Berichte, Analysen, PowerBI-Dashboards… – es gibt so gut wie keinen Anwendungsbereich, der nicht regelmäßig Aggregationen über Zeitintervalle benötigt. Es ist dabei unerheblich, ob es nur das reine Zählen von Datenreihen oder aber die Suche nach dem kleinsten Wert, größten Wert oder Durchschnittswert geht. Allen Anforderungen geht voraus, dass eine Aggregation von Werten über eine vordefinierte Gruppe gebildet wird. Problematisch wird es jedoch, wenn ein Serversystem mit wenigen Ressourcen zur Verfügung steht oder aber das Datenvolumen sehr groß ist.
Inhaltsverzeichnis
Problemstellung
Für diesen Artikel verwende ich eine typische Abfrage, wie ich sie häufig bei Reports, Exporten, … sehe. Es soll – vereinfacht für diesen Artikel – ein Rowset gebildet werden, dass pro Jahr und pro Monat die Anzahl aller Bestellungen ermitteln soll. Für die Beschreibung der Problematik verwende ich meine Schulungsdatenbank ERP_DEMO (Version SQL Server 2012). Die verwendete Tabelle dbo.orders beinhaltet 60 Mio Datensätze.
Hinweis
In diesem Artikel wird ein besonderes Augenmerk auf die Probleme in der Execution Phase der Abfrage gelenkt. Die verwendeten Operatoren (z. B. HASH MATCH, STREAM AGGREGATE) sind teilweise sehr komplex und würden das Thema dieses Artikels verfehlen und auf Grund der Komplexität sicherlich auch sprengen. Ein sehr geschätzter Kollege und Freund aus den Niederlanden hat sich die Mühe gemacht, für fast alle Operatoren eine beeindruckende Referenz zu erstellen. Hugo Kornelis‘ (B / X) Artikel sind ein Fundus an interessanten Aspekten, die mit jedem Operator einher gehen.
In diesem Artikel werde ich auf die Problematiken der verwendeten Operatoren eingehen; wer mehr über die Operatoren wissen möchte, kann sich bei meinem Freund Hugo schlau machen :).
Beispielabfrage
SELECT YEAR(o_orderdate) AS year_of_order,
MONTH(o_orderdate) AS month_of_order,
COUNT_BIG(*) AS nun_of_rows
FROM dbo.orders
GROUP BY
YEAR(o_orderdate),
MONTH(o_orderdate)
OPTION (MAXDOP 1);
Hinweis
Die obige Abfrage wird uns für den weiteren Verlauf in diesem Artikel begleiten, um die Probleme sowie die möglichen Optimierungsschritte zu beschreiben. Die Option „MAXDOP 1“ wird verwendet, um die Ausführungspläne einfacher darzustellen und auf die wesentlichen Probleme zu fokussieren. Durch die Option MAXDOP 1 wird die Parallelisierung (und die damit verbundenen Operatoren im Ausführungsplan) unterdrückt.
Die Beispielabfrage ermittelt für jedes Jahr und jeden Monat die Anzahl aller Bestellungen mit Hilfe der COUNT_BIG()-Funktion.
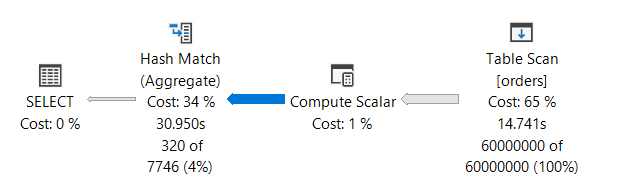
Zunächst werden die 60 Mio. Datensätze gelesen (TABLE SCAN), um anschließend das Jahr und den Monat zu extrahieren (Compute Scalar). Sobald die Berechnung abgeschlossen ist, wird die eigentliche Aggregation mit Hilfe eines HASH MATCH Operators durchgeführt. Dieser Operator ist sehr kostspielig und – ein besonderes Merkmal – ein sogenannter STOP-Operator. Ein STOP-Operator muss zunächst alle Daten aus dem Input-Stream speichern und verarbeiten. Sobald der letzte Datensatz aus dem Input-Stream verarbeitet ist, können die verarbeiteten Daten zum nächsten Operator weitergeleitet werden. Das Problem von STOP-Operatoren ist, dass sie für die Zwischenspeicherung Memory benötigen. Ist nicht ausreichend Memory vorhanden, werden die Daten in TEMPDB ausgelagert und das geht bekanntlich mit Performanceeinbußen einher. Microsoft SQL Server verwendet STOP-Operatoren, wenn es keine Garantie dafür gibt, dass der Datenstrom sortiert ist. Ein typischer STOP-Operator ist der SORT-Operator, der zunächst die ungeordneten Daten zwischenspeichert und anschließend sortiert zum nächsten Operator weiter reicht.

Kann Indexierung helfen?
Eines der Ziele bei der Verwendung von Indexen besteht darin, – neben dem schnellen Auffinden von Schlüsselwerten – teure Sortierungen zu vermeiden. Wird ein Index erstellt, so liegen die Attribute automatisch sortiert vor. Ein Lösungsansatz könnte es also sein, für das Attribut [o_orderdate] einen Index zu definieren, der gleich zwei Vorteile mit sich bringt:
- Das Datenvolumen für die Verarbeitung nimmt ab
- Daten liegen sortiert vor
/* Nonclustered index which sort the o_orderdate column */
CREATE NONCLUSTERED INDEX nix_orders_o_orderdate
ON dbo.orders (o_orderdate);
GO
Eine erneute Ausführung der Abfrage zeigt, dass Microsoft SQL Server zwar den Index verwendet aber der teure HASH MATCH Operator weiterhin verwendet wird.
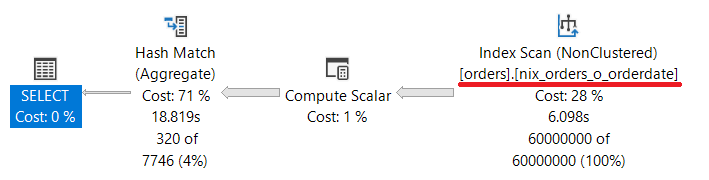
Der Grund liegt in der Transformation des Index-Attributs [o_orderdate]. Durch die Transformation (aus dem Datum wird ein INTEGER) verändert sich sowohl der Datentyp als auch der Wert des ursprünglichen Indexattributs. Der Query Optimizer von Microsoft SQL Server kann aus der Transformation nicht ableiten, dass diese Informationen aus dem Index stammen, der die Daten in sortierter Form vorhält.
Optional kann man den Query Optimizer dazu zwingen, ein sortiertes gruppiertes Rowset auszugeben. Mit allen daraus resultierenden Nachteilen.
/* force a STREAM AGGREGATION by using ORDERED GROUPS */
SELECT YEAR(o_orderdate) AS year_of_order,
MONTH(o_orderdate) AS month_of_order,
COUNT_BIG(*) AS num_of_rows
FROM dbo.orders
GROUP BY
YEAR(o_orderdate),
MONTH(o_orderdate)
OPTION (MAXDOP 1, ORDER GROUP);
GO
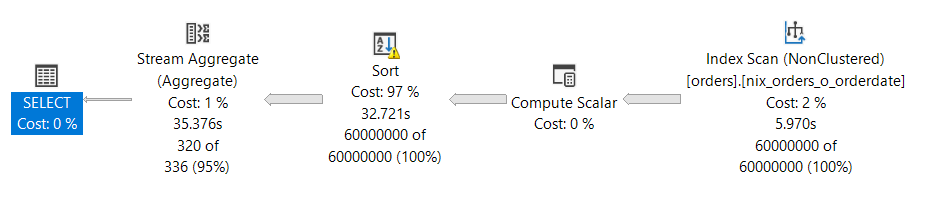
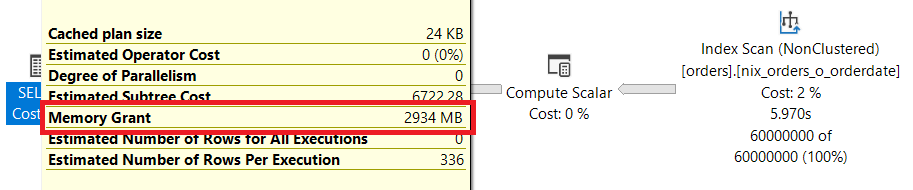
Aus einem HASH MATCH wird ein – gewollter – STREAM AGGREGATE Operator, der aber voraussetzt, dass der Datenstrom sortiert geliefert wird. Damit eine Sortierung gewährleistet werden kann, muss Microsoft SQL Server mit Hilfe eines SORT-Operators die Daten sortiert weiterleiten. Diesen „Dienst“ müssen wir teuer bezahlen, da der SORT-Operator sehr viel Memory benötigt und nicht skalieren kann!
Lösungen
Prinzipiell wäre das Problem recht einfach zu lösen. Darüber habe ich bereits im Artikel „Functional Indexes in Microsoft SQL Server“ geschrieben. Damit eine Transformation nicht mehr stattfindet, muss das Ergebnis einer Funktion materialisiert sein. Die Materialisierung erfolgt mit Hilfe eines Indexes oder einer View (sofern es nicht möglich ist, Schemaänderungen vorzunehmen).
Verwendung von indexierten funktionalen Attributen
Die Verwendung von indexierten funktionalen Attributen transformiert die Ausgabewerte bereits auf Metadaten-Ebene. Wenn ein Index auf die beiden transformierten Werte gelegt wird, kann Microsoft SQL Server den Index für die Ausführung verwenden und der teure HASH AGG-Operator wird vermieden. Leider kennt Microsoft SQL Server keine „funktionalen Indexe“ und man ist gezwungen, einen Workaround anwenden. Dieser Workaround sieht vor, dass für die transformierten Werte berechnete Attribute zur Tabelle hinzugefügt werden, die indexiert werden.
/* creation of calculated attributes */
ALTER TABLE dbo.orders
ADD order_year AS YEAR(o_orderdate),
order_month AS MONTH(o_orderdate);
GO
/* a nonclustered index covers both attributes */
CREATE NONCLUSTERED INDEX order_date_part
ON dbo.orders
(
order_year,
order_month
)
WITH (DATA_COMPRESSION = PAGE);
GO
/* and the optimizer recognize it as a valid option */
SELECT YEAR(o_orderdate) AS year_of_order,
MONTH(o_orderdate) AS month_of_order,
COUNT_BIG(*) AS nun_of_rows
FROM dbo.orders
GROUP BY
YEAR(o_orderdate),
MONTH(o_orderdate)
OPTION (MAXDOP 1);
GO

Verwendung einer indexierten View
Stößt man auf die gezeigten Probleme in einer Datenbank, die von einem Software-Vendor ist, kann es sein, dass das Hinzufügen von zusätzlichen Attributen durch den Hersteller untersagt wird. Das macht Sinn, da für den DBA nicht immer erkennbar ist, inwieweit die bestehende Struktur für den Applikationscode bindend ist. Alternativ zur oben gezeigten Lösung lässt sich aber mit Hilfe einer indexierten View das Problem lösen die bereits die Aggregationen beinhaltet. Diese Lösung ist jedoch einer Enterprise-Edition von Microsoft SQL Server vorbehalten, die es dem Query Optimizer erlaubt, statt der Originalabfrage die stark komprimierten Daten der Indexed View zu verwenden.
/* Create a view - SCHEMABINDING - for preparation of an index */
CREATE OR ALTER VIEW dbo.view_orders
WITH SCHEMABINDING
AS
SELECT YEAR(o_orderdate) AS order_year,
MONTH(o_orderdate) AS order_month,
COUNT_BIG(*) AS order_count
FROM dbo.orders
GROUP BY
YEAR(o_orderdate),
MONTH(o_orderdate);
GO
/* Create a unique clustered index on that view */
CREATE UNIQUE CLUSTERED INDEX view_order_o_orderkey
ON dbo.view_orders
(
order_year,
order_month
)
WITH (DATA_COMPRESSION = PAGE);
GO
Wird nun die Abfrage ausgeführt (Enterprise Edition!) so verwendet Microsoft SQL Server die indexierte View.
SELECT YEAR(o_orderdate) AS year_of_order,
MONTH(o_orderdate) AS month_of_order,
COUNT_BIG(*) AS nun_of_rows
FROM dbo.orders
GROUP BY
YEAR(o_orderdate),
MONTH(o_orderdate)
OPTION (MAXDOP 1, RECOMPILE);
GO
Neue Möglichkeiten mit SQL Server 2022
Mit Microsoft SQL Server 2022 wurden neue Funktionen implementiert, die für Time Series-Funktionalitäten optimiert wurden. Time Series Databases (TSDBs) sind spezialisierte Datenbanken, die darauf ausgerichtet sind, Zeitreihendaten effizient zu speichern, abzurufen und zu verarbeiten. Zeitreihendaten sind Datenpunkte, die mit einem bestimmten Zeitstempel versehen sind und in zeitlicher Reihenfolge angeordnet sind. Diese Datenbanken sind besonders nützlich für Anwendungen, bei denen die zeitliche Dimension der Daten von entscheidender Bedeutung ist, wie beispielsweise in der Überwachung von Systemen, Finanzanalysen, industriellen Prozesssteuerungen und Internet of Things (IoT)-Anwendungen.
Microsoft hat für eine effizientere Abfrage solcher Daten neue Funktionen in SQL Server 2022 implementiert. Diese Funktionen haben – neben der Funktionalität für Time Series – noch einen anderen Vorteil, der unserer Problemstellung eine große Hilfe ist.
DATE_BUCKET()
Die Funktion DATE_BUCKET() gibt einen DATETIME-Wert zurück, der dem Beginn jedes Datetime-Buckets entspricht.
SELECT TOP (100)
o_orderdate,
DATE_BUCKET(MONTH, 1, o_orderdate) AS date_bucket
FROM dbo.orders
ORDER BY
NEWID();
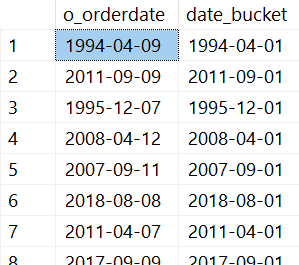
Man kann am Output erkennen, dass Microsoft SQL Server alle Ausgaben, die mit DATE_BUCKET() erzeugt wurden, mit dem 1. Tag eines Monats berechnet. Die Funktion bildet für jedes Datum einen „Bucket“, in dem alle Bestellungen für den Monat eines Jahres getätigt wurden. Somit wird für diese Bestellungen ein einheitlicher Datumswert generiert, in den alle betroffenen Bestellungen passen.
Ändern wir unsere Abfrage so um, dass sie die neue Funktion verwendet, ändert sich die Strategie des Query Optimizers signifikant!
SELECT YEAR(DATE_BUCKET(MONTH, 1, o_orderdate)) AS year_of_order,
MONTH(DATE_BUCKET(MONTH, 1, o_orderdate)) AS month_of_order,
COUNT_BIG(*) AS nun_of_rows
FROM dbo.orders
GROUP BY
DATE_BUCKET(MONTH, 1, o_orderdate)
OPTION (MAXDOP 1, RECOMPILE);
GO

Man kann sehr gut erkennen, dass der Query Optimizer nun den Index, der für das Attribut [o_orderdate] angelegt wurde, berücksichtigt. Das führt dazu, dass ein ressourcenhungriger HASH AGG Operator vermieden werden kann und statt dessen ein STREAM AGG Operator verwendet wird. Obwohl der Operator als „Flow Operator“ keinen Speicher für die Zwischenspeicherung von Daten benötigt, wird die Abfrage nicht wesentlich schneller ausgeführt; sie benötigt aber weniger Ressourcen.
DATETRUNC()
Die Funktion DATETRUNC() wird verwendet, um ein Datum, eine Uhrzeit oder einen Zeitstempel in SQL Server auf ein bestimmtes Intervall, z. B. den Tag, die Woche oder den Monat, zu kürzen. Die Funktion DATETRUNC() ist besonders nützlich für die Zeitreihenanalyse, um zu verstehen, wie sich ein Wert im Laufe der Zeit ändert. Zu den praktischen Beispielen gehören die Analyse der vierteljährlichen Umsätze des Unternehmens oder die Bestimmung der durchschnittlichen Stundentemperatur.
DATETRUNC() verhält sich identisch zu DATE_BUCKET(). Der einzige Unterschied zwischen beiden Funktionen besteht darin, dass bei DATE_BUCKET() als 4. Parameter einen Ursprungswert verwenden kann, ab dem eine Berechnung der Buckets durchgeführt wird. Ansonsten verhalten sich beide Funktionen gleich!
Herzlichen Dank fürs Lesen!





