Ich benutze regelmäßig das berufliche Netzwerk LinkedIn, um mich mit Kollegen auszutauschen oder um innovative neue Ideen, Tipps und Tricks von geschätzten Kollegen in meinem Netzwerk zu erhalten. Viele Beiträge in meinem persönlichen Feed verweisen dann auf interessante Blogartikel, die ich – bei fachlichem Interesse – auch sehr gerne mit meinem Netzwerk teile. Seit einiger Zeit ändert sich aber die Qualität der Beiträge. Ein paar „Perlen“ werde ich in den nächsten Wochen vorstellen.
Weil man etwas veröffentlichen kann, muss man es nicht tun!
Es ist früh am Morgen und ich schaue in meinen Newsfeed auf LinkedIn, während ich gemütlich einen Kaffee trinke und mich auf den Arbeitstag vorbereite. Mit Interesse lese ich vor allen Dingen Informationen über „mein“ Lieblingsthema und bei manchen Posts ist mir fast die Kaffeetasse aus der Hand gefallen, weil es nur so von fachlichen Fehlern im Artikel strotzte.
Ich bewundere, mit welchem Selbstbewusstsein manche Autoren ihre Postings bei völliger Ahnungslosigkeit in ihrem Netzwerk teilen und auch gerne noch auf ihre – themenbezogenen – Dienstleistungen hinweisen. Gerne schmunzelt man über die Ergüsse – aber man wundert sich doch über zahlreiche „Likes“ und Kommentare wie „Great – thank you for sharing!“, … Vielleicht liege ich falsch aber ich merke, dass diese Art von Artikeln in meinem beruflichen Netzwerk zunehmen. Getoppt werden sie von wirklich haarsträubenden AI-generierten Artikeln, die ich in anderen Blogartikeln verarbeiten werde. Ich werde zukünftig solche Posts zum Anlass nehmen, um darüber zu schreiben und die Aussagen der Autoren – durch Demos belegt – widerlegen.
Hinweis
- Aus Rücksicht auf den/die Autoren eines von mir gefundenen Postings werde ich Textauszüge als Abbildungen zeigen.
- Ich werde nicht auf den Originalpost verlinken!
- Ein tiefes Verständnis von temporären Objekten (temporäre Tabelle / Tabellenvariable) ist für diesen Artikel erforderlich.
Inhaltsverzeichnis
Was Tabellenvariablen so alles können – oder auch nicht
Der Autor stellte technische Unterschiede zwischen Temporären Tabellen und Tabellenvariablen in seinem Post gegenüber. Teilweise sind die Aussagen technisch falsch; teilweise wurde die Gegenüberstellung missverständlich beschrieben. Ich gehe nur auf die technisch falschen Aussagen ein.
Indexe und Statistiken
Fangen wir mit der ersten technischen Aussage an, die so nicht zutreffend ist.

Mit diesem Statement wird behauptet, dass Tabellenvariablen keine Indexe verwenden können und Statistiken automatisch erzeugt werden. Beide Aussagen sind nicht richtig.
table_type_definition ::=
TABLE ( { <column_definition> | <table_constraint> } [ , ...n ] )
<column_definition> ::=
column_name scalar_data_type
[ COLLATE <collation_definition> ]
[ [ DEFAULT constant_expression ] | IDENTITY [ ( seed , increment ) ] ]
[ ROWGUIDCOL ]
[ column_constraint ] [ ...n ]
<column_constraint> ::=
{ [ NULL | NOT NULL ]
| [ PRIMARY KEY | UNIQUE ]
| CHECK ( logical_expression )
}
<table_constraint> ::=
{ { PRIMARY KEY | UNIQUE } ( column_name [ , ...n ] )
| CHECK ( logical_expression )
}
https://learn.microsoft.com/en-us/sql/t-sql/data-types/table-transact-sql
Selbstverständlich können Tabellenvariablen Indexe verwenden. Es gibt aber eine Besonderheit bei der Erstellung von Indexen – sie können nur während der Erstellung/Deklaration einer Tabellenvariable implementiert werden. Nachträglich Indexe können nicht implementiert werden!
/* This way of implementation of an index works */
DECLARE @T TABLE
(
Id INT NOT NULL PRIMARY KEY CLUSTERED,
C1 DATE NOT NULL
,INDEX x1 NONCLUSTERED (C1)
);
Versucht man, einen Index NACH der Definition der Tabellenvariable zu implementieren, wird die Aktion mit einem Fehler beendet.
/* This way of implementation will never work */
DECLARE @T TABLE
(
Id INT NOT NULL PRIMARY KEY CLUSTERED,
C1 DATE NOT NULL
,INDEX x1 NONCLUSTERED (C1)
);
CREATE NONCLUSTERED INDEX x2 ON @T (C1);
Msg 102, Level 15, State 1, Line 23
Incorrect syntax near ‚@T‘.
Statistiken wurden – und werden aktuell – für Tabellenvariablen NICHT unterstützt! Das war in der Vergangenheit ein großes Problem bei der Verwendung von Tabellenvariablen. Bis einschließlich Microsoft SQL Server 2017 belief sich die Schätzung der auszugebenden Datensätze immer auf „1“ Datensatz.

Dieses Problem konnte man vor der Version SQL Server 2019 nur durch „RECOMPILE“, Traceflag 2453 oder mit Hilfe von Plan Guides lösen. Mit der Version Microsoft SQL Server 2019 änderte sich das Verhalten durch „Deferred Compilation„. Dazu ist es aber erforderlich, dass die Datenbank mindestens im Kompatibilitätsmodus 150 (SQL Server 2019) betrieben wird.


Wenn sich auch mit Microsoft SQL Server eine Verbesserung bei der Behandlung von Tabellenvariablen ergeben hat – es ändert nichts an der Tatsache, dass auch mit Stand „Microsoft SQL Server 2022“ keine Statistiken für Tabellenvariablen vorhanden sind.
Tabellenvariablen und Transaction Log

Ich verstehe die Aussage wie folgt:
- Aktivitäten für Temporäre Tabellen werden im Transaktionslog (von TEMPDB?) protokolliert.
- Daraus ergibt sich, dass diese Möglichkeit bei Tabellenvariablen nicht gültig ist.
- Der Nachsatz scheint meine Vermutung zu bestätigen.
Bei diesem Textauszug verwechselt der Autor – vermutlich – das unterschiedliche Verhalten von Temporären Tabellen und Tabellenvariablen IN einer Transaktion. Änderungen in Temporäre Tabellen werden transaktional abgesichert (UNDO!) während es ein UNDO für Tabellenvariablen nicht gibt.
DECLARE @T TABLE
(
Id INT NOT NULL PRIMARY KEY CLUSTERED,
C1 DATE NOT NULL
);
INSERT INTO @T (Id, C1)
SELECT *
FROM (
VALUES
(1, '1900-01-01'),
(2, '2022-02-04')
) AS x (Id, C1)
SELECT * FROM @T ORDER BY Id;
BEGIN TRANSACTION
UPDATE @T
SET C1 = CAST(GETDATE() AS DATE)
WHERE Id = 1;
ROLLBACK TRANSACTION
SELECT * FROM @T ORDER BY Id;
GO
Der Versuchsaufbau ist trivial:
- Es wird eine Tabellenvariable definiert
- Zwei Datensätze mit unterschiedlichen Datumsangaben werden eingetragen
- Innerhalb einer Transaktion wird der erste Datensatz auf das aktuelle Datum geändert
- Die Transaktion wird mit einem ROLLBACK beendet
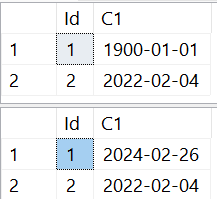
Nehmen wir an, die Aussage des Autors bezieht sich wirklich auf das Transaktion Log. In diesem Fall irrt der Autor. Selbstverständlich werden Aktivitäten einer Tabellenvariablen im Transaktionsprotokoll von TEMPDB protokolliert. Entgegen einem immer noch relativ weit verbreiteten Irrglaube, dass Tabellenvariablen ausschließlich In Memory existieren ist es so, dass Tabellenvariablen beim Speichern der Datensätze TEMPDB verwenden.
/* Create a table variable */
DECLARE @T TABLE
(
o_orderkey BIGINT NOT NULL PRIMARY KEY CLUSTERED,
o_orderdate DATE NOT NULL
);
/* ... and insert 10 rows into it */
INSERT INTO @T (o_orderkey, o_orderdate)
SELECT TOP (10)
o_orderkey,
o_orderdate
FROM ERP_Demo.dbo.orders;
/* Now we can check the transaction log entries */
SELECT Operation,
Context,
AllocUnitName,
[Log Record Length],
[RowLog Contents 0]
FROM sys.fn_dblog(NULL, NULL)
WHERE Context = N'LCX_CLUSTERED'
AND AllocUnitId IN
(
SELECT a.allocation_unit_id
FROM tempdb.sys.partitions AS p
INNER JOIN tempdb.sys.system_internals_allocation_units AS a
ON p.hobt_id = a.container_id
INNER JOIN tempdb.sys.tables AS t
ON t.object_id = p.object_id
INNER JOIN tempdb.sys.columns AS c
ON c.object_id = p.object_id
WHERE c.name IN (N'o_orderkey', N'o_orderdate')
);
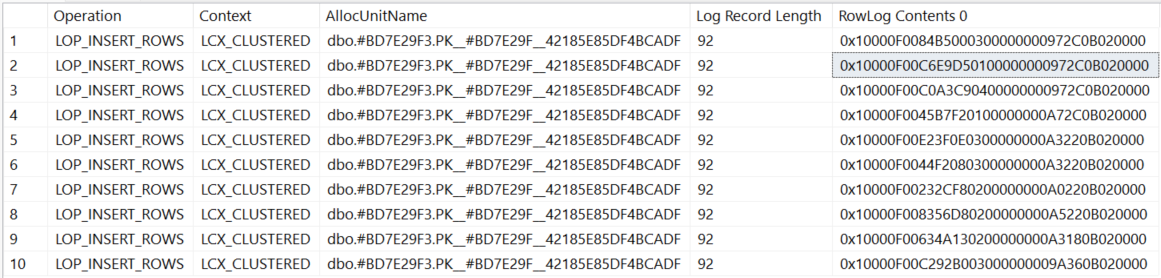
Die Demo zeigt, dass Tabellenvariablen das Transaktionsprotokoll verwenden. Warum sollte es auch einen Unterschied machen, wenn doch Temporäre Tabellen und Tabellenvariablen bei der technischen Implementierung identisch sind?
Ergebnis
Der Post war nicht sehr lang und von den 4 – 5 Unterschieden, die genannt wurden, waren gerade mal zwei Aussagen zutreffend. Keine Frage, wir alle machen Fehler. Vor nicht all zu langer Zeit habe ich solche Postings einfach weiter gescrollt; aber während die Quantität stark zunimmt, nimmt die Qualität immer weiter ab. Solche Postings sind nicht nur für den Autor „schädlich“ – leidet doch seine Reputation darunter. Auch die Adressaten sind nicht gut bedient, solche Postings mit weitergehender Aufmerksamkeit durch „Likes“ oder Kommentare zu puschen. Es zeigt, dass entweder das Thema ebenfalls nicht verstanden wird oder aber – davongehe ich aus – ohne weiter darüber nachzudenken, geliked wird, um dem „Buddy“ einen Gefallen zu tun.
Der Autor hat – aus meiner Sicht – zwei Fehler gemacht:
- Das von ihm gewählte Thema ist sehr komplex und lässt sich nicht mit einem Posting, das auf wenige Zeichen beschränkt ist und keine Möglichkeit der Formatierung für ein besseres Leseerlebnis bietet, auf wenige Zeilen reduzieren.
- Gleichwohl ist es für die eigene Reputation wichtig, dass man gründlich recherchiert und Demos durchführt, um Aussagen zu untermauern und sich dadurch fachlich tiefer in eine komplexe Materie einarbeitet.

Die Intention des Autors scheint offensichtlich. Mehr Follower, um mehr Reichweite zu erlangen und dadurch – möglicherweise – einen attraktiven Job oder einfach nur Aufmerksamkeit zu erlangen. Meine Meinung dazu: LinkedIn sollte nicht zu TikTok mutieren. Qualität sollte immer vor Quantität gehen.
Herzlichen Dank fürs Lesen!





