Nachdem sich die vorherigen Artikel mit den internen Strukturen und der Auswahl von Daten in Heaps beschäftigt haben, werden die nächsten Artikel beschreiben, wie DML-Operationen für einem Heap optimiert werden können.
Inhaltsverzeichnis
Standardverfahren – INSERT
Wenn Datensätze in einen Heap eingetragen werden , besteht dieser Prozess aus mehreren Einzelschritten, die für die Applikationen transparent sind. Sie zu kennen, lässt Spielraum für mögliche Optimierungen am Prozess. Für alle nachfolgenden Beispiele verwende ich einen Heap, der Kunden und ihre Adressen speichert.
CREATE TABLE dbo.Customers
(
Id INT NOT NULL,
Name VARCHAR(200) NOT NULL,
CCode CHAR(3) NOT NULL,
State VARCHAR(200) NOT NULL,
ZIP CHAR(10) NOT NULL,
City VARCHAR(200) NOT NULL,
Street VARCHAR(200) NOT NULL
);
GO
Aktualisierung von PFS
Wird ein Datensatz in einem Heap gespeichert und es steht nicht ausreichend Platz auf der Datenseite zur Verfügung, muss eine neue Datenseite erstellt werden. Erst, nachdem die neue Seite erstellt wurde, kann der Datensatz gespeichert werden.
INSERT INTO dbo.Customers
SELECT *
FROM dbo.CustomerAddresses
WHERE Id = 1;
GO
Das obige Beispiel fügt einen neuen Datensatz aus einer bestehenden Datenquelle der neuen Tabelle hinzu. Da die Tabelle bisher leer war, muss zunächst die Tabellenstruktur erstellt werden.
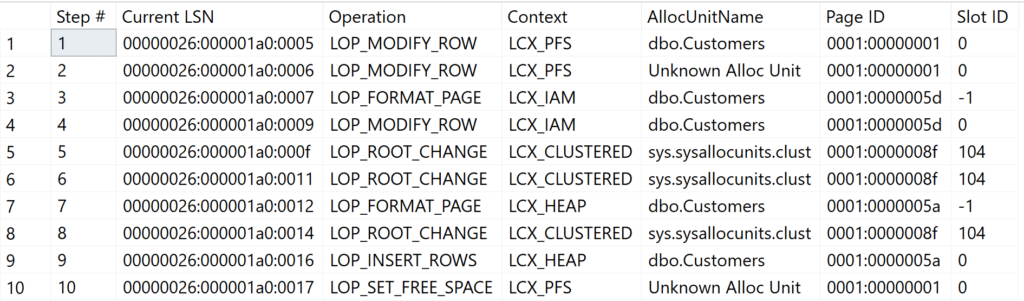
| Schritt | Operation + Context | Beschreibung |
|---|---|---|
| 1 + 2 | LOP_MODIFY_ROW LCX_PFS | Da zunächst Datenseiten für die Tabelle angelegt werden, muss jede Belegung in der PFS-Seite „registriert“ werden. Für die Tabelle werden eine Datenseite sowie die IAM-Seite erstellt und registriert. |
| 3 | LOP_FORMAT_PAGE LCX_IAM | Vorbereiten der IAM-Seite für die Datenaufnahme |
| 4 | LOP_MODIFY_ROW LCX_IAM | Registrierung der ersten Datenseite in der IAM-Seite |
| 5 + 6 | LOP_ROOT_CHANGE LCX_CLUSTERED | Registrierung von Tabellen-Metadaten in Systemtabellen von Microsoft SQL Server |
| 7 | LOP_FORMAT_PAGE LCX_HEAP | Vorbereiten der Datenseite des Heaps für die Speicherung des Datensatzes |
| 8 | LOP_ROOT_CHANGE LCX_CLUSTERED | Speicherung von Metadaten in Systemtabellen von Microsoft SQL Server |
| 9 | LOP_INSERT_ROWS LCX_HEAP | Eintragen des neuen Datensatzes |
| 10 | LOP_SET_FREE_SPACE LCX_PFS | Aktualisierung des Füllgrads der Datenseite bei PFS-Seite. |
Die Systemseiten und ihre Funktionen habe ich im Artikel „Heaps – Systemstrukturen“ ausführlich beschrieben.
https://www.db-berater.de/2020/04/heaps-systemstrukturen/
Werden weitere Datensätze eingetragen, wird die bestehende Datenseite so lange befüllt, bis sie – prozentual – so voll ist, dass kein neuer Datensatz mehr gespeichert werden kann.
DECLARE @I INT = 2
WHILE @I <= 10000
BEGIN
INSERT INTO dbo.Customers
SELECT * FROM dbo.CustomerAddresses
WHERE Id = @I;
SET @I += 1;
END
GO
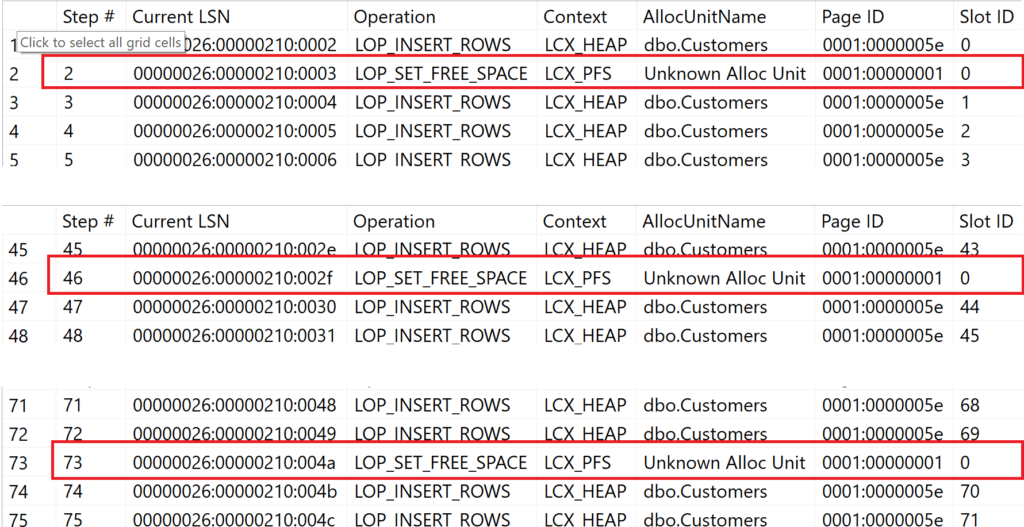
In der Abbildung kann man erkennen, dass Microsoft SQL Server mehrmals die PFS-Seite aktualisieren musste (Zeile 2, 46, 73, …). Dies ist dem Umstand geschuldet, dass die PFS-Seite – nur bei Heaps – den Füllgrad einer Datenseite aktualisieren muss.
Bottleneck PFS
Die PFS-Seite „kann“ für einen Heap zum Bottleneck werden, wenn in möglichst kurzer Zeitfolge viele Datensätze in den Heap eingetragen werden sollen. Wie oft die PFS-Seite aktualisiert werden muss, hängt maßgeblich von der Größe eines zu speichernden Datensatzes ab.
Für Clustered Indizes gilt das nachfolgende Verfahren nicht, da Datensätze in einem Index IMMER gemäß des definierten Indexwertes in die Datenmenge „einsortiert“ werden muss. Die suche nach einem „freien“ Platz erfolgt also nicht über die PFS-Seite sondern über den Wert des Schlüsselattributs!
TRUNCATE TABLE dbo.Customers;
GO
DECLARE @I INT = 1
WHILE @I <= 10000
BEGIN
INSERT INTO dbo.Customers
SELECT * FROM dbo.CustomerAddresses
WHERE Id = @I;
SET @I += 1;
END
GO
Mit dem Skript werden 10.000 Datensätze in den zuvor geleerten Heap eingetragen. Hierbei handelt es sich um Einzeltransaktionen, die in sich abgeschlossen sind. Somit muss Microsoft SQL Server nach jedem Einfügeprozess explizit überprüfen, ob die PFS-Seite aktualisiert werden muss.
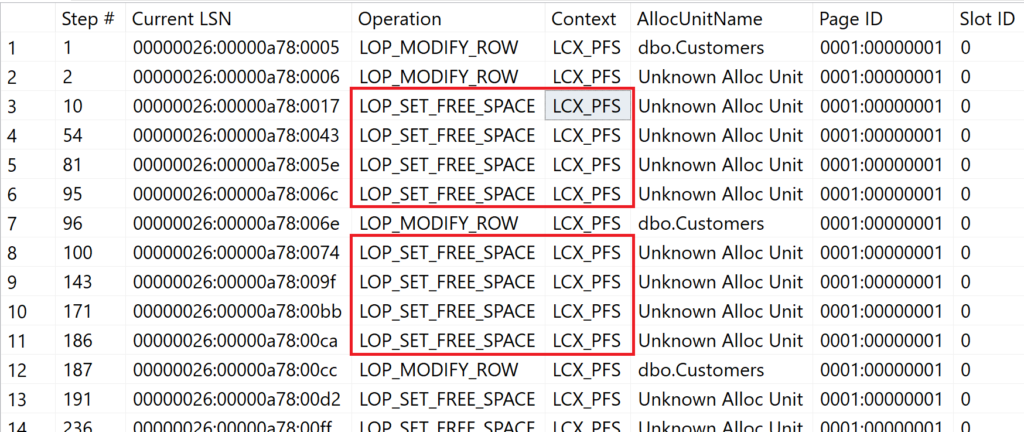
Insgesamt musste – auf Grund der geringen Datensatzlänge – die PFS-Seite 14 Mal aktualisiert werden, um 10.000 Datensätze in den Heap einzutragen.
Das mag auf den ersten Blick nicht sehr viel sein – schließlich wurden ja 10.000 Datensätze eingetragen. Problematisch kann es für die PFS-Seite jedoch werden, sobald mehr als ein Prozess gleichzeitig Daten in die Tabelle eintragen möchte. Um hier einen – ungenau auf Grund der Beschränkungen meines Testsystems! – Trend abzuleiten, habe ich mit Hilfe einer Extended Event Session die Latches auf der PFS-Seite aufzeichnen lassen und anschließend den obigen Code mit einer verschiedenen Anzahl von Clients parallel verarbeitet.
CREATE EVENT SESSION [track pfs contention]
ON SERVER
ADD EVENT sqlserver.latch_suspend_end
(
ACTION(package0.event_sequence)
WHERE
(
sqlserver.database_name = N'demo_db'
AND sqlserver.is_system = 0
AND mode >= 0
AND mode <= 5
)
AND class = 28
AND
(
-- only check for PFS, GAM, SGAM
page_id = 1
OR page_id = 2
OR page_id = 3
OR package0.divides_by_uint64(page_id, 8088)
OR package0.divides_by_uint64(page_id, 511232)
)
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
)
GO
Ich habe jede Versuchsreihe je fünf mal durchgeführt um mögliche Abweichungen auszugleichen. Die Tests wurden auf einem LENOVO XPS 13, 4 Intel Cores i7-6500 und 16 GB RAM durchgeführt.
| Prozesse | 1 | 2 | 4 | 8 | 16 | 32 | 64 |
|---|---|---|---|---|---|---|---|
| PFS-Contention | 0 | 1 | 1 | 7 | 7 | 16 | 68 |
| avg. Wartezeit (µsec) | 0 | 0 | 27 | 305 | 790 | 1.113 | 3.446 |
| Laufzeit (sec) | 4,28 | 5,65 | 7,68 | 13,45 | 23,83 | 55,93 | 165,72 |
| avg (µsec)/ row | 428 | 2.825 | 192 | 16.813 | 16.769 | 17.478 | 25.894 |
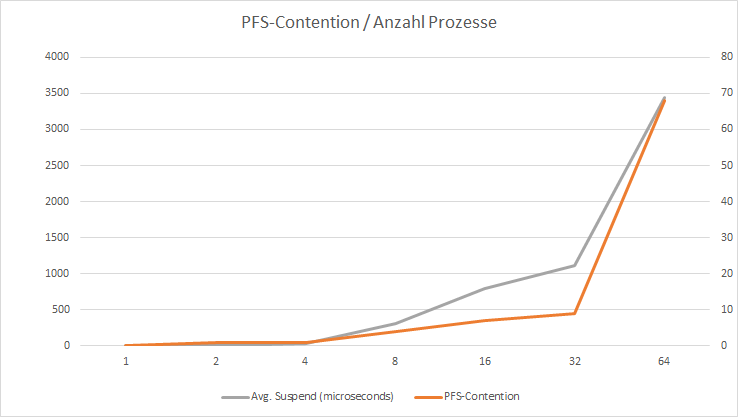
Die von mir durchgeführten Tests sind nicht repräsentativ, weil äußere Einflüsse nicht einwandfrei isoliert wurden. Dennoch kann man aus den Werten deutlich ableiten, dass mit zunehmender Anzahl von gleichzeitigen Prozessen die Konfliktpotentiale auf der PFS-Seite eskaliert.

Sie kennen das Problem aus dem Alltag; Sie müssen länger anstehen, je mehr Leute gleichzeitig die gleiche Ressource (Kasse im Supermarkt) verwenden möchten. Der Engpass kann dadurch entzerrt werden, indem man – wie übrigens auch gängige Praxis bei TEMPDB – mit Hilfe von mehreren Dateien für die Dateigruppe arbeitet, in der sich der Heap befindet.

Den gleichen Workload habe ich mit 4 Datenbankdateien für die PRIMARY-Dateigruppe durchgeführt und die Ergebnisse stellen sich wie folgt dar:

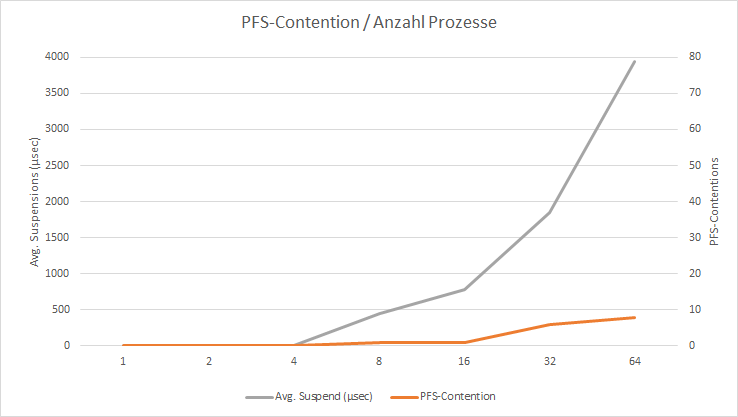
Das hierbei eine Entspannung eintritt, war zu erwarten. Man kann sich das wie eine Situation im Supermarkt vorstellen, bei der zunächst nur eine Kasse geöffnet ist. Sobald viele Kunden im Supermarkt sind, staut es sich vor der Kasse; also werden einfach mehrere Kassen geöffnet und die Situation ist wieder entspannter.
Bottleneck Datenstruktur
Wer mit Heaps arbeitet, muss die Datenstrukturen berücksichtigen. Der größte Unterschied bei der Speicherung von Daten zwischen einen Index und einem Heap ist der Umstand, dass Daten eines Heaps überall gespeichert werden können, während indexierte Tabellen die Daten gemäß des Wertes des Indexattributs speichern müssen. Daraus ergeben sich gleich mehrere Probleme:
- Verschwendung von Speicherplatz auf Grund der prozentualen Berechnung des verfügbaren Speicherplatzes auf einer Datenseite
- Speicherverschwendung im Bufferpool, da nicht die Daten selbst in den Bufferpool geladen werden, sondern die Datenseiten, auf denen sich die Daten befinden
- Erhöhte Belastung der PFS-Seite, wenn Datensätze zu groß sind und somit der prozentuale Füllgrad sehr schnell aktualisiert werden muss.
Nicht genutzter Speicher auf der Datenseite
Die Beispieltabelle ist mit ca. 90.000 Datensätzen gefüllt und bei der Auswertung der Speichernutzung ergibt sich folgende Konstellation:

Mit dem aktuellen Design der Tabelle können 83 Datensätze auf einer Datenseite gespeichert werden. Damit ist eine Datenseite mit ca. 95% gefüllt.
CREATE TABLE dbo.Customers
(
Id INT NOT NULL,
Name CHAR(200) NOT NULL,
CCode CHAR(3) NOT NULL,
State CHAR(20) NOT NULL,
ZIP CHAR(10) NOT NULL,
City CHAR(200) NOT NULL,
Street CHAR(200) NOT NULL
);
GO
Aus den variablen Textattributen werden Textattribute mit fester Zeichenlänge. Dadurch wird die durchschnittliche Satzlänge erhöht.

Das Ergebnis ist logisch – passt weniger auf eine Datenseite, so brauche ich mehr Datenseiten. Jedoch ist auch die durchschnittliche Auslastung einer Datenseite interessant. Die Auslastung einer Datenseite hat sich um 10% verschlechtert!
Diese Problematik tritt nur bei Heaps auf, da sie Daten nicht sortiert ablegen. Um Daten effizient in einem Heap zu speichern, muss die Größe eines Datensatzes berücksichtigt werden!
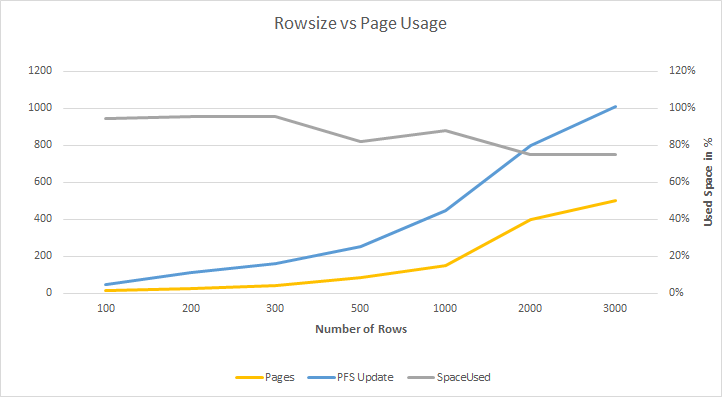
In einem Test mit unterschiedlichen (festen) Satzlängen (X-Achse) wurden jeweils 1.000 Datensätze in einen leeren Heap gefüllt. Ab einer Satzlänge von 300 Bytes verschlechtert sich das Verhältnis zwischen Füllgrad und prozentualer Nutzung einer Datenseite. Die – anfangs – lineare Aktualisierung der PFS-Seite nimmt mit zunehmender Datensatzlänge stark zu.
Dieses Verhalten ist logisch, da mit zunehmender Datensatzlänge weniger Datensätze auf eine Datenseite passen. Je größer ein Datensatz ist, um so mehr ungenutzter Platz kann auf einer Datenseite (und somit auch im Arbeitsspeicher!) verbleiben.
Dieses Problem ist ebenfalls erklärbar, da nach einer Aktualisierung der PFS (0% -> 50% -> 80%) bereits bei einem tatsächlichen Speichervolumen von >4.031 Bytes rechnerisch nur noch 8.030 * 20% = 1.606 Bytes zur Verfügung stehen. Somit passt bereits der nächste Datensatz, der die Grenze von 1.606 Bytes überschreitet, nicht mehr auf die Datenseite und es muss eine neue Datenseite für den Heap bereitgestellt werden.
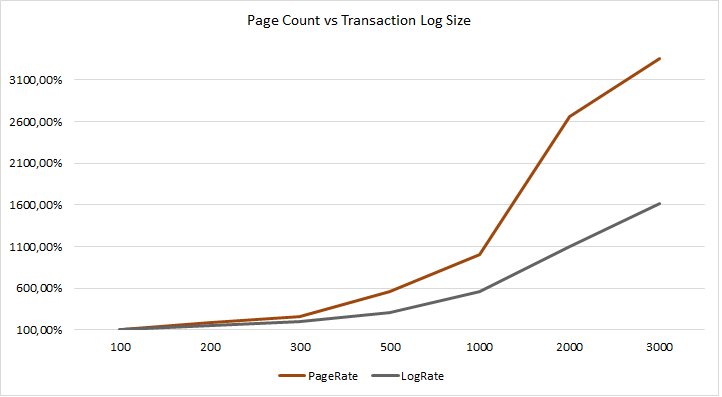
Während die Anzahl der benötigten Datenseiten bei zunehmender Datensatzlänge schnell anwächst, hält sich das Wachstum des Transaktionsvolumens (trotz höherem Datenvolumen) „moderat“ zurück. Das höhere Datenvolumen ist unter anderem den längeren Datensätzen geschuldet. Das Transaktionsvolumen für das Hinzufügen einer neuen Datenseite in einen Heap beträgt 184 Bytes und eine Aktualisierung der PFS schlägt mit 52 Bytes zu Buche, aber die Masse macht’s.
| Rows | Pages | PFS Updates | Log (Bytes) |
|---|---|---|---|
| 100 | 15 | 45 | 5.100 |
| 200 | 28 | 112 | 10.976 |
| 300 | 40 | 160 | 15.680 |
| 500 | 85 | 255 | 28.900 |
| 1.000 | 150 | 450 | 51.000 |
| 2.000 | 399 | 798 | 114.912 |
| 3000 | 504 | 1.008 | 145.152 |
Workload bein Eintragen von Datensätzen
Das Ziel bei der Neuerfassung von Daten in einem Heap ist die Vermeidung der häufigen Aktualisierung der PFS-Seiten und die möglichst vollständige Nutzung des zur Verfügung stehenden Datenbereichs.
Die Aktualisierung der PFS-Seite(n) lässt sich nicht vermeiden, wenn es sich um eine „Fully Logged Operation“ handelt. Hierunter versteht man die Protokollierung jeder Manipulation eines Datensatzes in einem Heap.
Die Optimierung mit BULK-Operationen werden in diesem Artikel nicht berücksichtigt und in einem weiteren Artikel ausführlich beschrieben.
-- Create a demo table
CREATE TABLE dbo.test
(
C1 INT NOT NULL,
C2 CHAR(2500) NOT NULL
);
GO
-- Insert 3 rows into the heap
INSERT INTO dbo.test
(C1, C2)
VALUES
(1, 'Uwe'),
(2, 'Bea'),
(3, 'Katharina');
GO
Das obige Beispiel zeigt eine Tabelle mit einer Datensatzlänge von 2.504 Bytes. Bei einem möglichen Speichervolumen von 8.060 Bytes passen 3 Datensätze in eine Datenseite.
Im Beispiel werden drei Datensätze in EINER Transaktion in die Tabelle eingetragen. Die daraus resultierenden Protokolleinträge zeigen , welche Prozesse Microsoft SQL Server bei der Speicherung der Datensätze verarbeitet hat.
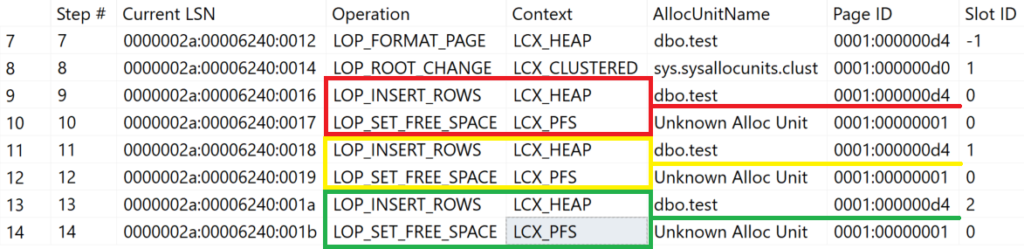
Gemäß der Verwaltung von PFS-Seiten hätte der dritte Datensatz nicht mehr auf die Datenseite geschrieben werden dürfen!
| Aktion | Belegter Speicher | Status von PFS | Freier Speicher |
|---|---|---|---|
| Eintragen „Uwe“ | 2.511 Bytes | 50% | 4.030 Bytes |
| Eintragen von „Bea“ | 5.022 Bytes | 80% | 1.606 Bytes |
| Eintragen von „Katharina“ | 7.533 Bytes | 95% | 403 Bytes |
Nachdem der zweite Datensatz eingetragen wurde, standen – rechnerisch – nur noch 1.606 Bytes zur Verfügung; somit hätte der dritte Datensatz nicht mehr auf die Datenseite gepasst. Microsoft SQL Server hat jedoch diesen Datensatz dennoch auf die gleiche Datenseite geschrieben, da es sich um eine zusammenhängende Transaktion handelt.
Der gleiche Prozess mit drei Einzeltransaktionen stellt sich wie folgt dar:
INSERT INTO dbo.test
(C1, C2)
VALUES (1, 'Uwe');
GO
INSERT INTO dbo.test
(C1, C2)
VALUES (2, 'Bea');
GO
INSERT INTO dbo.test
(C1, C2)
VALUES (3, 'Katharina');
GO
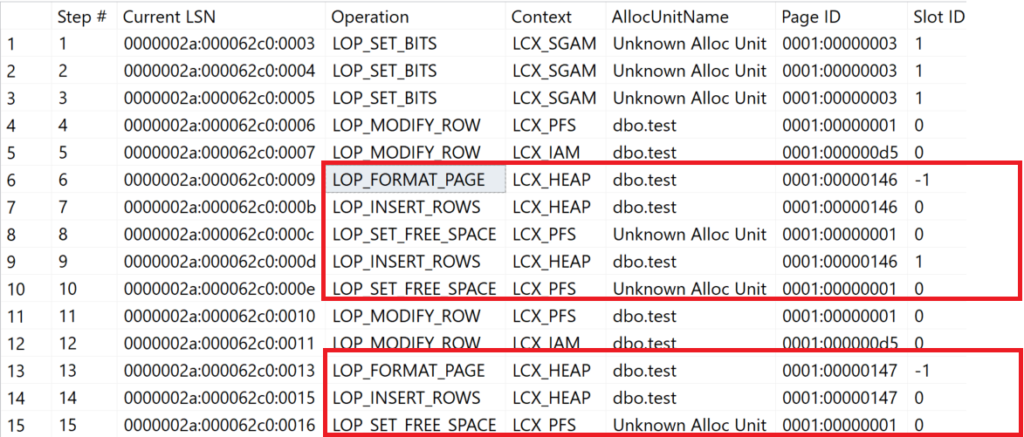
In den Zeilen 6 – 10 wird eine neue Datenseite angelegt und jeweile ein Datensatz eingetragen. Hier schlägt die „schlechte“ Datenstruktur zu. Nachdem der erste Datensatz eingetragen wurde, musste die PFS-Seite auf 50% aktualisiert werden. Nachdem der zweite Datensatz eingetragen wurde, war der konsumierte Speicher höher als 4.030 Bytes. Somit musste Microsoft SQL Server den Prozentsatz auf 80% erhöhen. Rechnerisch blieben somit nur noch 1.612 Bytes frei – ein neuer Datensatz würde nicht mehr auf die Datenseite passen.
Dieser Sachverhalt verdeutlicht, dass Microsoft SQL Server pro Transaktion den Zustand der PFS-Seite abfragt. Wird der Prozess so gestaltet, dass Microsoft SQL Server immer den Inhalt einer ganzen Datenseite eintragen kann, lässt sich der Platzverbrauch optimieren.
Es ist wichtig, zu verstehen, dass die Aktualisierung der PFS-Seite dadurch nicht verhindert wird. Es kann in hochtransaktionalen Systemen immer noch zu einer PFS-Contention kommen.
Optimierung von INSERT-Operationen
Es versteht sich von selbst, dass das Eintragen „aller“ Datensätze in einer Transaktion die schnellste Variante ist; bezogen auf die oben vorgestellten Workloads mit Verarbeitung einzelner Datensätze lasse ich diese Option jedoch unberücksichtigt. OLTP-Systeme sind dadurch gekennzeichnet, dass sie eher einzelne Datensätze speichern.
Die nachfolgend gezeigten Möglichkeiten sind nur dann effektiv, wenn folgende Bedingungen erfüllt sind:
- Die Datensätze haben eine möglichst einheitliche Datensatzgröße (z. B. Protokolleintragungen, Messdaten, etc.
- Es handelt sich um ein System mit hoher Anzahl von Transaktionen
- PFS-Contention ist – bedingt durch viele Prozesse – erkennbar
Die nachfolgenden Szenarien wurden jeweils 10 Mal ausgeführt, um mögliche Abweichungen in den Laufzeiten zu glätten.
Vor jeder Versuchsreihe und jeder Testausführung wurde die Tabelle mit TRUNCATE geleert, um sicherzustellen, dass keine Allokationen für die Tabelle in der anschließenden Testausführung verwendet werden.
Ziel der Versuchsreihen ist das effektive Eintragen von Datensätzen in einen Heap unter Berücksichtigung von
– optimaler Ausnutzung der Datenseiten
– geringer konkurrierender Zugriffe auf PFS-Seite
– Geschwindigkeit
Das Befüllen der Tabelle wird mit vier unterschiedlichen Versuchsreihen realisiert.
- Die erste Versuchsreihe trägt die 10.000 Datensätze einzeln ein und dient als Benchmark für die weiteren Tests
- In der zweiten Versuchsreihe werden 4 Datensätze (maximale Anzahl von Datensätzen/Datenseite) gleichzeitig in die Tabelle eingetragen.
- In der dritten Versuchsreihe werden die Daten in einer Hilfstabelle gespeichert, bevor der Prozess die Daten in die Benutzertabelle speichert.
- Die vierte Versuchsreihe unterscheidet sich von der dritten Versuchsreihe dadurch, dass die Hilfstabelle als InMemory-Tabelle deklariert wird.
Eintragen einzelner Datensätze
Die erste Versuchsreihe dient als Baseline für alle weiteren Lösungsansätze. Hierzu wird eine Stored Procedure verwendet, die – durch einen Parameter definiert – eine vorgegebene Anzahl von Datensätzen in die Tabelle [dbo].[test] einträgt.
CREATE OR ALTER PROC dbo.EnterSingleRowInUserTable
@NumOfRows INT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @I INT = 1;
WHILE @I < @NumOfRows
BEGIN
INSERT INTO dbo.test (C2) DEFAULT VALUES;
SET @I += 1;
END
END;
GO
Diese Prozedur wird im Anschluss von 4 unabhängigen Prozessen gestartet. Hierzu verwende ich das Tool „SQLTest“ von Ramesh Meyyappan. Wer dieses Tool „in action“ erleben möchte, dem seien die Videos von Ramesh auf SQLVideos.com empfohlen.

Die durchschnittliche Laufzeit für 4 simultane Prozesse mit jeweils 10.000 Datensätze beträgt 2.400 ms – 3200 ms. Insgesamt wurden für diesen Prozess 3 Zugriffskonflikte mit einer Dauer von ~50 ms auf der PFS-Seite registriert.

Durchschnittlich werden 3 Datensätze auf einer Datenseite gespeichert. Der durchschnittliche Füllgrad einer Datenseite beträgt 76%.
Eintragen mehrerer Datensätze
Die nächste Versuchsreihe wird so gestaltet, dass gleichzeitig so viele Datensätze in die Benutzertabelle geschrieben werden, wie maximal auf eine Datenseite passen. In Testumgebungen ist das natürlich ein leichtes Spiel; in der Realität sieht leider etwas anders aus. Aus eigener Erfahrung kann ich diese Technik nur empfehlen, wenn zwei Bedingungen zutreffen:
- Die Datensätze haben immer gleiche Größen
- Der Heap verwendet Datentypen mit fester Länge
Die Prozedur für den Testlauf sieht wie folgt aus:
CREATE OR ALTER PROC dbo.EnterMultipleRowsInUserTable
@NumOfRows INT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Loops INT = @NumOfRows / 4
DECLARE @I INT = 0;
WHILE @I < @Loops
BEGIN
INSERT INTO dbo.test (C2)
VALUES
(DEFAULT),
(DEFAULT),
(DEFAULT),
(DEFAULT);
SET @I += 1;
END
END;
GO
Das Ergebnis für vier gleichzeitige Prozesse in SQLTest stellt sich wie folgt dar:
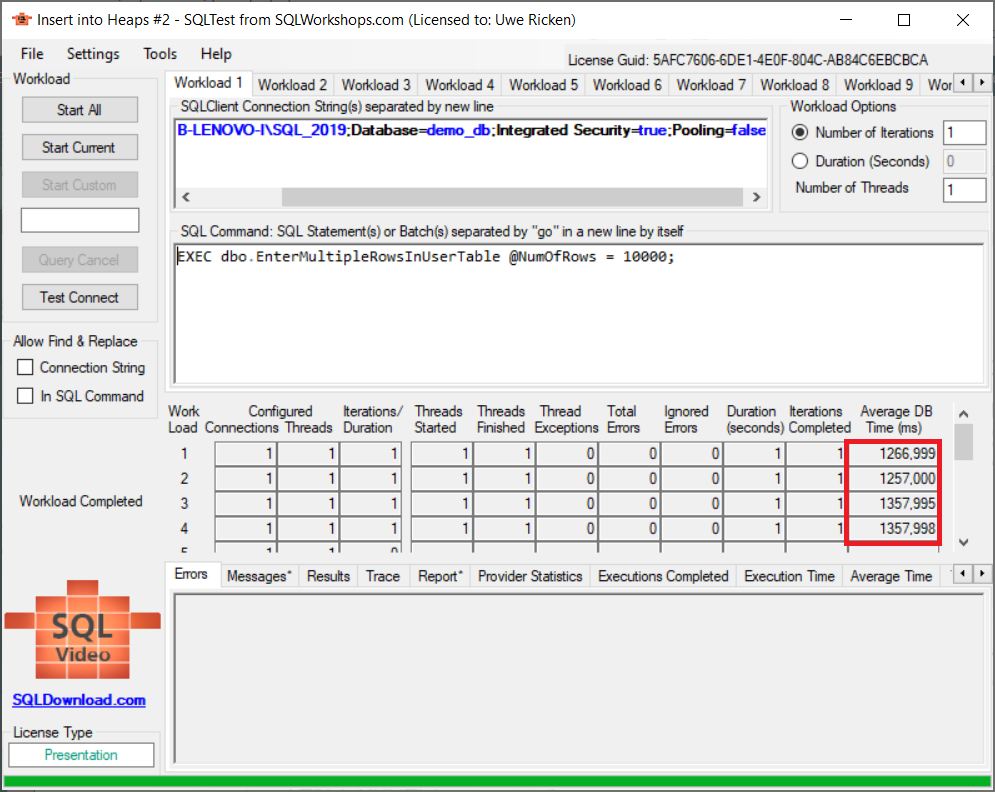
Die durchschnittliche Laufzeit für 4 simultane Prozesse mit jeweils 10.000 Datensätze beträgt 1.309 ms. Insgesamt wurden für diesen Prozess 1 Zugriffskonflikt mit einer Dauer von ~6 ms auf der PFS-Seite registriert. Gekrönt wird dieses – gute – Verhalten mit einer durchschnittlichen Belegung von 99% für jede Datenseite.
Zwischenspeicherung in Hilfstabelle
Der Grundgedanke dieser Testreihe ist die optimale Nutzung der Datenseiten in einem Heap um Speicherressourcen zu schonen. Zunächst wird eine Hilfstabelle in der Datenbank angelegt. das Attribut [SPID] wird dazu verwendet, die durch den Prozess eingetragenen Datensätze zu identifizieren. Ein Non Clustered Index dient der optimierten Suche nach den Datensätzen, die in die Benutzertabelle übertragen werden sollen.
Auf den Einsatz eines Clustered Index wurde hier verzichtet, um Page Splits zu vermeiden!
IF OBJECT_ID(N'dbo.HelperTable', N'U') IS NOT NULL
DROP TABLE dbo.HelperTable;
GO
CREATE TABLE dbo.HelperTable
(
SPID SMALLINT NOT NULL DEFAULT (@@SPID),
C2 CHAR(2000) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX nix_HelperTable_SPID
ON dbo.HelperTable (SPID);
GO
Die Prozedur für den Workload sieht wie folgt aus:
CREATE OR ALTER PROC dbo.EnterSingleRowsInHelperTableDiskBased
@NumOfRows INT
AS
BEGIN
SET NOCOUNT ON;
DECLARE @I INT = 0;
-- Make sure no rows with my SPID are in the helper table
DELETE dbo.HelperTable WHERE SPID = @@SPID;
WHILE @I < @NumOfRows
BEGIN
INSERT INTO dbo.HelperTable (C2) VALUES ('Test');
SET @I += 1;
END
-- Transfer the data into user table!
INSERT INTO dbo.test (C2)
SELECT C2
FROM dbo.HelperTable
WHERE SPID = @@SPID;
END;
GO
Zunächst wird sichergestellt, dass sich keine Datensätze mit der SPID des ausführenden Prozesses in der Hilfstabelle befinden. Nachdem die Datensätze in die Hilfstabelle eingetragen wurden, werden sie vollständig in die Benutzertabelle eingetragen. Die Ausführung der vier Workloads mit SQLTest stellt sich wie folgt dar:
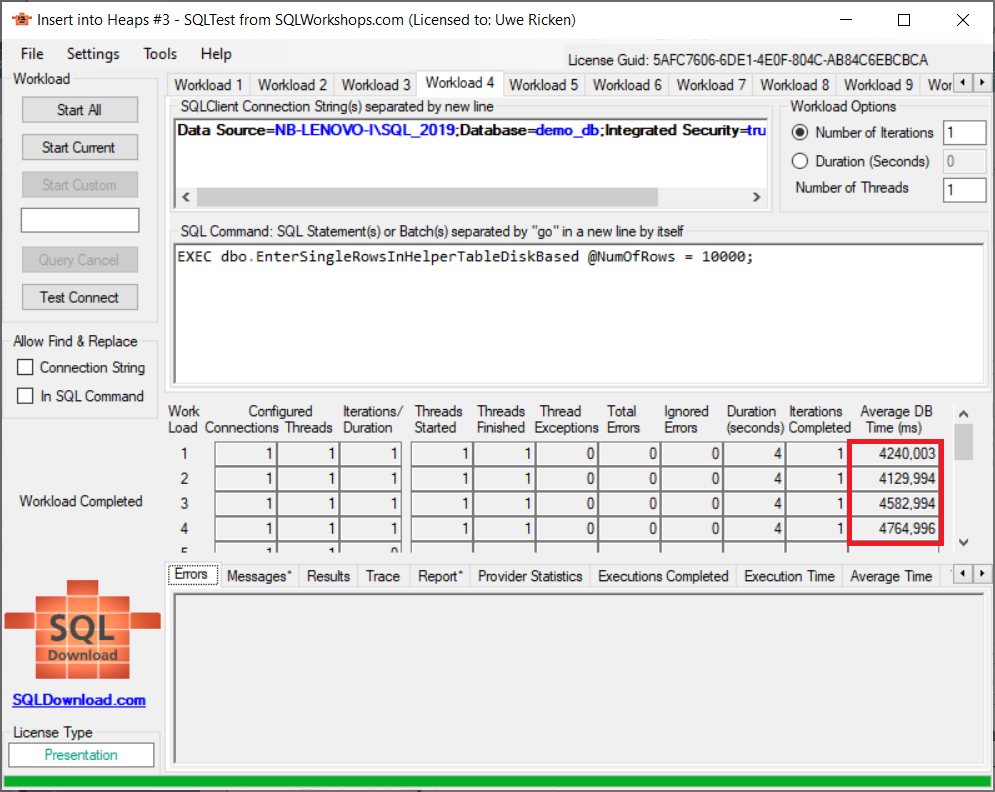
Das Ergebnis überrascht nicht! Die Laufzeit für die Prozesse hat sich massiv verlängert. Zwar werden nun alle Datenseiten mit einer durchschnittlichen Befüllung von 99% verwendet; das geschieht aber auf Kosten der Laufzeit sowie des Ressourcenverbrauchs.
- Die PFS-Contention wurde auf die Hilfstabelle verlagert
- Beim Schreiben von Datensätzen muss sowohl die Hilfstabelle als auch der Non Clustered Index geschrieben werden – somit mehr Schreiblast
- Das Übertragen der Daten von der Hilfstabelle in die Benutzertabelle ist nicht optimal, da eine Tabellensperre (Lock Escalation) angewendet wird.
Während die erste Testreihe mit Unterstützung einer Hilfstabelle jeden Datensatz separat eingetragen hat, wurde für die zweite Testreihe eine Prozedur entwickelt, die jeweils 4 Datensätze in die Hilfstabelle einträgt, bevor alle Daten in die Benutzertabelle übertragen werden.
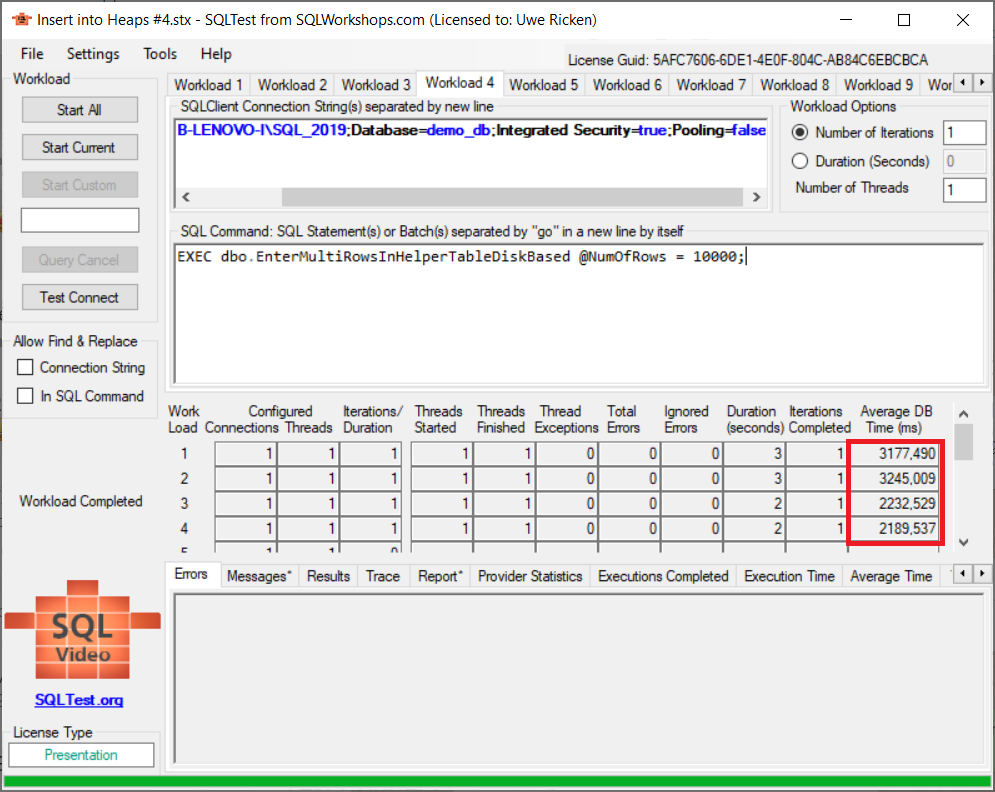
Das Testergebnis sieht vielversprechend aus, da sich die Leistung um ca. 30% verbessert hat. Die Laufzeit allein ist jedoch das Kriterium für eine effiziente Bearbeitung der Daten. Ein Blick hinter die Kulissen (PFS-Contention) zeigt, warum „nur“ 30% Verbesserung eingetreten ist.
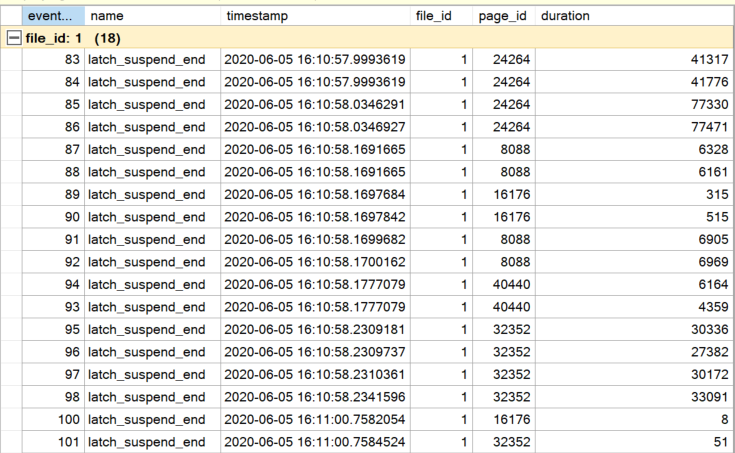
Die durchschnittliche Anzahl von Sperren auf PFS-Seiten lag zwischen 18 und 19 Sperren. Interessant ist neben der hohen Anzahl von Sperren die durchschnittliche Zeit für das Halten der Sperre auf einer PFS-Seite von ~22 ms.
Die hohe Anzahl der Sperren lässt sich nicht dadurch verringern, dass die Last einfach auf eine andere Tabelle (Hilfstabelle) verlagert wird. Sie befindet sich in der gleichen Datenbank und unterliegt den gleichen Regeln, wie die Benutzertabelle. Lediglich die Optimierung des Speichervolumens für jede Datenseite der Benutzertabelle wurde – erneut – optimiert, da die Daten in einer Transaktion in die Benutzertabelle übertragen wurden.
Zwischenspeicherung in InMemory-Tabelle
Die Idee der Zwischenspeicherung der Daten ist nicht so abwegig, wenn man berücksichtigt, dass die PFS-Contention erhalten bleibt, solange es sich um Disk Based Tabellen handelt. Mit Microsoft SQL Server 2016 (SP 1) hat Microsoft jedoch bereits in der Standardversion die Möglichkeit für Entwickler eröffnet, die InMemory-Technologie zu verwenden.
Um die Datenbank für die Verwendung von InMemory vorzubereiten, genügen drei Befehle.
-- Make the database ready for InMemory Technology
ALTER DATABASE demo_db ADD
FILEGROUP [in_memory] CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE demo_db
ADD FILE
(
NAME = [im_fg],
FILENAME= 'S:\InMemory\CustomerOrders'
) TO FILEGROUP [in_memory];
ALTER DATABASE CustomerOrders
SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON
GO
Da die Hilfstabelle nur flüchtige Daten beinhaltet, ist es vollkommen ausreichend, die Hilfstabelle als SCHEMA_ONLY zu bestimmen. Damit werden Daten nicht mehr persistiert und bei einem Neustart des Dienstes steht die leere Tabelle wieder zur Verfügung.
CREATE TABLE dbo.HelperTable
(
SPID SMALLINT NOT NULL DEFAULT (@@SPID)
INDEX nix_HelperTable_SPID NONCLUSTERED HASH
WITH (BUCKET_COUNT = 10000),
C2 CHAR(2000) NOT NULL
)
WITH
(MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_ONLY
);
GO
Die Prozeduren für das Hinzufügen von Daten über eine Hilfstabelle bleiben unberührt, da die „disk based“ Hilfstabelle durch eine „InMemory“ Hilfstabelle mit gleichem Namen ersetzt wurde.
Der Übersichtlichkeit halber habe ich für die InMemory-Versuchsreihen die zuvor erstellten Stored Procedures als …InMemory neu erstellt!
Die Ergebnisse sind beachtenswert.
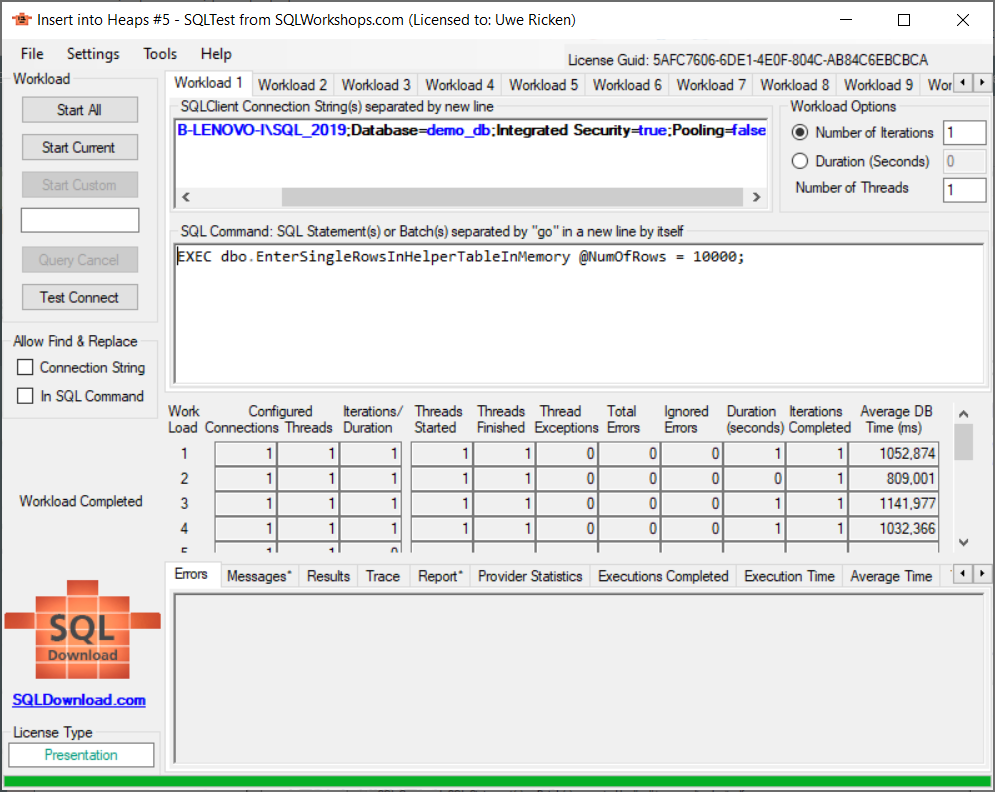
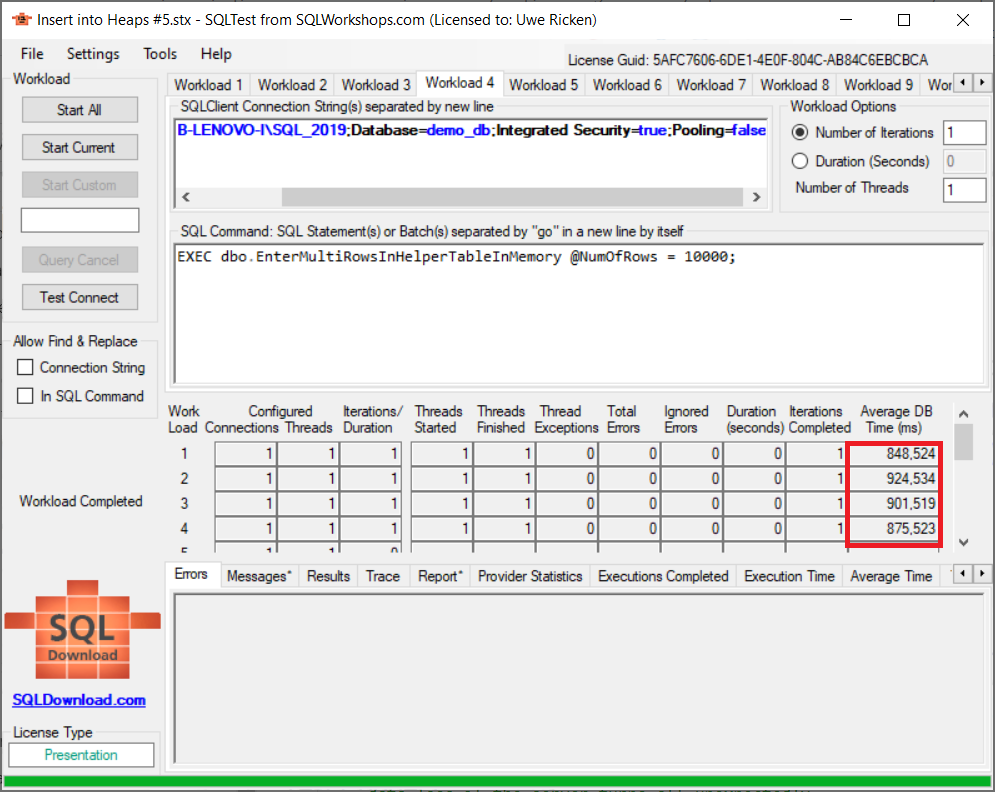
Zusammenfassung der Testergebnisse
| Operation | Datenseiten | belegter Speicher | Laufzeit ms | Latch Contention | Latchdauer ms |
|---|---|---|---|---|---|
| Single Row Operation | 12.796 | 78% | 2.996 | 3 | 50 |
| Multi Row Operation | 10.049 | 99% | 1.309 | 1 | 6 |
| Single Row (Helper on Disk) | 10.001 | 99% | 4.428 | 6 | 5 |
| Multi Row (Helper on Disk) | 10.001 | 99% | 2.710 | 19 | 20 |
| Single Row (Helper InMemory) | 10.001 | 99% | 1.239 | 0 | 0 |
| Multi Row (Helper InMemory) | 10.001 | 99% | 887 | 0 | 0 |
Die Testergebnisse zeigen, dass eine Kombination aus „Zwischenlager“ – definiert als InMemory-Tabelle in Kombination mit der Benutzertabelle die beste Performance sowie Ausnutzung von Speicherplatz bietet.
Bietet sich jedoch nicht die Möglichkeit der Verwendung der InMemory-Technologie, sollte als zweite Option immer versucht werden, in einer Transaktion eine vollständige Datenseite zu befüllen. Hierzu ist es jedoch erforderlich, dass die Datenstruktur sorgfältig untersucht wird.
Ich empfehle bei Verwendung von Heaps nach Möglichkeit den Verzicht auf Datentypen mit variablen Längen, da sie die Kalkulation einer Datensatzlänge erschweren, wenn sich die Textlängen bei jedem Datensatz verändern.
Herzlichen Dank für’s Lesen!





