
How can SWITCH PARTITION be a bad idea? Do you work with partitioning and know the many advantages that this technology offers? Do you use this technology in DWH to improve workloads or in OLTP systems to optimize scaling? Be careful with SWITCH PARTITION. It should be avoided or optimized for a specific type of workload.
Inhaltsverzeichnis
What does SWITCH PARTITION mean?
The SWITCH PARTITION command in SQL Server is used to move data quickly and efficiently between tables. This technique is particularly useful for large datasets where you want to improve manageability. If you google the term „SWITCH PARTITION“ you will get the following use cases listed:
Data Archiving
Move old data to an archive table while keeping the current data in the main table.
This is a flimsy use case. Partitioning can handle ARCHIVING perfectly by using dedicated filegroups and columnstore compression for old data. So there is no real reason to move the data to another table; it would also be more complicated for an application to access the data if it expected the data to be in the actual table!
Data Import / Export
Efficiently load data into a partitioned table or export data out.
This is where the real advantage of SWITCH PARTITION in/out lies, but import into a DWH table can be solved directly if the table option „LOCK_ESCALATION = AUTO“ is used. Only the affected partition is locked and the applications work – largely – without disruption.
Example
What about changing large amounts of data without disrupting the business? SWITCH PARTITION helps with a workload from a customer who has daily partitions for the last 90 days. It can happen that data from previous days must be recalculated. The daily partition is then „taken“ off the table and is recalculated in an independent table. This partition is then added back to the table.
Performance Tuning
Partitioning can greatly enhance query performance, particularly in large databases, by reducing scan times, improving index efficiency,…
Really? I’m too tired to keep commenting on the same old nonsense about „partitioning optimize your queries“. I’ve written about it in detail „Partitionierung hat nichts mit Performance Tuning zu tun„. Make up your own mind on this topic.
Rolling Window
Manage data in a rolling window by switching old partitions out and new partitions in.
What is means here is that old data (in an existing partition) is removed from the table with SWITCH OUT and new – processed – data is added from a STAGING table with SWITCH IN.
Customer Workload
Let’s explore the concept of a „rolling window“. It’s the type of workload that a customer implemented to remove old data (partitioned based on years) from the table and provide a new partition for the new year. The production table is partitioned on the partition schema ps_orders. Data from 2010 were switched out to a staging table based on the same partition schema.
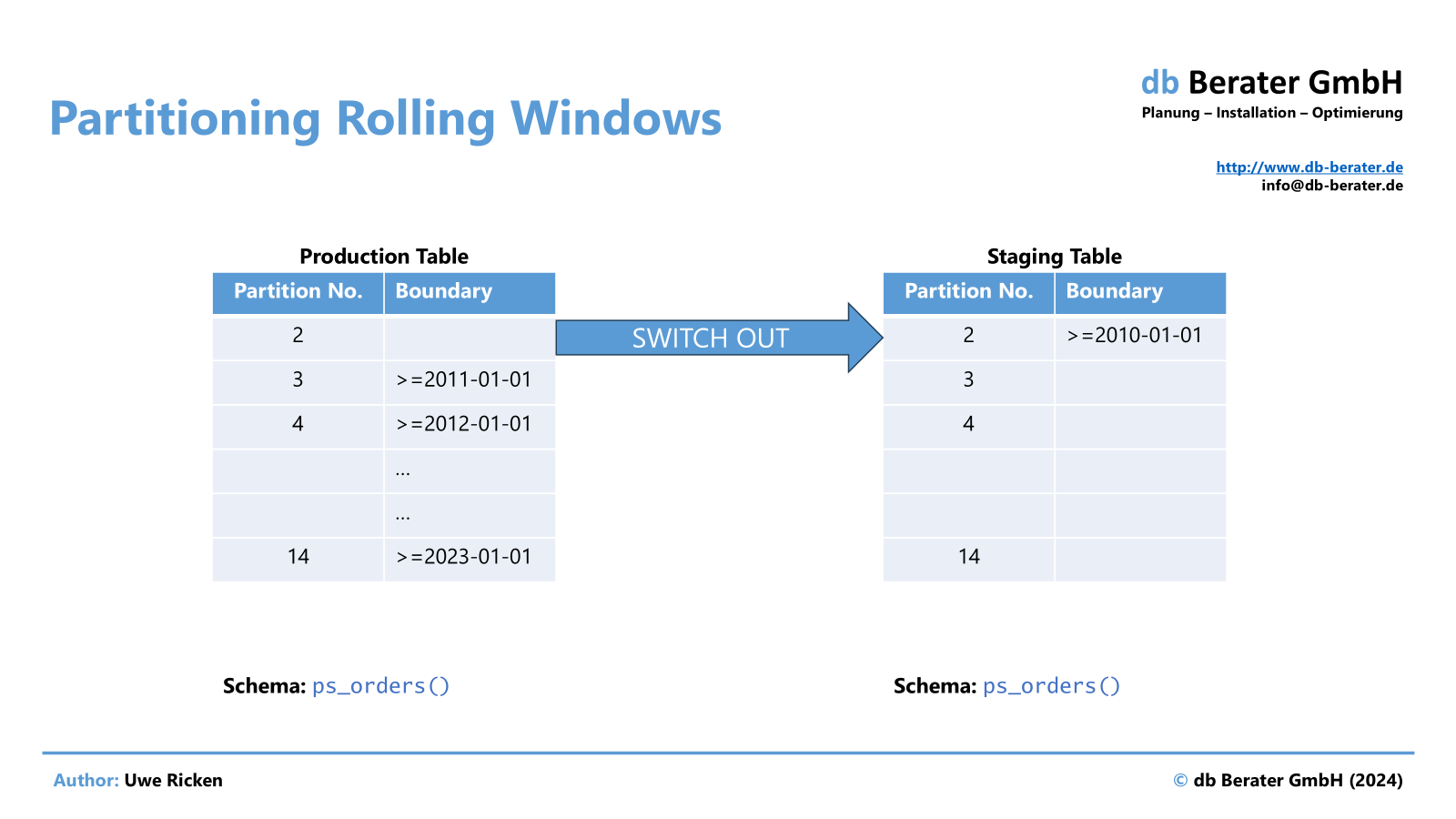
A SQL Server Agent job automates the process, which – simplified – executes the process chain with the following commands:
/* Switch out the year 2010 from the application table into a staging table */
ALTER TABLE dbo.orders SWITCH PARTITION 2 TO switch.orders;
/* Modify the boundaries for the partition function to reflect the missing year 2010 */
ALTER PARTITION FUNCTION pf_o_orderdate() MERGE RANGE ('2010-01-01');
/* Drop the staging table with the old data from 2010 */
DROP TABLE IF EXISTS switch.orders;
GO
The partition switch is carried out, but the customer complains about the size of the transaction log after the routine task. He also noticed that the process takes about 10 – 15 minutes. Wait! 10-15 minutes for a pure DDL operation? The transaction volume and the runtime do not support the statement! The customer is absolutely correct in his assumption that a PARTITION SWITCH is a DDL statement. A DDL statement does not manipulate the data itself, but only the metadata of the object. So where does this runtime come from?
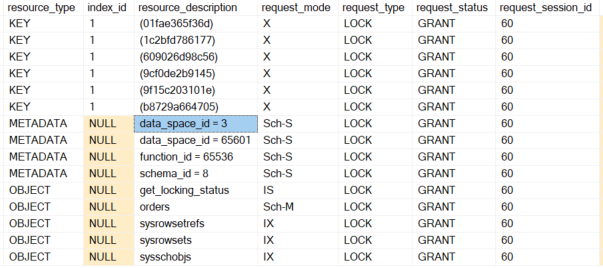
The figure shows a SCH-M lock on the dbo.orders object. This lock is a schema lock designed to prevent the object’s metadata from being manipulated by another process. You can also see the schema locks (SCH-S) on the partition function and on the partition schema. When testing the functionality, the customer did not notice any time delay.
So what is causing the long wait times and increased transaction volume? It is the next command that redefines the boundaries for the partition function. The transaction volume is NOT caused by the dbo.orders table but by the staging table switch.orders.
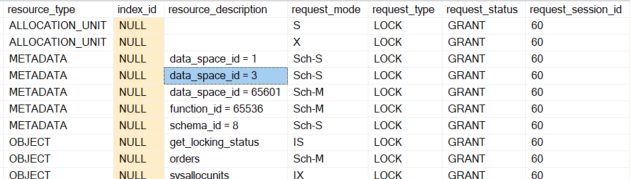
The locks on „data_space_id = 1“ and „data_space_id = 3“ are locks on the filegroups. The „schema_id = 8“ is the schema „switch“ where the staging table is located.

Moving existing data from one partition into another partition leads to an increased transaction volume, since moving the data is no longer a DDL command but the data is subject to the rules of a DML operation. The data is moved on a row basis and not on a SCHEMA basis!
The customer’s problem consisted of two miscalculations that must be considered separately:
- The same partition function was used for the staging table
- The boundaries were moved even though there was still data in the staging table.
This process is unnecessary for the customer’s process because the staging table is deleted as soon as the SWITCH is made.
Solution 1
The simplest solution was to swap the last two process steps. The MERGE of the boundaries is performed after the staging table is deleted. There is no data for 2011 left in the production table and the staging table is also gone. There is no data to move.
/* Switch out the latest partition */
ALTER TABLE dbo.orders SWITCH PARTITION 2 TO switch.orders;
/* Drop the table with the switched out data */
DROP TABLE IF EXISTS switch.orders;
/* Modify the new boundaries for the partition function */
ALTER PARTITION FUNCTION pf_o_orderdate() MERGE RANGE ('2011-01-01');
Solution 2
There are misunderstandings about the conditions that must be met for a PARTITION SWITCH. Among other things, it is often claimed that the staging table must have the same schema as the original table. But that is not correct. Rather, you just have to make sure that the staging table uses the same filegroup as the partition to be switched out.
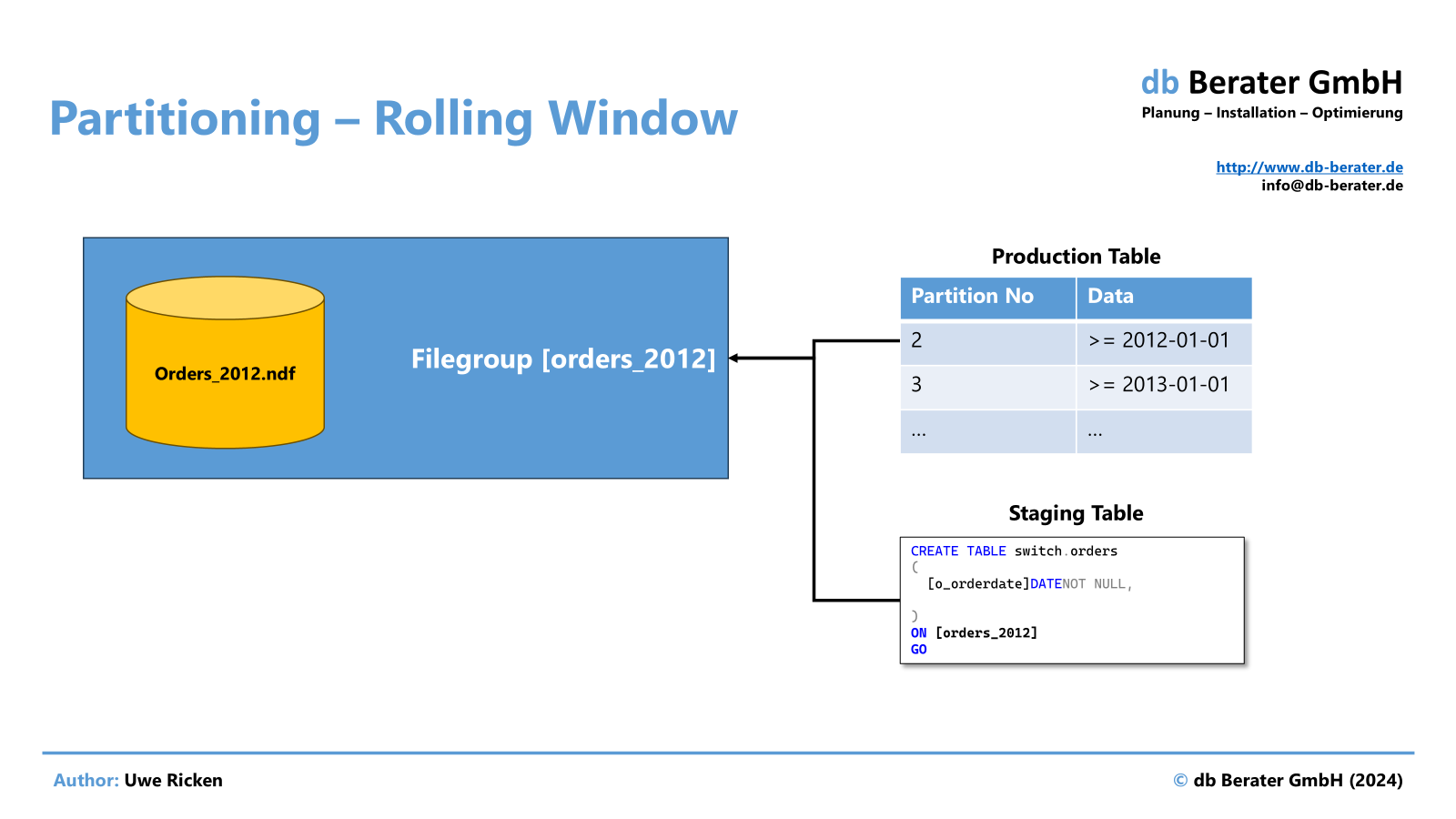
Data is moved to the staging table without being partitioned. It is sufficient that the data remains in the same file group that was assigned to it in the partitioning concept!
Solution 3
The customer’s process does not provide for the continued use of the outsourced data. Why should it end up cached that will be deleted again immediately anyway? Since Microsoft SQL Server 2016, it is possible to delete partitions using the TRUNCATE command. After we explained the approach to the customer and successfully tested it in a dev environment, the process was successfully changed.
BEGIN TRANSACTION delete_data
GO
DECLARE @partition_number INT = $PARTITION.pf_o_orderdate('2011-01-01');
TRUNCATE TABLE dbo.orders WITH (PARTITIONS(@partition_number));
/*
Now we can MERGE two partitions into ONE partition
*/
ALTER PARTITION FUNCTION pf_o_orderdate() MERGE RANGE ('2011-01-01');
COMMIT TRANSACTION delete_data;
GO
Conclusion
The SWITCH operation for partitions is a phenomenal feature if you use it in the right context. In my opinion, SWITCH functionality should always be used when data needs to be „cached“ in order to prepare/rework it before it is inserted into the production table. Typical scenarios for SWITCH operations are DWH environments. Data from third-party systems is often loaded into a staging environment to test it for plausibility or something similar, or data needs to be prepared for other reasons. Staging tables are a great tool to avoid hindering business in the production environment.
SWITCH operations are also ideal for removing inventory data from the production environment at short notice, editing it and then reinserting it into the production environment. However, SWITCH operations should not be used for a „rolling window“ concept, as the removed data no longer needs to be used.
Thank you very much for reading.




