Kennen Sie das Problem, dass ein Index für eine Tabelle implementiert wird und die Abfrage dennoch nicht schneller ist? Ursächlich kann in solchen Fällen die Verwendung von falschen Datentypen für die Prädikate, die in einer WHERE-Klausel oder einem JOIN verwendet werden, sein. In diesem Artikel beschreibe ich, wie wichtig es ist, dass man auf Datentypen achten sollte.
Inhaltsverzeichnis
Testumgebung
Um die Auswirkungen falscher Datentypen zu demonstrieren, wird eine Tabelle [dbo].[Customers] mit 75.000 Datensätzen aus meiner Demodatenbank [CustomerOrders] angelegt.
SELECT C.Id,
C.Name,
A.Street,
A.CCode,
CAST(A.ZIP AS VARCHAR(5)) AS ZIP,
A.City,
A.State
INTO dbo.Customers
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerAddresses AS CA
ON (C.Id = CA.Customer_Id)
INNER JOIN CustomerOrders.dbo.Addresses AS A
ON (CA.Address_Id = A.Id)
WHERE CA.IsDefault = 1;
GO
--
(292028 rows affected)
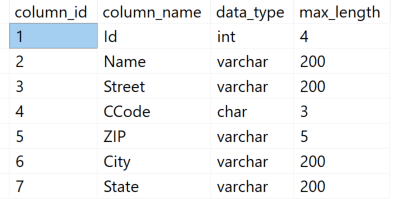
Die neue Tabelle besitzt fünf Attribute mit verschiedenen Datentypen.
-- Welche Spalten besitzt die Tabelle
SELECT C.column_id,
C.name,
TY.name,
C.max_length
FROM sys.tables AS T
INNER JOIN sys.columns AS C
ON (T.object_id = C.object_id)
INNER JOIN sys.types AS TY
ON (C.system_type_id = TY.system_type_id)
WHERE T.name = N'Customers'
ORDER BY
C.column_id;
GO
Use Case
Regelmäßig werden Abfragen ausgeführt, die Kunden aus einem Postleitzahlgebiet suchen.
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP = '64390'
ORDER BY
C.Name;
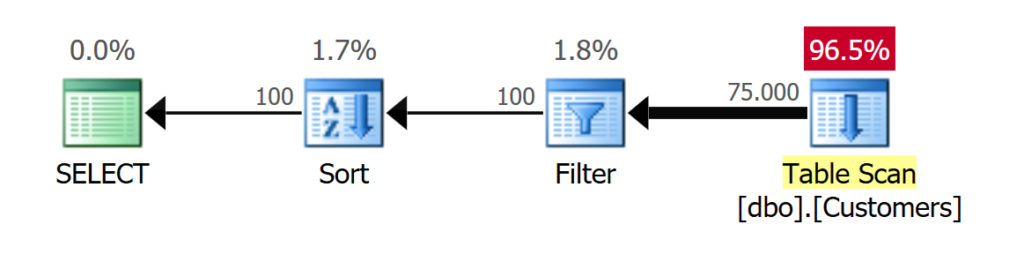
Da noch kein Index vorhanden ist, muss Microsoft SQL Server die vollständige Tabelle scannen und mit Hilfe eines Pushdown-Prädikats werden die Datensätze gefiltert, die dem Suchkriterium entsprechen. Im Beispiel betrifft es 100 Datensätze.
CREATE NONCLUSTERED INDEX nix_Customers_ZIP
ON dbo.Customers (ZIP);
GO
Mit einem geeigneten Index sieht der Ausführungsplan besser aus und Laufzeit wie IO haben sich verbessert.
Problemstellung
Das Attribut [ZIP] verwendet den Datentypen [varchar] für die Speicherung der Postleitzahlen. Solange bei dem zu suchenden Wert darauf geachtet wird, dass das Literal einen identischen Datentypen verwendet, kann der Index effizient verwendet werden.
Problematisch wird es jedoch dann, wenn für den Suchwert ein Datentyp verwendet wird, der nicht dem Datentyp des Attributs entspricht.
Equality Predicate für Datentypen
Solche Fälle kommen in der Praxis immer wieder vor. In Deutschland sind Postleitzahlen nur numerisch; das verleitet schnell dazu, die Abfrage wie folgt auszuführen:
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP = 64390
ORDER BY
C.Name
OPTION (QUERYTRACEON 9130);
GO

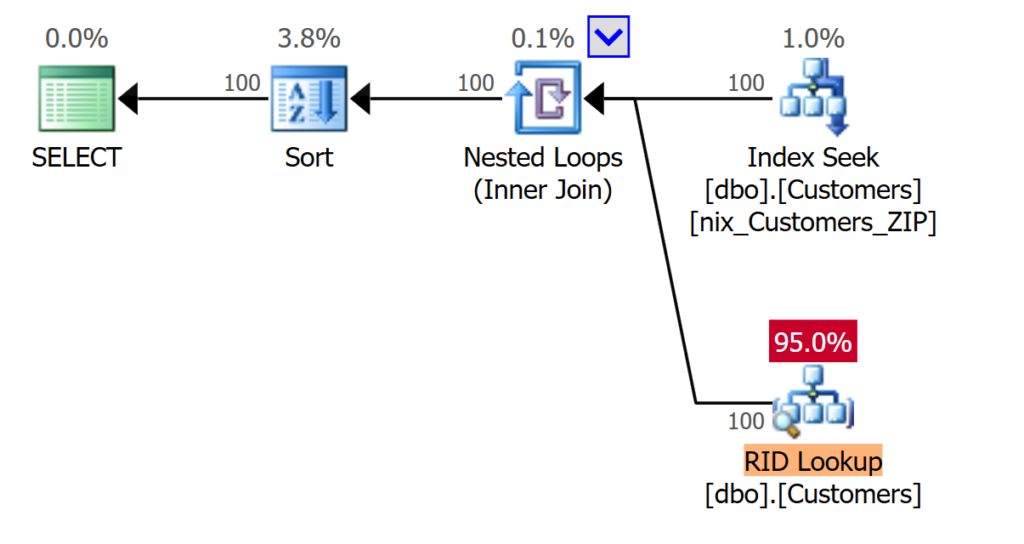
Microsoft SQL Server verarbeitet die Abfrage ohne Berücksichtigung des zuvor genutzten Indexes. Der Grund findet sich im Operator [Compute Scalar]:
[Expr1002] = Scalar Operator
(
CONVERT_IMPLICIT(int,[demo_db].[dbo].[Customers].[ZIP] as [C].[ZIP],0)
)
Microsoft SQL Server MUSS den vereinbarten Datentypen für das Attribut [ZIP] in einen numerischen Wert umwandeln; erst danach kann mit Hilfe eines Filter-Operators die zu suchende Postleitzahl gefiltert werden. Durch den falschen Datentypen wird die Abfrage NONSargable.
Der Umstand, dass einen Datenkonvertierung durchgeführt werden muss, lässt natürlich die Frage aufkommen, welche Regel Microsoft SQL Server bei der Rangfolge für die Konvertierung durchführt. Wie jede Programmiersprache hat auch Microsoft SQL Server Präferenzen und Hierarchien bei der Verwendung von Datentypen.
Zu der „Rangfolge der Datentypen“ gibt es eine offizielle Dokumentation von Microsoft, die die Gewichtung der Datentypen beschreibt.
Rangfolge der Datentypen (T-SQL)

Die Abbildung zeigt einen Ausschnitt aus der Online-Dokumentation. An der 27. Stelle wird der Datentype [varchar] geführt; die numerischen Datentypen genießen einen deutlichen Vorrang.
Microsoft SQL Server musste also – auf Grund der obigen Regeln – das Attribut [ZIP] zu einem Datentypen INT konvertieren, da das Prädikat numerisch ist.
Wird ein Datentyp für ein Prädikat verwendet, das zur gleichen „Kategorie“ numerisch oder nicht numerisch gehört, kann Microsoft SQL Server eine Optimierung des Ausführungsplans generieren, die darauf abzielt, das Prädikat zu konvertieren.
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP = N'64390'
ORDER BY
C.Name
OPTION (QUERYTRACEON 9130)
GO
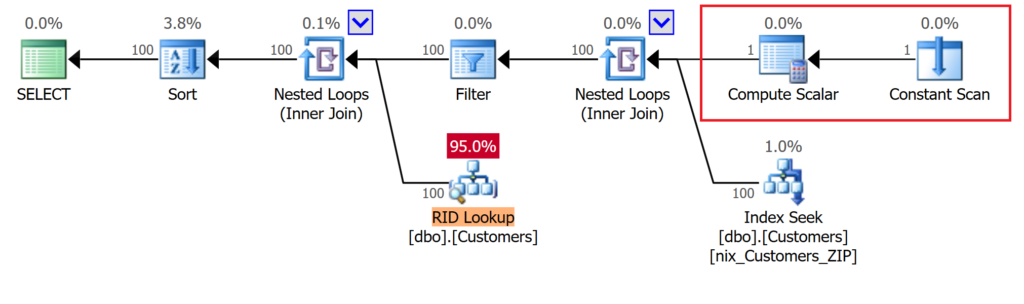
Der Datentyp des Prädikats wurde dahingehend geändert, dass anstatt eines numerischen Wertes ein [NVARCHAR]-Datentyp verwendet wird. Der Ausführungsplan mag komplizierter aussehen, ist aber – trotz des falschen Datentyp – höchst effizient.
Statt – wie im vorherigen Beispiel gesehen – den Datentypen des Attributs anzupassen, wird der Wert des Literals in einem [Constant Scan]-Operator gespeichert und dann mittels eines [Compute Scalar]-Operators in den korrekten Datentypen umgewandelt. Damit kann Microsoft SQL Server wieder auf den Index zugreifen und im Index nach der Postleitzahl suchen.
Range Scan für Datentypen
Abfragen werden nicht immer so ausgeführt, dass nur ein einzelner Wert gesucht wird. Häufiger kommt es vor, dass ein Bereich von möglichen Daten gesucht wird. Wird die obige Abfrage so geändert, dass Microsoft SQL Server einen Index Range Scan durchführen muss, entstehen ebenfalls Probleme, wenn nicht der korrekte Datentyp verwendet wird.
DBCC SHOW_STATISTICS(N'dbo.Customers', N'nix_Customers_ZIP')
GO
Mit dem obigen Befehl werden die Informationen zum Statistikobjekt des Index [nix_Customers_ZIP] angezeigt, die automatisch erstellt werden, sobald ein Index erstellt wird.
![Statistiken zu Index [nix_Customers_ZIP]](https://www.db-berater.de/wp-content/uploads/2020/04/Unbenannt-16.png)
Weitere Informationen zu Statistiken finden sich in der Dokumentation von Microsoft SQL Server.
https://docs.microsoft.com/de-de/sql/relational-databases/statistics/statistics
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP >= '64390'
AND ZIP <= '64720'
ORDER BY
C.Name
OPTION (QUERYTRACEON 9130);
GO
Die Abfrage wurde so angepasst, dass sie nun alle Kunden aus dem Postleitzahlbereich von „64390“ – „64720“ anzeigen soll.
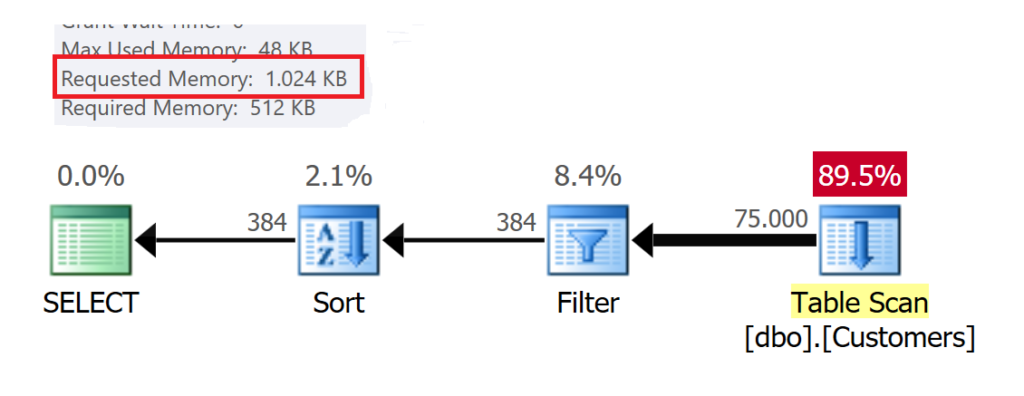
Microsoft SQL Server kann bei korrekten Datentypen das Histogramm verwenden und kann die Anzahl der Datensätze genau bestimmen (100 + 270 + 14) = 384 Datensätze.
Neben einer geeigneten Strategie für die Ausführung der Abfrage spielt die Zuweisung von Speicher bei STOP-Operatoren eine wichtige Rolle. Für diese Abfrage hat Microsoft SQL Server kalkuliert, dass 1.024 KB Memory für die Sortierung der Daten erforderlich sind.
Wird jedoch ein nicht kompatibler Datentyp verwendet, kann Microsoft SQL Server die Schätzung nicht mehr aus dem Histogramm ableiten.
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP >= 64390
AND ZIP <= 64720
ORDER BY
C.Name
OPTION (QUERYTRACEON 9130);
Das Beispiel mit dem numerischen Prädikat wird wiederholt und der Ausführungsplan zeigt deutliche Veränderungen in der Ausführung.

Microsoft SQL Server konvertiert zunächst für alle 75.000 Datensätze das Attribut [ZIP] in einen numerischen Datentypen (COMPUTE_SCALAR), um anschließend nach den passenden Werte zu filtern (FILTER). Nachdem die entsprechenden Daten gefunden wurde, müssen sie sortiert werden (SORT), bevor sie an den Client gesendet werden.
Der SORT-Operator ist ein STOP-Operator. Er muss zunächst die Daten im Speicher vorhalten, bis die Sortierung abgeschlossen ist. Dafür muss Microsoft SQL Server – basierend auf den geschätzten Zeilen – Speicher reservieren. Im obigen Beispiel belief sich die Schätzung auf 7.750 Datensätzen; deutlich mehr, als tatsächlich zurückgeliefert wurden.
Somit reserviert Microsoft SQL Server mehr Speicher, als tatsächlich gebraucht wird – ein sogenannter „excessive memory grant“
Noch deutlich gravierender ist der Unterschied bei der Verwendung des Datentypen [NVARCHAR].
SELECT C.Id,
C.Name,
C.Street,
C.CCode,
C.ZIP,
C.City,
C.State
FROM dbo.Customers AS C
WHERE ZIP >= N'64390'
AND ZIP <= N'64720'
ORDER BY
C.Name
OPTION (QUERYTRACEON 9130);
GO
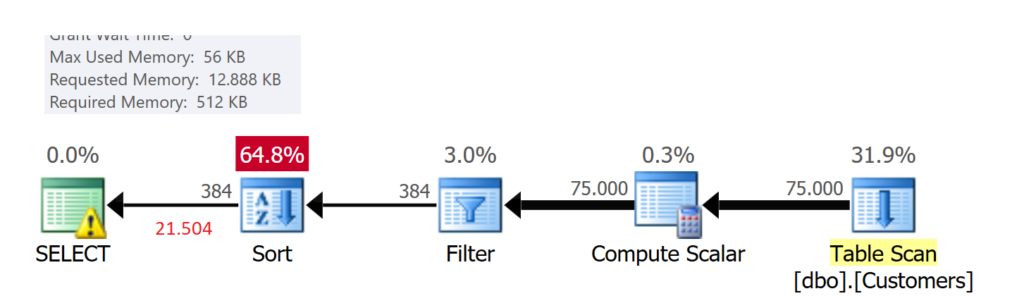
Bei der Verwendung eines Textdatentyps eskaliert die Anforderung an Speicher. Microsoft SQL Server fordert 12 MB Speicher an, da der Ausführung der Abfrage eine Schätzung von 21.504 Datenzeilen vorausging.
Zusammenfassung
Sehr häufig sehe ich bei der Begutachtung von Datenbank-Codes und der Analyse von Abfragen mit langen Laufzeiten, dass die Parameter für Prädikate und/oder JOINS nicht „zueinander passen“. Diese Konstellation kann dann zu einem Problem werden, wenn – bei Betrachtung der Hierarchie von Datentypen – der zu suchende Wert in der Hierarchie höher angesiedelt ist, als der Datentyp der Attribute des Index.
Muss der Datentyp eines Attributs umgewandelt werden, ergeben sich daraus die folgenden Probleme:
- INDEX SEEK kann nicht mehr durchgeführt werden
- erhöhter CPU-Konsum durch COMPUTE-Operation
- Falsche Schätzung der Anzahl von Datensätzen, die gefunden werden
- Falsche Berechnung von Arbeitsspeicher für STOP-Operatoren
Solche Probleme lassen sich vermeiden, wenn im Vorfeld darauf geachtet wird, welche Datentypen in den Tabellen verwendet werden.
Think BIG
Der Eine oder Andere mag als Argument anführen, dass „das bischen mehr Speicher“ oder die 100 ms längere Ausführungsdauer doch nicht so schlimm wären. Hier sei angemerkt, dass es für den EINZELFALL sicherlich richtig ist – aber was geschieht mit Abfragen, die von 1.000 Sessions mehrmals in der Minute ausgeführt werden?
Herzlichen Dank fürs Lesen!





