verhält sich Microsoft SQL Server – aus meiner persönlichen Sicht – nicht wirklich effizient, wie das folgende Beispiel zeigt
/* creation of a new table which stored LOBs */
CREATE TABLE dbo.customers
(
id INT NOT NULL,
name VARCHAR(64) NOT NULL,
company_logo VARBINARY(MAX),
CONSTRAINT pk_customers PRIMARY KEY CLUSTERED (Id)
);
GO
/* make sure LOBs are always stored on separate pages */
EXEC sp_tableoption
@TableNamePattern = N'dbo.customers',
@OptionName = N'large value types out of row',
@OptionValue = 'true';
GO
Nachdem die Tabelle – mit einem geclusterten Primärschlüssel – erstellt wurde, wir mit Hilfe der Option „large value types out of row“ sichergestellt, dass LOBs niemals mit den „in-row“ Daten gespeichert werden. Damit ist sichergestellt, dass beim Hinzufügen eines neuen Datensatzes immer ein Pointer verwendet wird, der auf die eigentlichen Bilddaten verweist!
Bei 100 Datensätzen mit einer Bilddatei von ca. 460 KB belegt die Tabelle mehr als 47 MB Speicher.
SELECT OBJECT_NAME(p.object_id) AS object_name,
p.index_id AS index_id,
FORMAT(P.rows, N'N0', 'en') AS rows,
SIAU.type_desc,
CAST(SIAU.used_pages / 128.0 AS NUMERIC(10, 2)) AS space_mb,
sys.fn_PhysLocFormatter(SIAU.first_iam_page) AS first_iam_page,
sys.fn_PhysLocFormatter(SIAU.root_page) AS root_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P ON (SIAU.container_id = P.partition_id)
WHERE P.object_id = OBJECT_ID(N'dbo.Customers', N'U')
OR p.object_id = OBJECT_ID(N'dbo.customer_logo', N'U')
ORDER BY
OBJECT_NAME(p.object_id),
p.index_id;
GO

Anschließend wird ein nonclustered Index erstellt, der die LOB inkludiert.
/* Now we create a NCI with the LOB included */
CREATE NONCLUSTERED INDEX nix_customers_name
ON dbo.customers (name)
INCLUDE (company_logo);
GO
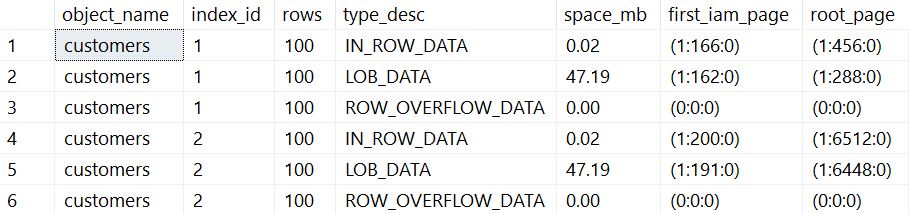
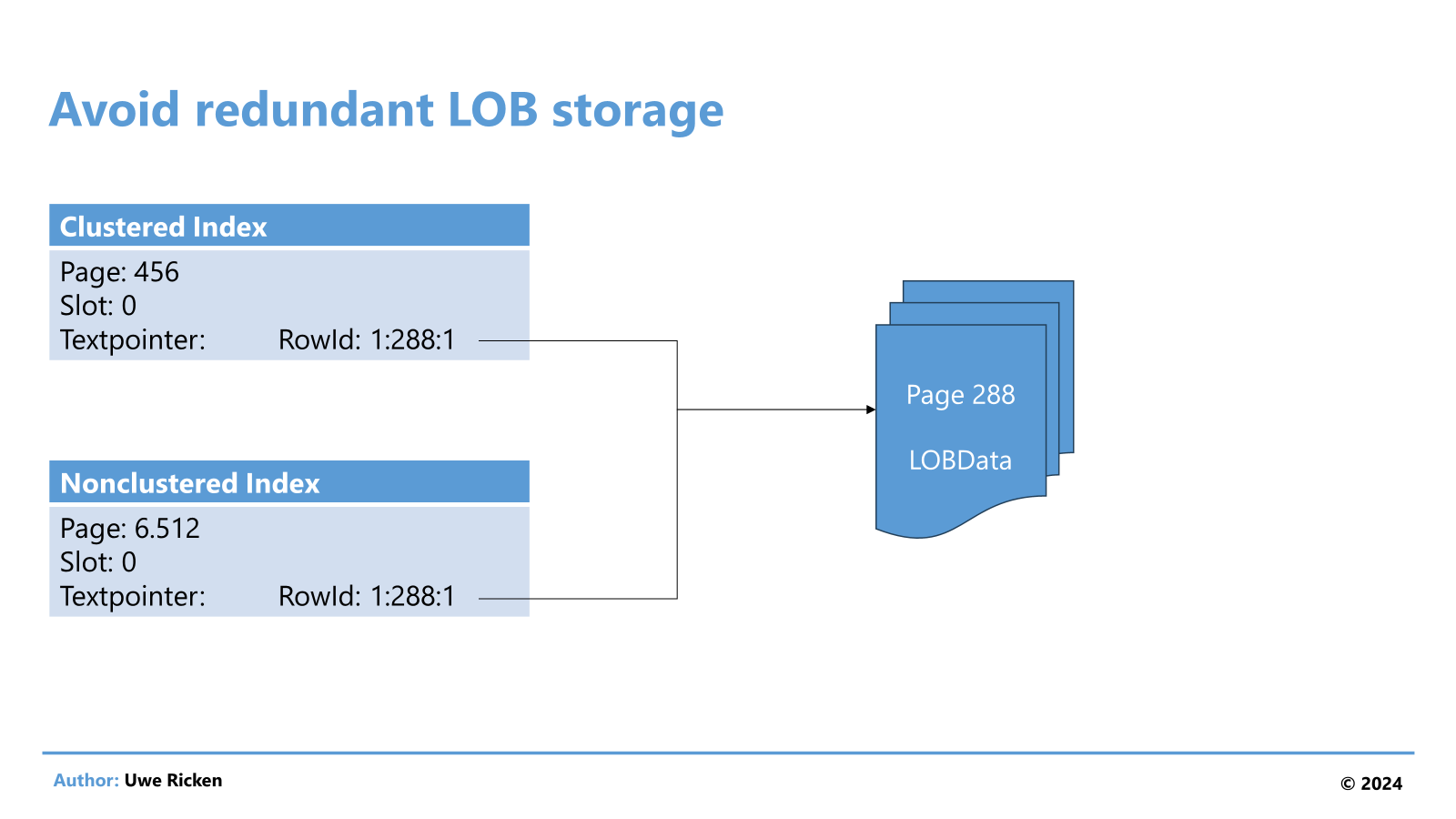
Das Problem ist offensichtlich. Microsoft SQL Server hat die LOBs für den nonclustered Index erneut schreiben müssen. Somit liegen die gleichen Daten redundant vor. Daraus ergeben sich eine Vielzahl von Performanceprobleme:
Werden LOBs eingetragen, aktualisiert oder gelöscht, so muss das – für das obige Beispiel – auf jeden Index angewendet werden. Insbesondere bei großen LOBs führt das zu längeren Transaktionen, die wiederum zu längeren Blockaden der betroffenen Ressourcen.
Abfragen können nicht wirklich von der Speicherung der LOBs im Index profitieren, da LOBs immer Heapstrukturen entsprechen und das IO nicht signifikant reduziert wird.

Was könnte Microsoft tun, um das Dilemma der Redundanz zu lösen?
Gestehen wir uns ein, dass es nicht ratsam ist, LOBs in Nonclustered Indexen zu speichern. Gestehen wir uns ebenfalls ein, dass es wahrscheinlich nur Grenzfälle sind, bei dem es zu solchen – kreativen – Konstruktionen kommt. Wenn es auch nur wenige sind, sollte Microsoft sie berücksichtigen; und das wäre meines Erachtens nach relativ einfach:
- Wenn eine Tabelle LOBs grundsätzlich außerhalb der „In-Row“-Struktur speichert, wird für jeden Datensatz ein Pointer zur „TEXT TREE PAGE“ gespeichert (16 Bytes)
- Wenn die Option „large value types out of row“ für eine Tabelle aktiviert ist, kann Microsoft SQL Server darauf vertrauen, dass LOB niemals mit den „in-row“ Daten gespeichert werden.
- Warum speichert Microsoft SQL Server nicht diesen Pointer aus dem Clustered Index / Heap in einem Nonclustered Index statt den LOB-Eintrag komplett erneut zu speichern?
Workaround
Mit Boardmitteln kann man dieses Dilemma nur lösen, indem man LOBs in einer separaten Tabelle speichert. Bei diesem Vorgehen besteht eine 1:1 Verbindung zwischen der ursprünglichen Tabelle und der Tabelle, die die ausgelagerten BLOB speichert!
DROP TABLE IF EXISTS dbo.customer_logo
GO
/* Create a separate table for the LOB data */
CREATE TABLE dbo.customer_logo
(
customer_id INT NOT NULL,
company_logo VARBINARY (MAX) NULL,
CONSTRAINT pk_customer_log PRIMARY KEY CLUSTERED (customer_id),
CONSTRAINT fk_customer FOREIGN KEY (customer_id)
REFERENCES dbo.customers (id)
ON DELETE CASCADE
);
GO
/* now we transfer the LOB data into the new table */
INSERT INTO dbo.customer_logo WITH (TABLOCK)
(customer_id, company_logo)
SELECT id, company_logo
FROM dbo.customers;
GO
/* ... and remove the former LOB column from the original table */
ALTER TABLE dbo.customers
DROP COLUMN company_logo;
GO
/* Finally we must rebuild the clustered index to release the LOB allocations */
ALTER INDEX ALL ON dbo.customers REBUILD

Abfragen werden nur geringfügig „langsamer“ – aber das eher akademischer Natur und wohl kaum messbar. Microsoft SQL Server verwendet zwei Tabellen, die mit einem NESTED LOOP oder MERGE JOIN interagieren.
/* Select ALL customers with their logos */
SELECT *
FROM dbo.customers AS c
INNER JOIN dbo.customer_logo AS cl
ON (c.id = cl.customer_id)

/* Select dedicated customer with its logo '/
SELECT *
FROM dbo.customers AS c
INNER JOIN dbo.customer_logo AS cl
ON (c.id = cl.customer_id)
WHERE c.id = 10;

Hinweis
Das Kapitel zur Einführung in LOB wurde teilweise mit Hilfe von chatGPT erstellt.
Herzlichen Dank fürs Lesen!





