Im vorherigen Artikel „Heaps – Lesen von Daten“ wurden die Möglichkeiten beschrieben, wie die Performance für das Auswählen von Daten aus einem Heap optimiert werden kann. Dieser Artikel beschreibt die Möglichkeit, mit Hilfe von NonClustered Indexes ebenfalls effektive Abfragezeiten für Heaps zu erreichen.
Inhaltsverzeichnis
NonClustered Index
Ein NonClustered Index ist eine Indexstruktur, die von den Daten in der Tabelle getrennt ist. So können Daten schneller gefunden werden als mit einer Suche in der zugrunde liegenden Tabelle. Im Allgemeinen werden Nonclustered Indizes erstellt, um die Leistung von häufig verwendeten Abfragen zu verbessern, die nicht vom Clustered Index oder Heap abgedeckt werden.
Demonstration
Da ein Heap Daten nicht nach einem Schlüsselattribut sortiert, kann ein NonClustered Index nur mit Hilfe der Position des Datensatzes im Heap eine Referenz bilden. Die Position eines Datensatzes in einem Heap wird durch drei Informationen bestimmt:
- Dateinummer
- Datenseite
- Slot
Diese drei Informationen werden als Referenz in jedem NonClustered Index zum eigentlichen Schlüssel des Indexes gespeichert. Für die Demos wird die – wie im Artikel „Heaps – Lesen von Daten“ – Tabelle mit ca. 4.000.000 Datensätzen verwendet.
Auf diese Tabelle wird sehr häufig von Anwendern zugegriffen, um Bestellungen für einen bestimmten Zeitraum anzuzeigen. Da auf dem Attribut [OrderDate] kein Index liegt, muss immer ein Table Scan durchgeführt werden.
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate = '20081220'
OPTION (QUERYTRACEON 9130);
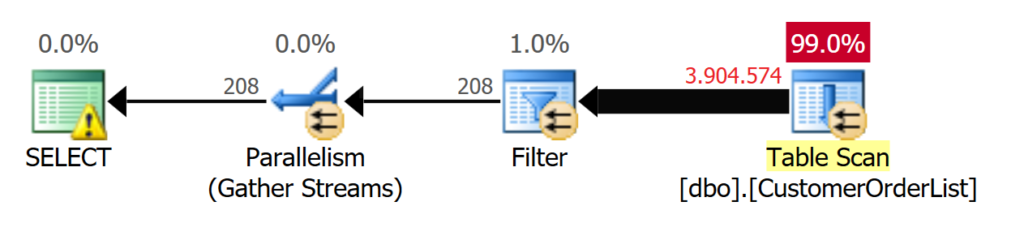
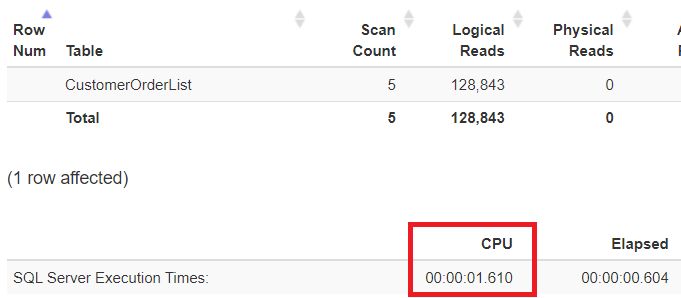
Der Table Scan mag auf schnellen Systemen in ausreichender Zeit erledigt sein (0,604 Sekunden) und vielleicht ist der Programmierer geneigt, diesen Zeitintervall in Kauf zu nehmen. Aber bei solchen Überlegungen werden gerne die folgenden Dinge nicht berücksichtigt, die unabhängig von der Laufzeit relevant sind:
- Die Abfrage parallelisiert und konsumiert die für MAXDOP konfigurierten CPU’s!
- Während der Laufzeit wird eine [SCH-S]-Sperre auf der Tabelle gehalten!
- Was passiert, wenn nicht nur ein Anwender die Abfrage ausführt, sondern – z. B. ein Webclient – tausende Abfragen parallel ausgeführt werden?
Aus den oben genannten Gründen ist es ratsam, die Abfrage zu optimieren. Um die Abfrage zu optimieren, wird ein NonClustered Index für das Attribut [OrderDate] erstellt.
CREATE NONCLUSTERED INDEX nix_CustomerOrderList_OrderDate
ON dbo.CustomerOrderList (OrderDate);
Die gleiche Abfrage kann den erstellten Index verwenden und die Ressourcenlast nimmt deutlich ab!
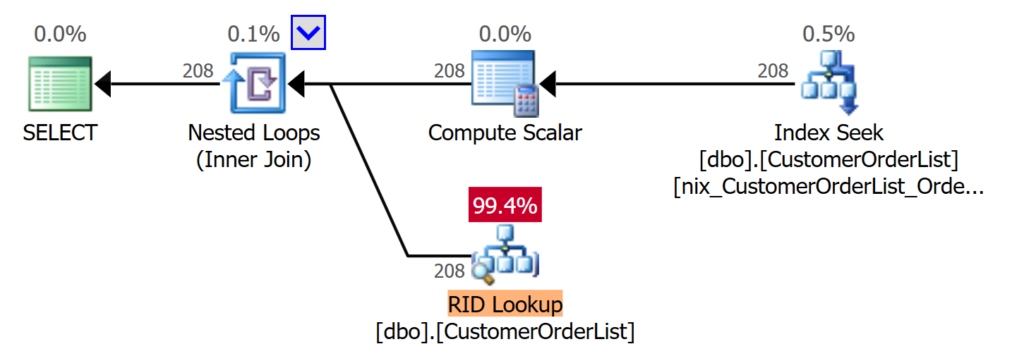
Einige der Nachteilen eines Table Scan sind durch die Verwendung eines Index eliminiert worden:
- Die Abfrage parallelisiert nicht mehr, da die Kosten unter den Schwellwert für Parallelisierung gesunken sind
- Die CPU-Ressourcen sind nicht mehr messbar
- Einzig die [SCH-S]-Sperre wird auch weiterhin verwendet; ist aber in Anbetracht der Laufzeit – vielleicht – zu vernachlässigen.
Man kann also sagen, dass NonClustered Indexe für Heaps von großem Vorteil sein können.
Interne Strukturen
Ein NonClustered Index (NCI) muss IMMER eine Referenz zum Datensatz in der Tabelle speichern. Da ein NCI in der Regel nur wenige Attribute der Tabelle beinhaltet, muss sichergestellt sein, dass jederzeit Attribute, die nicht im NCI verwendet werden, aus der Tabelle ermittelt werden können.
Hinweis
In einem Heap wird diese Referenz als RID (RowLocatorID) gespeichert und hat eine Größe von 8 Bytes!
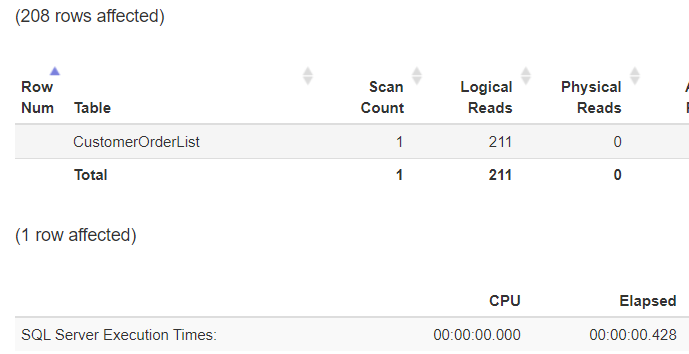
Basierend auf der obigen Demonstration hat die Abfrage insgesamt 211 I/O benötigt, um die Daten abzurufen. Betrachtet man den Ausführungsplan, erkennt man die Verwendung des zuvor angelegten Index. Jeder Index verwendet eine Baumstruktur mit einem Verweis in die nächste Ebene. So kann schnell und effizient nach Daten in einem Index gesucht werden.
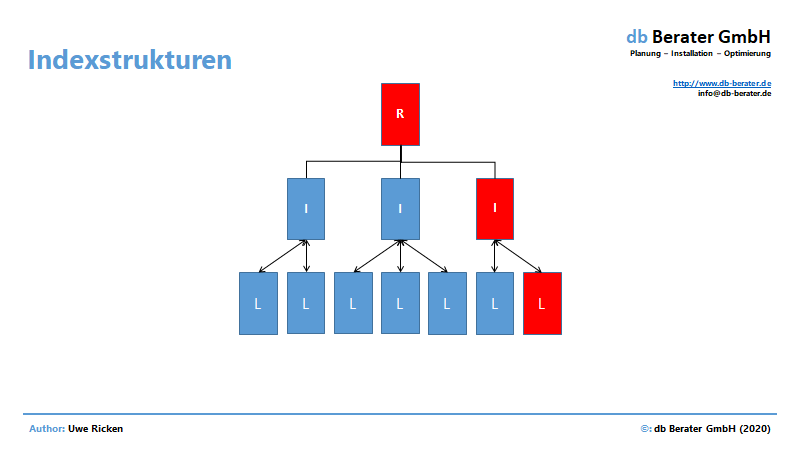
Ein Blick in den Index offenbart diese Struktur. Hierzu muss zunächst die Datenseite ermittelt werden, die den Root-Knoten repräsentiert.
-- Get the information about the root node of the index
SELECT P.index_id,
SIAU.total_pages,
SIAU.used_pages,
SIAU.data_pages,
SIAU.root_page,
sys.fn_PhysLocFormatter(SIAU.root_page) AS root_page
FROM sys.system_internals_allocation_units AS SIAU
INNER JOIN sys.partitions AS P
ON
(SIAU.container_id = P.partition_id)
WHERE P.object_id = OBJECT_ID(N'dbo.CustomerOrderList', N'U');

Der Root-Knoten des Index [nix_CustomerOrderList_OrderDate] befindet sich in Datei #1 auf der Datenseite 73.346. Der Inhalt der Datenseite wird mit DBCC PAGE untersucht.
DBCC TRACEON (3604);
DBCC PAGE (0, 1, 73346, 3);

Man kann erkennen, dass der Index ausschließlich das bei der Erstellung angegebene Attribut verwendet. Alle anderen Attribute müssen aus der Tabelle selbst gelesen werden!
Um nach Bestellungen am 20.12.2008 zu suchen, muss im Attribut [OrderDate] nach der Grenze gesucht werden, in dem sich das gesuchte Datum befindet. Somit geht die Suche im nächsten Level auf Seite 73.348 weiter, bis die unterste Ebene erreicht ist.
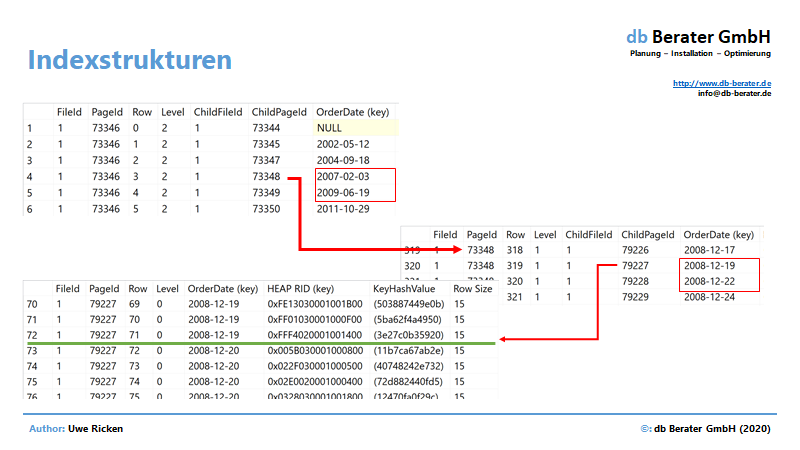
Bis zum aktuellen Zeitpunkt wurden 3 I/O konsumiert. Berücksichtigt man die Gesamtzahl der I/O von 211, wird schnell klar, was im nächsten Schritt passiert. Da der Index nur das Attribut [OrderDate] speichert, fehlen die Informationen der anderen Attribute für den Datensatz. Um diese Informationen zu erreichen, muss Microsoft SQL Server die RID decodieren um auf die Datenseite zu gelangen, auf der sich der Datensatz befindet.
Die RID wird für JEDEN Datensatz im Index gespeichert und hat eine feste Länge von 8 Bytes. Diese 8 Bytes beinhalten alle relevanten Informationen, um zum Datensatz zu gelangen.

| Position | Hex-Wert | shifted | Dezimal-Wert |
|---|---|---|---|
| Byte 1 – 4: Page | 0x005B0300 | 0x00 03 5B 00 | 219.904 |
| Byte 5 – 6: File | 0x0100 | 0x00 01 | 1 |
| Byte 7 – 8: Slot | 0x0800 | 0x00 08 | 8 |
Der Datensatz, dessen [OrderDate] im Index repräsentiert wird, befindet sich in Datei #1 auf Datenseite #219.904 in Slot #8.
DBCC PAGE (0, 1, 219904, 3) WITH TABLERESULTS;
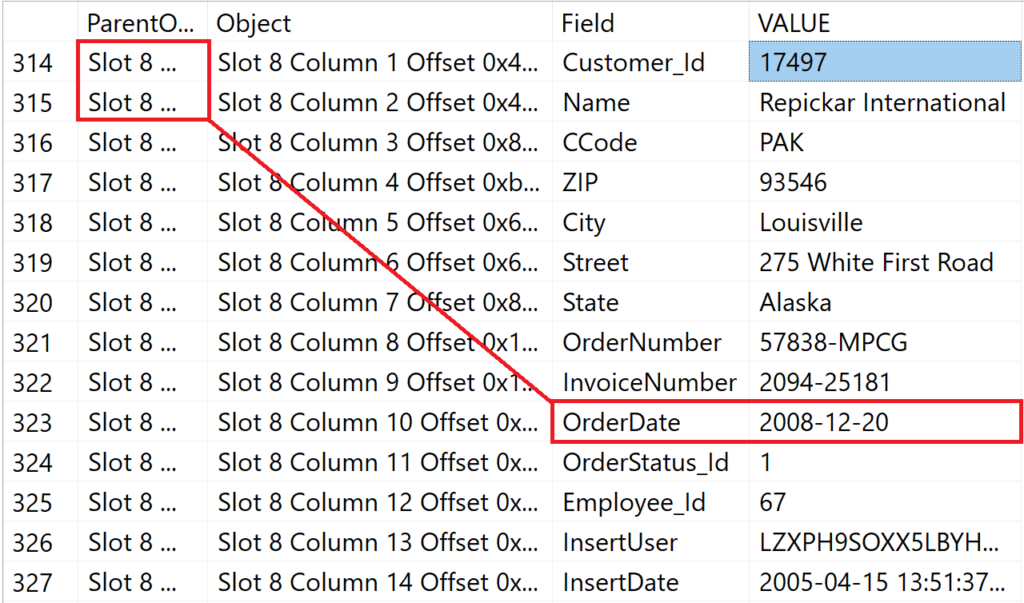
Der Vorgang wiederholt sich für jeden gefunden Datensatz aus dem Index. Die Mathematik hinter dem Ergebnis von 211 ist also recht trival:
3 I/O für die Suche im Index + 208 * 1 I/O für den Verweis in die Tabelle selbst.
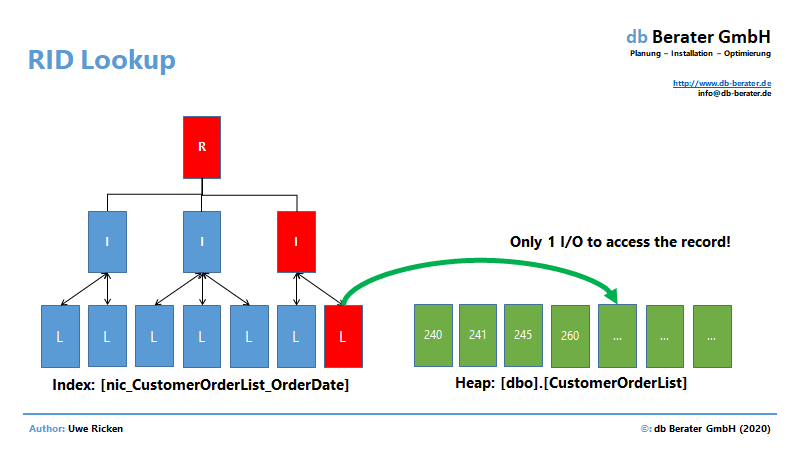
RID-Lookup vs. Key Lookup
Im Unterschied zu einem Heap kann Microsoft SQL Server bei einem Clustered Index nicht unmittelbar auf die Datenseite verweisen, in der sich der Datensatz in der Tabelle befindet. Microsoft SQL Server speichert in einem NCI für eine Tabelle mit gruppiertem Index nicht die Position des Datensatzes sondern den Wert des Schlüsselattributs des Clustered Index.
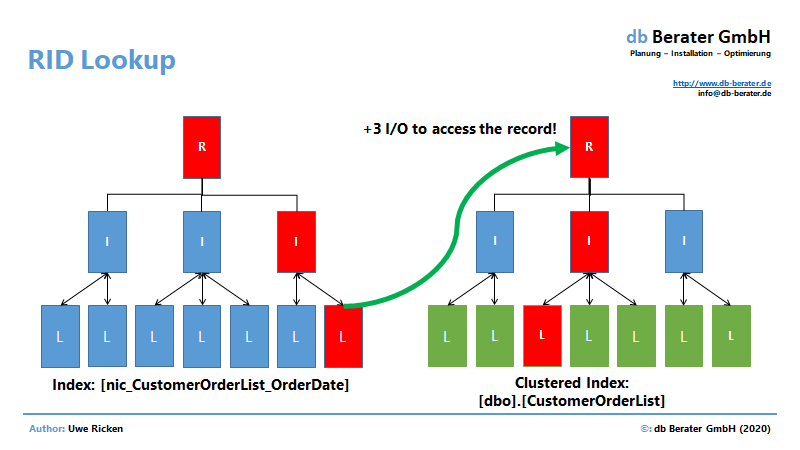
Der Vorteil bei Verwendung des Clustered Index liegt eher in der Maintenance von Indexen als in der Performance bei Abfragen (wird in einem späteren Artikel beschrieben). Vergleicht man die gleiche Abfrage für einen Heap mit einer Abfrage eines Clustered Index ergeben sich folgenden Unterschiede im Ausführungsplan:
| RID-Lookup | Key-Lookup |
|---|---|
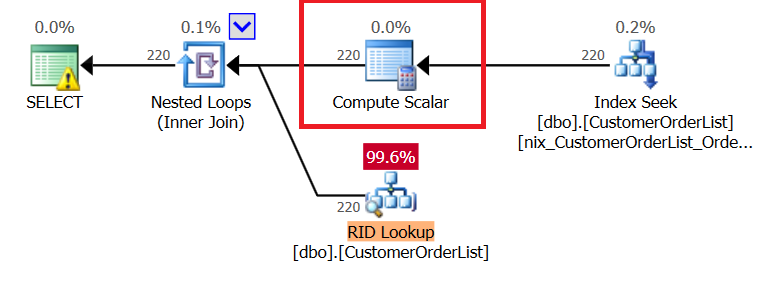 | 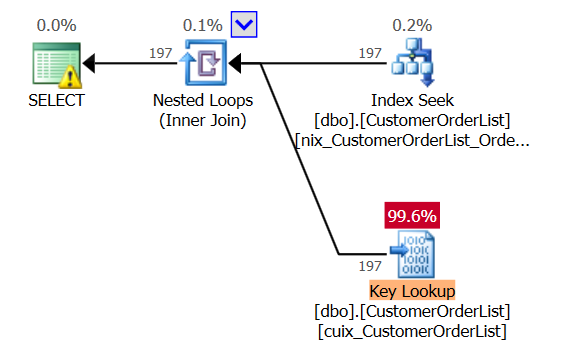 |
Bei einem RID-Lookup muss die RowLocatorID umgerechnet werden, das führt zu einer – vermeintlich – höheren CPU-Belastung. Eines der größten Probleme in den Ausführungsplänen von Microsoft SQL Server ist die Schätzung der Kosten für eine SCALAR-Operation. Standardmäßig werden sie mit 0% kalkuliert; hierbei wird jedoch vergessen, dass der Operator für JEDEN Datensatz aus dem vorherigen Operator ausgeführt werden muss.
Um eine fundierte Aussage über die Kosten der Umrechnung zu treffen, wird der folgende Code mit SQLQueryStress von Adam Machanic (b | t) mit vier Threads (Anzahl der CPU in der Testmaschine) ausgeführt:
DECLARE @order_date DATE = DATEADD(DAY, (RAND() * 7305) + 1, '20000101');
SELECT *
FROM dbo.CustomerOrderList WITH (INDEX(nix_CustomerOrderList_OrderDate))
WHERE OrderDate = @order_date;
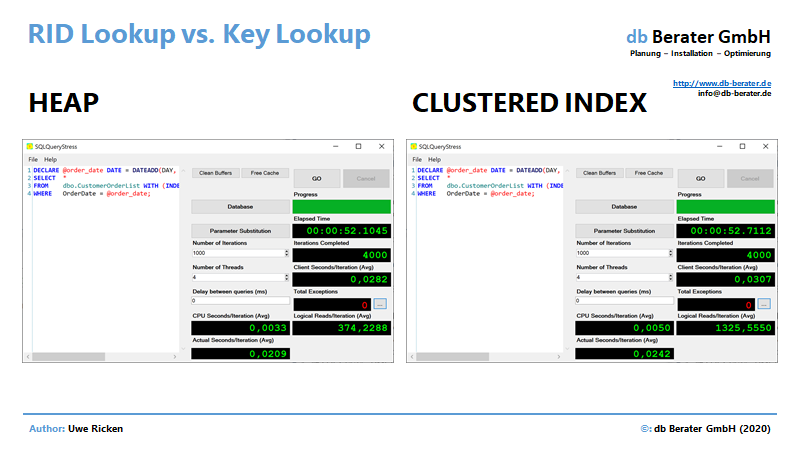
Im direkten Vergleich „siegt“ der Heap in allen Disziplinen. Besonders interessant bei diesem Vergleich ist die Tatsache, dass die CPU-Last mit 3,3 ms/Iteration deutlich hinter der CPU-Last des Clustered Index mit 5 ms liegt.
Ein weiterer – nicht zu unterschätzender – Unterschied ist das I/O pro Iteration. Hier kann der Heap selbstverständlich punkten, da er für den Zugriff auf die Tabelle jeweils 1 I/O benötigt; im Clustered Index sind es jeweils 3 I/O.
Zusammenfassung
Warum streuben sich Entwickler aus dem Umfeld von Microsoft SQL Server so sehr gegen Heaps? Viele Blogartikel von renommierten SQL Server Experten weisen immer wieder darauf hin, dass es von Vorteil wäre, eine Tabelle mit einem Clustered Index zu versehen. Ich bin früher diesen Empfehlungen ebenfalls immer gefolgt, bis ich zwei Artikel gelesen habe, die mich haben „umdenken“ lassen:
| Autor | Artikel |
|---|---|
| Markus Wienand | Unsinnige Defaults: Primärschlüssel als Clusterschlüssel |
| Thomas Kejser | Clustered Index Vs. Heap |
Ich kann nur darauf hinweisen, den „generellen“ Ansatz der Verwendung von Clustered Indizes zu überdenken. Ich möchte nicht abstreiten, dass es Situationen gibt, in denen ein Clustered Index sinnvoll und auch zwingend ist; für reine SELECT-Operationen auf jeden Fall nicht.
Der Grundsatz bei der Auswahl von Daten besteht darin, die Attribute, die als Prädikat und/oder in JOIN-Operatoren verwendet werden, zu indexieren. Sofern es sich nicht um das Primärschlüssel-Attribut handelt, verwendet man NCI. Warum aber nicht auch für den Primärschlüssel?
Mit einem geclusterten Index vermeidet man Key-Lookups. Die sind aber – bei kleiner Datenmenge – eher zu vernachlässigen.
Vielen Dank fürs Lesen!





