Wer berechnete Attribute in Tabellen verwendet, sollte sich darüber im Klaren sein, dass unter bestimmten Voraussetzungen die Performance leidet. Dieser Artikel beschreibt die Nachteile, die sich aus „berechneten Attributen“ in Tabellenobjekten ergeben.
Inhaltsverzeichnis
Sachverhalt
Bei einem Kunden habe ich eine Abfrage untersucht, deren Kosten weit über dem konfigurierten Schwellwert von 50 lagen. Die Abfrage hat – trotz hoher Kosten – nicht parallelisiert. Die Ursache wurde in den Eigenschaften der Abfrage identifiziert: TSQLUserDefinedFunctionsNotParallelizable.
Bei dieser Meldung handelt es sich um eine Information, die (seit SQL Server 2022) besagt, dass eine Abfrage eine benutzerdefinierte Funktion referenziert, die nicht parallelisiert (in der Regel Skalarfunktionen). Der Hersteller der Software hat in wenigen – aber zentralen – Tabellen berechnete Spalten erstellt. Obwohl die berechneten Attribute in den untersuchten Abfragen nicht vorkommen, verhindern sie die Parallelisierung.
Demo
Mit dem nachfolgenden Skript wird eine Tabelle sowie eine Skalarfunktionfunktion erstellt. Die Tabelle verwendet 1,6 Millionen Datensätze aus meiner Beispieldatenbank ERP_Demo.
CREATE TABLE dbo.customer
(
c_custkey BIGINT NOT NULL,
c_mktsegment CHAR(10) NULL,
c_nationkey INT NULL,
c_name VARCHAR(25) NULL,
c_address VARCHAR(40) NULL,
c_phone CHAR(15) NULL,
c_acctbal MONEY NULL,
c_comment VARCHAR(118) NULL,
CONSTRAINT pk_customer PRIMARY KEY CLUSTERED (c_custkey)
);
GO
CREATE OR ALTER FUNCTION dbo.MakeItUpper
(@var AS VARCHAR(255))
RETURNS VARCHAR(255)
AS
BEGIN
DECLARE @ret_value VARCHAR(255);
SET @ret_value = UPPER(@ret_value);
RETURN @ret_value
END
GO
INSERT INTO dbo.customer WITH (TABLOCK)
SELECT * FROM ERP_Demo.dbo.customer;
GO
Die Tabelle hat keine berechnete Spalte und die Abfrage der Daten bezieht sich auf lediglich zwei Spalten der Tabelle.
SELECT c_custkey, c_name
FROM dbo.customer ORDER BY c_name;
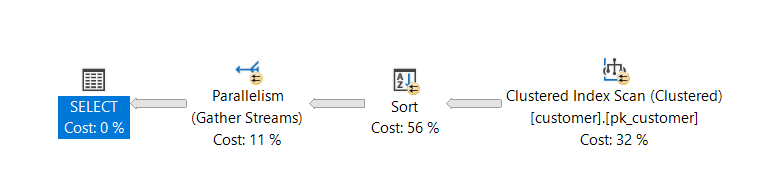
Sobald jedoch eine benutzerdefinierte Funktion als berechnetes Attribut hinzugefügt wird, kann Microsoft SQL Server keinen parallelen Plan mehr erstellen.
/* Add a computed column to the table */
ALTER TABLE dbo.customer
ADD fkt_c_name AS dbo.MakeItUpper(c_name);
GO
/* ... and execute the query again */
SELECT c_custkey, c_name
FROM dbo.customer ORDER BY c_name;
GO

Die erste Vermutung war, dass Microsoft SQL Server den geclusterten Index verwendet und somit immer die ganze Zeile lesen muss, obwohl nur zwei Attribute für die Abfrage benötigt werden. Also wurde ein nonclustered Index verwendet, um nur die Attribute zu lesen, die tatsächlich verwendet werden – leider ohne Erfolg.
CREATE UNIQUE NONCLUSTERED INDEX nix_customer_c_custkey_c_name
ON dbo.customer
(
c_custkey,
c_name
);
GO

Die Vermutung lag nahe, dass die berechnete Spalte nicht persistiert ist, da für jede Zeile die Berechnung erneut ausgeführt werden muss. Also wurde versucht, die berechnete Spalte zu persistieren.
ALTER TABLE dbo.customer
DROP COLUMN fkt_c_name;
GO
ALTER TABLE dbo.customer
ADD fkt_c_name AS dbo.MakeItUpper(c_name) PERSISTED;
GO

Die Fehlermeldung ist eindeutig und besagt, dass die Funktion „nicht-deterministisch“ ist. Das ist unlogisch, da lediglich eine Transformation eines Übergabewertes durchgeführt wird. Wird eine Funktion mit SCHEMABINDING erstellt, wird – aus Optimierungsgründen – bereits bei der Erstellung der Funktion die Überprüfung auf Determinismus geprüft.
SET ANSI_NULLS ON;
GO
/* Make the function schemabound */
CREATE OR ALTER FUNCTION dbo.MakeItUpper
(@var AS VARCHAR(255))
RETURNS VARCHAR(255)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ret_value VARCHAR(255);
SET @ret_value = UPPER(@ret_value);
RETURN @ret_value
END
GO
/* ... and it can be persisted in the table */
ALTER TABLE dbo.customer
ADD fkt_c_name AS dbo.MakeItUpper(c_name) PERSISTED;
GO
Ein erneuter Versuch, die Abfrage zu parallelisieren scheiterte jedoch aus dem gleichen Grund, wie zuvor. Auf Grund der Verwendung einer berechneten Spalte kann der Optimizer von Microsoft SQL Server keinen parallelen Plan erstellen.
Lösung
Der Grund dafür, dass keine Parallelisierung stattfindet ist, dass der Optimizer berechnete Spalten während der BIND-Phase der Normalisierung berechnet. Diese Phase wird ausgeführt, noch lange bevor eine Entscheidung für einen geeigneten Plan getroffen wird (gilt auch für triviale Pläne!). Später im Kompilierungsprozess (aber vor der Erstellung des Plans) versucht der Optimizer, Ausdrücke mit persistierten oder indizierten berechneten Spalten abzugleichen (EXPAND). Seit Microsoft SQL Server 2016 (CU2 für SQL Server 2016 SP1) gibt es ein Traceflag, das verhindert, dass eine persistierte berechnete Spalte erweitert wird.
SELECT c_custkey, c_name
FROM dbo.customer ORDER BY c_name
OPTION (QUERYTRACEON 176);
GO

Besondere Dank gilt Paul White (NZ) (t, b), der mir mit seinem Artikel ein tieferes Verständnis für dieses Problem gegeben hat:
Properly Persisted Computed Columns
Herzlichen Dank fürs Lesen!





