Ich hatte heute einen Kundentermin, in dem die Vorteile von „functional Indexes“, wie sie ORACLE oder POSTGRES kennen, hervorgehoben wurden. Leider kennt Microsoft SQL Server diese Art von Indexen nicht. Dennoch ist es auch mit Microsoft SQL Server möglich, die Funktion eines „functional Index“ mit ein paar Einschränkungen zu implementieren
Inhaltsverzeichnis
Was ist ein „functional Index“
Ein funktionaler Index basiert auf der Idee, dass Abfragen, deren Prädikate mit Hilfe von Funktionen transformiert werden, dennoch einen performanten INDEX SEEK verwenden können, statt mit einem INDEX SCAN alle Werte des Attributs zunächst zu transformieren, um sie anschließend mit einem Prädikat zu vergleichen.
Beispiel
Gegeben ist eine Tabelle mit ca. 1,6 Millionen Datensätzen aus ERP_DEMO_DB (diese Datenbank kann hier heruntergeladen werden). Auf dem Attribut [c_address] liegt ein nonclustered Index mit der folgenden Definition:
CREATE NONCLUSTERED INDEX nix_Customer_c_address
ON dbo.Customer (c_address);
GO
Wird eine Abfrage ausgeführt, die nach einem Wert in c_address sucht, führt es zu einem INDEX SEEK im Index [nix_Customer_c_address, da das Attribut ohne Transformationen verwendet werden kann.
SELECT * FROM dbo.Customer
WHERE c_address = 'cdejJxup1PgpD17129,8MZh';
GO

Die obige Abfrage ist „SARGable„, da der zu suchende Wert unmittelbar im Index gefundenwerden kann. Einige Programmierer verwenden jedoch in ihren Suchmustern Funktionen, um sicherzustellen, dass die eingegebenen Suchmuster immer das gleiche Format haben. Die nachfolgende Abfrage ist ein typisches Beispiel dafür:
SELECT * FROM dbo.Customer
WHERE UPPER(c_address) = 'CDEJJXUP1PGPD17129,8MZH';
GO
Das Beispiel verwendet eine Funktion, um das Attribut in Großbuchstaben zu transformieren. Somit kann mit Hilfe der Applikation der Suchbegriff immer in Großbuchstaben übergeben werden und eine Suche in der Tabelle kann unabhängig von der konfigurierten Collation durchgeführt werden. Jedoch hat diese Variante einen entscheidenden Nachteil – sie ist nicht mehr „SARGable„!
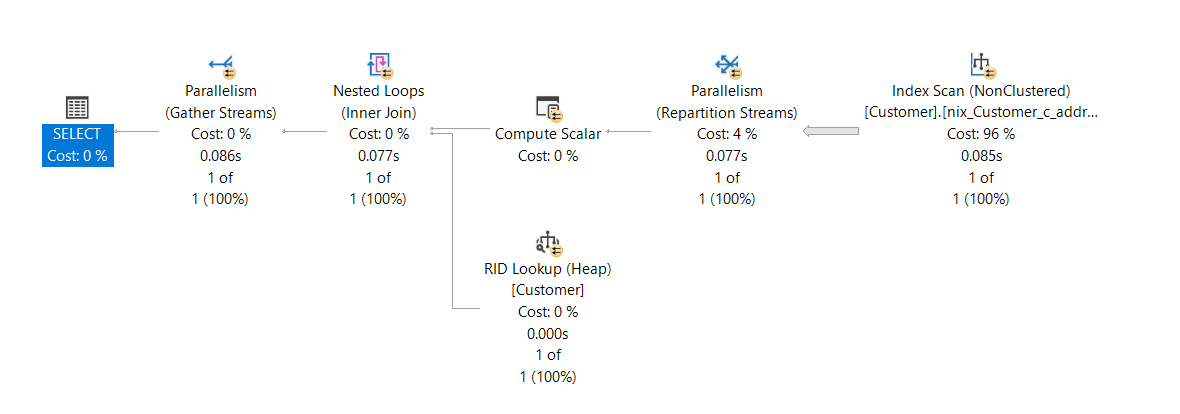
Statt eines performanten INDEX SEEK wird mit Hilfe eines INDEX SCAN werden alle Werte im Index – bedingt durch UPPER() – in Großbuchstaben konvertiert und anschließend kann der gewünschte Suchwert ermittelt werden.
Für Entwickler, die mit ORACLE, POSTRGRES, … als Backend arbeiten, ist dieses Problem keine Herausforderung, da für solche Fälle ein „functional Index“ verwendet werden kann. Ein „functional Index“ arbeitet prinzipiell, wie jeder andere Index auch; jedoch kann er Funktionen bei der Erstellung verwenden. Bei ORACLE würde ein solcher Index wie folgt implementiert werden:
/* Be aware - this is ORACLE */
CREATE INDEX nix_Customer_c_address
ON dbo.Customer (UPPER(c_address));
GO
Leider ist diese Technik in Microsoft SQL Server bis heute nicht implementierbar. Jeder Datenbankentwickler möge selbst entscheiden, ob es eine gute oder eine schlechte Entscheidung von Microsoft ist.
Alternative in Microsoft SQL Server
Obwohl Microsoft SQL Server „functional Indexes“ nicht kennt, gibt es eine Möglichkeit, diese Technik über einen kleinen Umweg zu implementieren. Der Trick besteht darin, der Tabelle ein berechnetes Attribut hinzuzufügen, dass für jede Datenzeile den Wert ermittelt, der sich aus der Berechnung durch die Funktion ergibt. Dieses Attribut wird anschließend indexiert.
Berechnetes Attribut…
Seit Microsoft SQL Server 2005 gibt es die Technologie der „Computed Columns“. Informationen über die Funktionsweise kann man hier nachlesen. Da Indexierung nur auf bestehende Attribute einer Relation angewendet werden kann, behilft man sich mit dieser Technologie, die – ohne die Ergebnisse der Berechnung zu speichern – wie folgt angewendet wird:
/* Erstellen einer berechneten Spalte */
ALTER TABLE dbo.Customer
ADD UpperAddress AS UPPER(c_address);
GO

indexieren!
Für Microsoft SQL Server ist es unerheblich, ob ein Attribut einer Relation berechnet oder persistent ist. Entscheidend ist, dass ein zu indexierendes Attribut vorhanden sein muss. Sobald das berechnete Attribut erstellt wurde, kann es ohne Probleme indexiert werden, sofern das Ergebnis der Kalkulation deterministisch ist. Einschränkungen bei der Indexierung von „computed columns“ finden sich hier.
/* Indexierung der berechneten Spalte */
CREATE NONCLUSTERED INDEX nix_Customer_UpperAddress
ON dbo.Customer (UpperAddress);
GO
Sobald der Index implementiert ist, verhält sich die Beispielabfrage – OHNE Änderung der Syntax – wie folgt:
SELECT * FROM dbo.Customer
WHERE UPPER(c_address) = 'CDEJJXUP1PGPD17129,8MZH';
GO
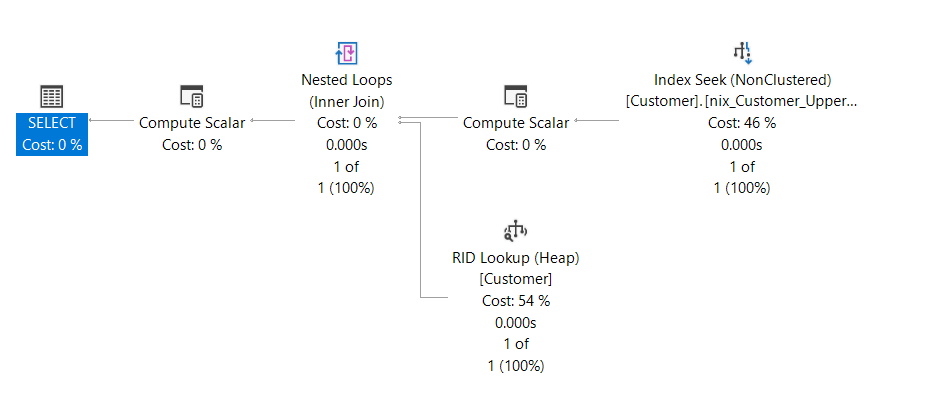
Der Query Optimizer von Microsoft SQL Server ist so smart, dass er erkennt, dass es für die Definition des Prädikats einen Index auf einer entsprechenden Transformation (berechnetes Attribut) in der Relation gibt. Aus diesem Grund kann die Abfrage diesen Index verwenden und die Daten werden wieder mit Hilfe eines INDEX SEEK gesucht.
Probleme dieser Lösung
Leider kann diese Lösung nicht immer implementiert werden. Das kann viele Gründe haben.
- Die Software ist von einem Hersteller, der Anpassungen an Relationen nicht gestattet
- Es sind Workloads vorhanden, die – LEIDER – beim Eintragen von Daten in die Relation eine bestimmte Struktur voraussetzen
- Applikationen verwenden * als Auswahlkriterium für die Attribute einer Relation
- …
Mit einem kleinen Trick kann man diese Reglementierungen (bis auf Punkt 1) geschickt umgehen, indem man die Relation umbenennt und eine View mit dem Namen der Relation erstellt.
/* Umbenennen der Relation */
EXEC sp_rename
@objname = N'dbo.Customer',
@newname = N'CustomerNew',
@objtype = 'OBJECT';
GO
/* Erstellen einer View mit Namen der Tabelle */
CREATE OR ALTER VIEW dbo.Customer
AS
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment
FROM dbo.CustomerNew;
GO
Herzlichen Dank fürs Lesen!





