Heaps werden in Microsoft SQL Server gemieden, wie der Teufel das Weihwasser meidet. Das liegt unter anderem daran, dass viele Blogartikel renommierter Experten darauf hinweisen, dass eine Tabelle nach Möglichkeit einen Clustered Index verwenden soll. Dabei werden nicht immer alle Aspekte vertieft, die eine solche Entscheidung in Frage stellen.
Dieser Artikel ist der Beginn einer Artikelserie, die sich auf ein möglichst breites Anwendungsgebiete für oder gegen Heaps konzentriert. Im Mittelpunkt steht der Heap, um selbst zu entscheiden, ob und wann ein Heap Vorteile oder Nachteile gegenüber einem Clustered Index hat. Eine sinnvolle Entscheidung setzt voraus, dass man die Arbeitsweise und die internen Strukturen versteht.
Inhaltsverzeichnis
Was sind Heaps
Heaps sind Tabelle ohne Clustered Index. Ohne einen Index ist keine Sortierung für die Daten garantiert. Daten werden ohne eine vorbestimmte Reihenfolge in der Tabelle gespeichert, wo gerade Platz ist. Ist die Tabelle leer, werden Datensätze in der Reihenfolge der INSERT-Befehle in die Tabelle eingetragen.
CREATE TABLE dbo.Customers
(
Id INT NOT NULL,
Name VARCHAR(200) NOT NULL,
Street VARCHAR(200) NOT NULL,
CCode CHAR(3) NOT NULL,
ZIP VARCHAR(5) NOT NULL,
City VARCHAR(200) NOT NULL,
State VARCHAR(200) NOT NULL
)
GO
Das Skript erzeugt eine neue Tabelle für die Speicherung von Kundendaten. Da weder ein Index noch ein Primärschlüssel mit der Option CLUSTERED verwendet wird, werden Daten „unsortiert“ in dieser Tabelle gespeichert.
Besitzt eine Tabelle keinen Clustered Index, verwendet diese Tabelle in der System-View [sys].[indexes] immer die [Index_Id] = 0!
-- A Heap has always the index_id = 0
SELECT object_id,
name,
index_id,
type_desc
FROM sys.indexes
WHERE object_id = OBJECT_ID(N'dbo.Customers', N'U');
GO
![Heaps haben keinen Namen und immer [index_id] = 0](https://www.db-berater.de/wp-content/uploads/2020/04/Unbenannt-21.png)
Strukturen von Heaps
Da Heaps primitive Datenspeicher sind, werden für die Verwaltung von Heaps keine komplexen Strukturen vorausgesetzt.
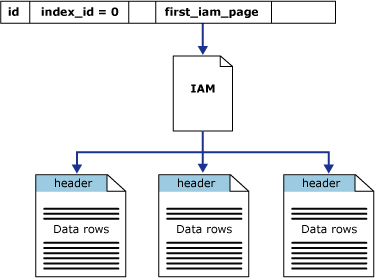
Die Datenseiten eines Heaps speichern keine Referenzen zu nachfolgenden oder vorausgehenden Datenseiten (Links). Das ist für Heaps auch nicht notwendig, weil für einen Heap nicht vorausgesetzt wird, dass Daten nach definierten Kriterien sortiert vorliegen.
Index Allocation Map
Jede Tabelle und jeder Index verwendet IAM-Strukturen (Index Allocation Map) für die Verwaltung der Datenseiten. Eine IAM-Seite enthält Informationen zu Blöcken (Extents), die von einer Tabelle oder einem Index pro Zuordnungseinheit verwendet werden.
IAM-Seiten werden sowohl von Heaps als auch Indexen verwendet!
https://docs.microsoft.com/de-de/sql/relational-databases/pages-and-extents-architecture-guide
INSERT INTO dbo.Customers
(Id, Name, Street, CCode, ZIP, City, State)
VALUES
(1, 'db Berater GmbH', 'Bahnstrasse 33', 'DE', '64390', 'Erzhausen', 'HS');
GO
In die Beispieltabelle wird ein Datensatz eingetragen, damit die Tabellen in der Datenbank persistiert wird!
Tabellen werden erst in dem Moment persistiert, in dem ein erster Datensatz eingetragen wird. Solange die Tabelle neu ist, werden ausschließlich die Metadaten in den Systemtabellen gespeichert!
Nachdem ein erster Datensatz eingetragen wurde, können die allokierten Datenseiten geprüft werden. Hierzu eignet sich am besten die Systemfunktion [sys].[dm_db_database_page_allocations].
-- What pages have been allocated?
SELECT allocated_page_page_id,
previous_page_page_id,
next_page_page_id,
page_type_desc
FROM sys.dm_db_database_page_allocations
(
DB_ID(),
OBJECT_ID(N'dbo.Customers', N'U'),
0,
NULL,
N'DETAILED'
);

Microsoft SQL Server prüft mt Hilfe der IAM-Seite, welche Datenseiten zum Heap oder Index gehören.

Die nächste Abbildung zeigt die IAM-Seite, nachdem weitere 95.000 Datensätze in die Tabelle eingetragen wurden.
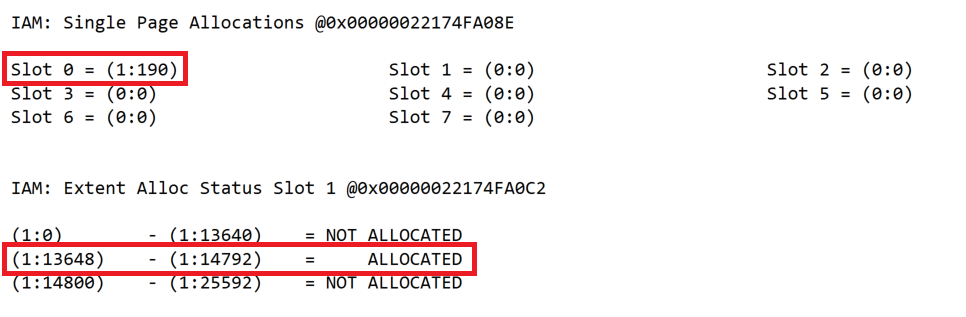
Füllgrad für Datenseiten von Heaps
Die Informationen in den Attributen [previous_page_page_id] und [next_page_page_id] aus der Systemfunktion [sys].[dm_db_database_page_allocation] sind für Heaps nicht relevant. Das Attribut [page_free_space_percent] zeigt – NUR für Heaps – an, wie VOLL die Datenseite ist.
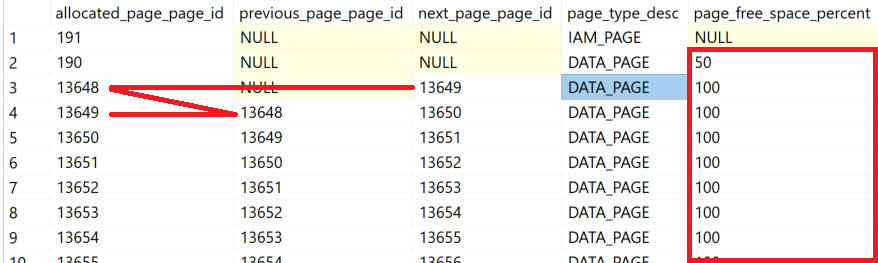
Der Füllgrad einer Datenseite kann nur für Datenseiten eines Heaps angegeben werden. Anders als bei einem Clustered Index sind die Datenzeilen nicht sortiert und müssen nicht in einer sortieren Form eingetragen werden. Somit bleibt es Microsoft SQL Server überlassen, auf welcher Datenseite ein Datensatz gespeichert wird.
Um jedoch zu beurteilen, wo ein Datensatz gespeichert werden kann, muss Microsoft SQL Server wissen, wo noch ausreichend Platz vorhanden ist, um den Speichervorgang abzuschließen. Diese Informationen werden über den Füllgrad der Datenseite abgerufen.
Zu wieviel Prozent eine Datenseite gefüllt ist, wird in einer PFS-Seite gespeichert!
Dieses Thema wird in einem späteren Artikel detailliert beschrieben.
Das Problem dabei ist jedoch, dass dieser Füllgrad nicht „exakt“ gespeichert wird. Vielmehr verwendet Microsoft SQL Server nur „grobe“ Prozentsätze für die Angabe des Füllgrads
| Füllgrad | Zustand |
| 0% | 0 Bytes |
| 50% | <=4.030 Bytes |
| 80% | > 4.030 Bytes | <=6.448 Bytes |
| 95% | > 6.448 Bytes | <=7.628 Bytes |
| 100% | > 7.628 Bytes | <= 8.060 Bytes |
Der nächsthöhere Füllgrad wird immer dann aktualisiert, sobald der Zustand überschritten ist. Beispielsweise ist eine Datenseite IMMER zu 50% gefüllt, sobald der erste Datensatz eingetragen wird.
Das nächste Beispiel zeigt, wie sich der Füllgrad ändert, wenn der Zustand (Bytes) überschritten wird. Dazu wird ein Heap erstellt, der pro Datensatz 2.004 Bytes speichert.
CREATE TABLE dbo.demo_table
(
C1 INT NOT NULL IDENTITY (1, 1),
C2 CHAR(2000) NOT NULL DEFAULT ('Test')
);
GO
INSERT INTO dbo.demo_table DEFAULT VALUES;
GO

Beim zweiten Datensatz ändert sich der Füllgrad nicht mehr, da 2 * 2011 Bytes = 2.022 Bytes eben nicht die 50% erreichen. Erst beim dritten Datensatz muss der Füllgrad aktualisiert werden!
Jeder Datensatz besitzt einen Record-Header, der die Struktur des Datensatzes beschreibt. Die Struktur wird in 7 Bytes gespeichert. von Daher ist die physikalische Länge eines Beispiel-Datensatzes nicht 2.004 Bytes sondern 2.011 Bytes.
https://www.sqlskills.com/blogs/paul/inside-the-storage-engine-anatomy-of-a-record/

Vorteile von Heaps
Die Verwendung eines Heaps kann effizienter sein, als eine Tabelle mit einem Clustered Index. Generell ist der Speichervorgang beim Einfügen neuer Datensätze in einen HEAP besser, da beim Speichern von Daten nicht auf eine Sortierung geachtet werden muss; Datensätze werden auf der nächst möglichen Datenseite gespeichert, auf der ausreichend Platz vorhanden ist.
Dieser Vorteil trifft aber nur dann zu, wenn kein hoch-transaktionales System Daten in die Tabelle eintragen muss (z. B. Statusmeldungen von mehreren Produktionsmaschinen in Werk).
Nachteile von Heaps
Heaps können verschiedene Nachteile aufweisen:
- Ein Heap kann bei ungeeignetem Datenbankdesign nicht skalieren
- In einem Heap kann man nicht effizient nach Daten suchen.
- Die Zeit für die Suche nach Daten in einem Heap wächst linear zum Datenvolumen.
- Ein Heap ist ungeeignet für häufige Aktualisierungen von Daten, wenn das Datenmodell nicht berücksichtigt, dass Heaps verwendet werden (Forwarded Records).
- Ein Heap ist für jeden Datenbank-Administrator ein Grauen, wenn es zum Thema „Maintenance“ kommt.
Einige der oben genannten „Nachteile“ können beseitigt/umgangen werden, wenn man weiß, wie ein Heap intern „tickt“.
Dank „Corona“ werde ich mich in der nächsten Zeit mit weiteren Artikeln zum Thema Heaps beschäftigen. Ich hoffe, dass ich mit dieser Serie den Einen oder Anderen davon überzeugen kann, dass ein Clustered Index nicht immer die bessere Wahl ist.
Herzlichen Dank fürs Lesen!





