Ein Kunde betreibt eine Applikation, in der Messdaten in einer Tabelle gespeichert werden. Leider haben die Entwickler die Grundlagen der Normalformenlehre nicht beachtet und so kam es wie es kommen musste. Gewünschte Auswertungen des Kunden konnten nicht effizient erstellt werden. Wir haben die Abfrage(n) umgeschrieben und mit Hilfe von APPLY die Effizienz massiv steigern können.
Inhaltsverzeichnis
Problemstellung
In einem Gebäude sind auf jeder Etage mehrere Sensoren installiert, die Temperaturen, Luftfeuchtigkeit, etc. messen. Diese Sensoren senden in festen Abständen Informationen an einen Webservice, der die Daten anschließend in einer Tabelle auf dem SQL Server speichert. Leider wurde bei der Erstellung des Datenmodells keine Rücksicht auf die Normalformen genommen.
Die Tabelle speichert für einen Zeitpunkt x für jede Etage für jeden Sensor den gemessenen Wert in einem eigenen Attribut!
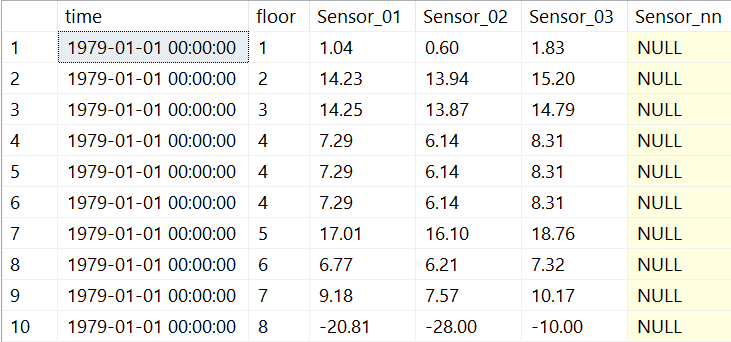
Wenn ein neuer Sensor installiert wird, wird der Tabelle einfach ein neues Attribut hinzugefügt. Das dieses Layout nicht effizient ist, wird sicherlich sofort klar. Die Tabelle besitzt einen geclusterten Index auf den Attributen [time] und [floor]. Ansonsten werden keine weiteren Indexe verwendet, um INSERT-Statements nicht unnötig zu verzögern. In der Tabelle [dbo].[temperature_measures] sind 3,8 Millionen Datensätze gespeichert!
Die Beispieldatenbank kann hier heruntergeladen werden (SQL Server 2019 erforderlich)
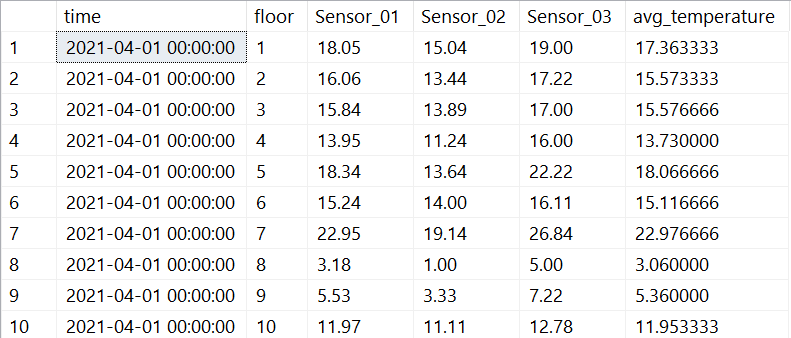
Für einen Report möchte der Kunde zu jedem Zeitpunkt und für jede Etage eine Durchschnittstemperatur anzeigen. Für Microsoft EXCEL wäre das kein Problem – für ein RDBMS-System jedoch schon, da die typische Aggregation von Werten über Datenzeilen – und nicht über Attribute eines Datensatzes – ausgeführt werden.
Lösungen
Dieser Artikel zeigt, wie das oben beschriebene Problem gelöst werden kann. Hierbei spielt die Performance sowie die verwendeten Ressourcen zur Ausführung der Abfrage eine zentrale Rolle. Für diesen Artikel wurde die Tabelle sehr stark vereinfacht (die Tabelle des Kunden hat über 200! Attribute für die Speicherung von Messdaten). Für die Anforderung sollen folgende Parameter gelten
- Für das Beispiel in diesem Artikel gibt es maximal 3 Sensoren pro Etage.
- Es soll die Durchschnittstemperatur pro Zeitpunkt und Etage ermittelt werden.
- Der Zeitraum für die Evaluation der Daten wird vom 01.04.2021 bis 31.04.2021 festgelegt.
UNION Operator
Der Kunden löste das Problems unter Verwendung des UNION Operators. Der UNION Operator verkettet mehrere Datasets zu einem zusammenhängenden Dataset. Es wurde für jeden Messpunkt (Attribut der Tabelle) eine separate Abfrage erstellt, die mit UNION ALL zu einem Ergebnis zusammengeführt werden konnten.
/* Evaluierung der Daten für jeden Sensor*/
;WITH measures
AS
(
/* 1. Sensor */
SELECT [time], [floor], 1 AS [Sensor],
[Sensor_01] AS [temperature]
FROM dbo.temperature_measures
WHERE [time] >= '2021-01-01 00:00'
AND [time] < '2021-05-01 00:00'
UNION ALL
/* 2. Sensor */
SELECT [time], [floor], 2 AS [Sensor],
[Sensor_02] AS [temperature]
FROM dbo.temperature_measures
WHERE [time] >= '2021-01-01 00:00'
AND [time] < '2021-05-01 00:00'
UNION ALL
/* 3. Sensor */
SELECT [time], [floor], 3 AS [Sensor],
[Sensor_03] AS [temperature]
FROM dbo.temperature_measures
WHERE [time] >= '2021-01-01 00:00'
AND [time] < '2021-05-01 00:00'
)
/* Aggregation und Ausgabe */
SELECT tm.[time],
tm.[floor],
tm.[Sensor_01],
tm.[Sensor_02],
tm.[Sensor_03],
AVG([temperature]) AS avg_temperature
FROM measures AS m
INNER JOIN dbo.temperature_measures AS tm
ON
(
m.[time] = tm.[time]
AND m.[floor] = tm.[floor]
)
GROUP BY
tm.[time],
tm.[floor],
tm.[Sensor_01],
tm.[Sensor_02],
tm.[Sensor_03]
ORDER BY
tm.[time],
tm.[floor];
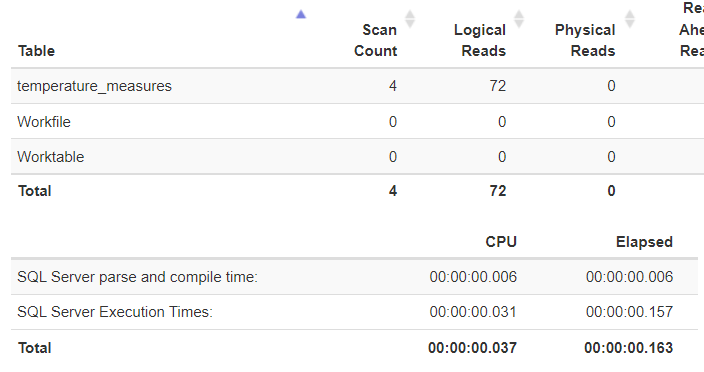
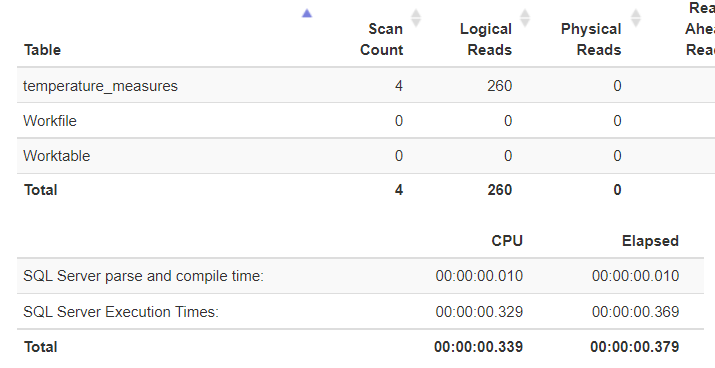
Die Statistiken dieser Auswertung zeigen, dass SQL Server 4 Mal auf die Tabellen [dbo].[temperature_measures] zugreifen musste. Jeweils einmal pro Sensor auf das Dataset und ein viertes Mal für den JOIN Operator für die Ausgabe der Sensorwerte im Gesamtergebnis. Dank eines effektiven Index bewegen sich die IO und die CPU-Zeiten in einem angemessenen Rahmen.
Problematisch wird diese Art der Auswertung jedoch dann, wenn – wie in diesem Beispiel – nicht drei Sensoren sondern (wie in der tatsächlichen Umgebung des Kunden) >=200 Sensoren pro Etage verbaut sind. In diesem Fall müsste die Tabelle nämlich für jeden einzelnen Sensor mit einem UNION Operator auf die Tabelle zugreifen. Ein weiteres Problem ergibt sich, wenn für einen größeren Zeitraum eine Auswertung durchgeführt werden muss.
UNPIVOT
Das Ziel muss – wie im vorherigen Beispiel gezeigt – sein, dass die Daten aus den unterschiedlichen Attributen zu EINEM Dataset normalisiert werden. Hierzu stellt Microsoft SQL Server den UNPIVOT Operator zur Verfügung. Eine genaue Beschreibung erspare ich mir hier, da sie den Rahmen sprengen würde. Ich kann jedoch sagen, dass die Syntax bei SQL Server so kompliziert ist, dass ich immer wieder nachlesen muss, wenn dieser Operator in einer Abfrage eingesetzt werden muss :)
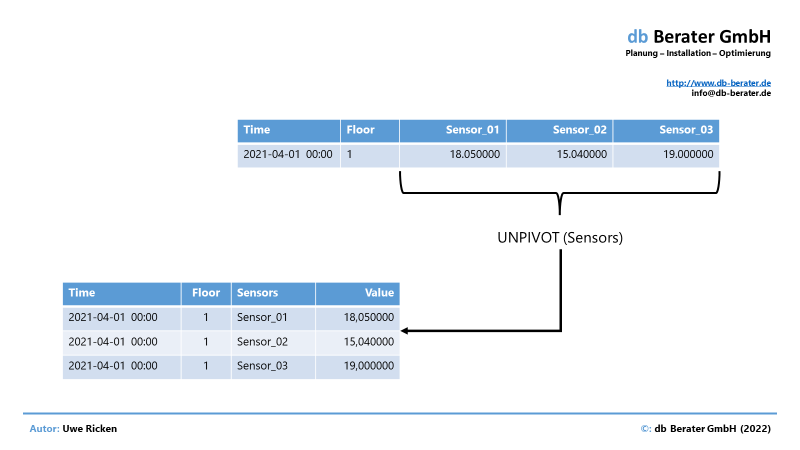
Das Prinzip von UNPIVOT ist trivial. Es werden die Attribute in einer Relation angegeben, die als Zeilenwerte dargestellt werden sollen.
SELECT up.[time],
up.[floor],
up.[Sensors],
up.[temperature]
FROM dbo.temperature_measures
UNPIVOT
(
temperature FOR Sensors
IN ([Sensor_01], [Sensor_02], [Sensor_03])
) AS up
WHERE up.[time] >= '2021-04-01'
AND up.[time] <'2021-05-01'
ORDER BY
[time],
[floor],
[up].[Sensors];
Mit dem durch UNPIVOT generierten Dataset kann eine Berechnung des Mittelwerts durchgeführt werden.
/* normalisiertes Dataset */
;WITH measures
AS
(
SELECT [time], [floor], up.[temperature]
FROM dbo.temperature_measures AS t
UNPIVOT
(
temperature FOR Sensors
IN ([Sensor_01], [Sensor_02], [Sensor_03])
) AS up
)
SELECT m.[time],
m.[floor],
m.Sensor_01,
m.Sensor_02,
m.Sensor_03,
AVG(mt.temperature) AS avg_temperature
FROM dbo.temperature_measures AS m
INNER JOIN measures AS mt
ON
(
m.[time] = mt.[time]
AND m.[floor] = mt.[floor]
)
WHERE m.[time] >= '2021-04-01'
AND m.[time] < '2021-05-01'
GROUP BY
m.[time],
m.[floor],
m.Sensor_01,
m.Sensor_02,
m.Sensor_03
ORDER BY
m.[time],
m.[floor];
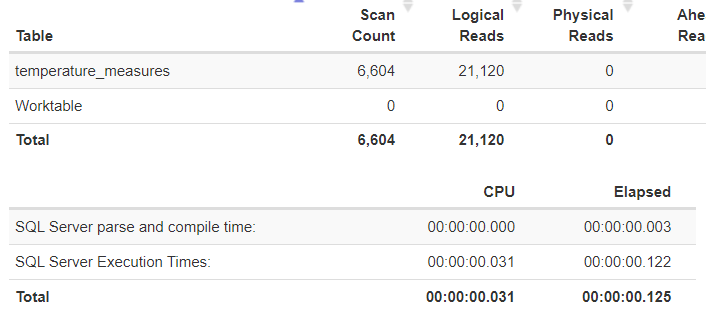
Auf den ersten Blick scheint die Abfrage komplexer und teurer. Die Statistiken belegen eindeutig, dass das IO massiv gestiegen ist während die CPU-Zeiten abgenommen haben.
OUTER / CROSS APPLY
Der APPLY-Operator ermöglicht es, eine Tabellenwertfunktion für jede Zeile einer äußeren Tabelle aufzurufen.
Für jede Zeile in der äußeren Tabelle wird die Tabellenwertfunktion ausgewertet, um zu bestimmen, ob Zeilen zurückgegeben werden. Die von der Tabellenwertfunktion zurückgegebenen Spalten werden mit den Spalten der Zeile im äußeren Datensatz zusammengeführt, um den endgültigen zurückgegebenen Datensatz mit allen Attributen zu erzeugen.
Ein klassischer Fall, der sich mit dem APPLY Operator lösen lässt, zeigt der nachfolgende Code.
SELECT c.Id,
c.name,
co.OrderDate,
co.OrderNumber,
co.InvoiceNumber
FROM dbo.Customers AS c
CROSS APPLY
(
SELECT TOP (3)
OrderDate,
OrderNumber,
InvoiceNumber
FROM dbo.CustomerOrders
WHERE Customer_Id = c.Id
ORDER BY
OrderDate DESC
) AS co (OrderDate, OrderNumber, InvoiceNumber)
WHERE c.Id <= 5;
Das Beispiel gibt für jeden Kunden mit einer ID <= 5 die letzten drei Bestellungen aus. Der APPLY Operator wird verwendet, um die letzten drei Bestellungen für jeden Kunden zu ermitteln. Die Besonderheit des APPLY Operators ist in Zeile 14 hervorgehoben.
Während es in einer Sub Select Operation nicht möglich ist, ein Attribut der äußeren Tabelle zu verwendet, macht der APPLY Operator das möglich! Der APPLY Operator kann aus der äußeren Tabelle JEDES Attribut verwenden!
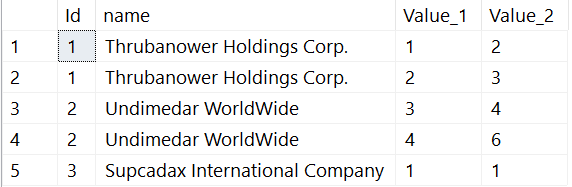
Einem APPLY Operator muss nicht zwingend eine Abfrage übergeben werden, die auf einer Tabelle basiert. Auch Werte können einen valide Relation bilden, wie das nächste Beispiel zeigt.
SELECT c.Id,
c.name,
co.Value_1,
co.Value_2
FROM dbo.Customers AS c
CROSS APPLY
(
SELECT rs.Customer_Id,
rs.Value_1,
rs.Value_2
FROM
(
VALUES (1, 1, 2),
(1, 2, 3),
(2, 3, 4),
(2, 4, 6),
(3, 1, 1)
) AS rs (Customer_Id, Value_1, Value_2)
WHERE rs.Customer_Id = c.Id
) AS co (Customer_Id, Value_1, Value_2)
WHERE c.Id <= 5;
Das erste Attribut des APPLY Operators repräsentiert das Attribut [Customer_Id]. Das Dataset hat Daten für die Kunden 1, 2 und 3. Somit werden nur Daten für die entsprechenden Kunden ausgegeben.
Kombiniert man die beiden Merkmale des APPLY Operators (Verwendung von Attributen aus äußerer Tabelle / Verwendung von Werten / VALUE(S) ), liegt die Lösung für das Problem auf der Hand. Wenn die Sensordaten für jede Datenzeile an den APPLY Operator übergeben werden und der APPLY Operator sie wie VALUES behandelt, bilden wir aus mehreren Attributen der äußeren Tabelle ein Dataset, dass ausgewertet werden kann.
SELECT m.[time],
m.[floor],
m.[Sensor_01],
m.[Sensor_02],
m.[Sensor_03],
t.avg_temperature
FROM dbo.temperature_measures AS m
CROSS APPLY
(
SELECT AVG(s.temperature) AS avg_temperature
FROM
(
VALUES
(m.[Sensor_01]),
(m.[Sensor_02]),
(m.[Sensor_03])
) AS s (temperature)
) AS t
WHERE m.[time] >= '2021-04-01'
AND m.[time] < '2021-05-01'
ORDER BY
m.[time],
m.[floor];
Zunächst werden die Sensordaten als VALUES übergeben. Aus diesen Werten wird anschließend eine normalisierte Tabelle erstellt (Zeile 14 – 16), mit der abschließend die Aggregation ermittelt wird (Zeile 10).
Da der APPLY Operator ein eigenes Dataset zurück liefert, kann das Ergebnis wie eine reguläre Tabelle im Output verwendet werden (Zeile 6).
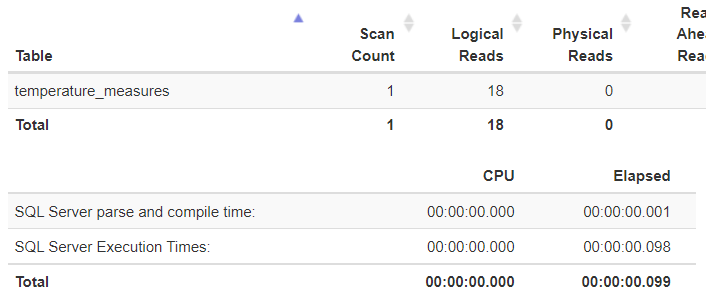
Entscheidend für den Erfolg der Optimierung sind die Ressourcenwerte. Die stellen sich bei der Variante mit dem APPLY Operator als sehr effektiv heraus. Der Vorteil beim Ergebnis für das IO ist dem Umstand geschuldet, dass die Tabelle nur ein Mal durchlaufen werden muss und bereits bei der Ermittlung des Datensatzes die Sensordaten in den APPLY Operator übergeben werden. Sobald die Auswertung erfolgt ist, kann der nächste Datensatz übergeben werden.
Vergleich der Laufzeiten
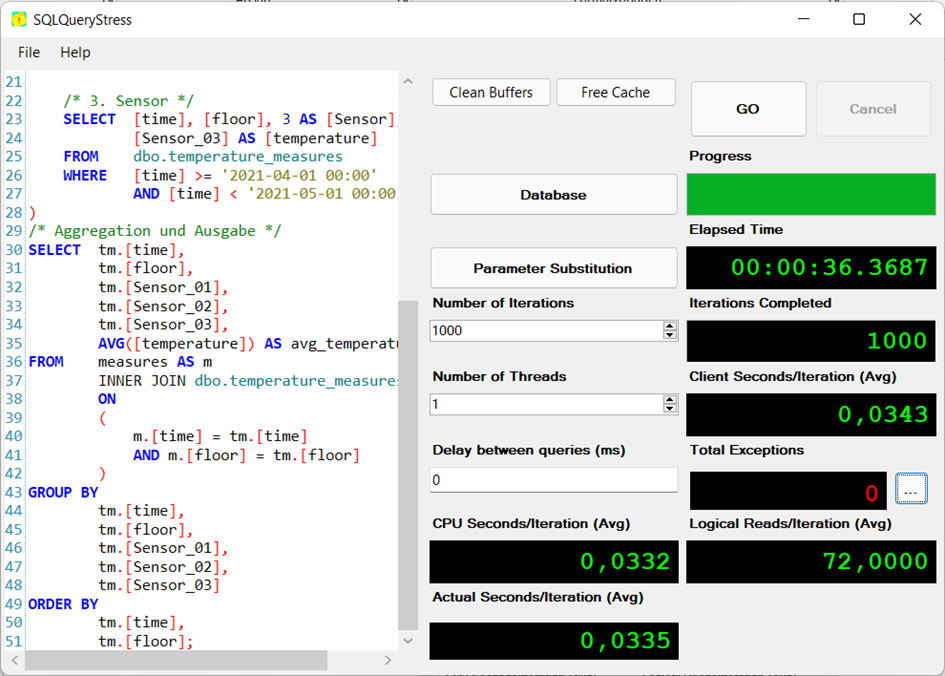
Um eine zuverlässigere Aussage treffen zu können, habe ich mit SQLQueryStress (Adam Machanic) für alle oben genannten Varianten Testreihen mit jeweils 1.000 Ausführungen für einen Thread gestartet. Die Ergebnisse sprechen für sich.
| Messpunkt | UNION | UNPIVOT | CROSS APPLY |
| Elapsed Time | 00:36.3687 | 00:27.4227 | 00:09.7304 |
| CPU Time/Iteration | 00:00.0332 | 00:00:0253 | 00:00.0076 |
| Logical Reads | 72 | 20.701 | 18 |
Herzlichen Dank fürs Lesen!






{kind=link}