Although an index should provide a fast query, Microsoft SQL Server either does not want to use that index at all or does not want to use it optimally. The cause is not SQL Server or the index but think about the correct data types for your predicates in your queries!
Inhaltsverzeichnis
A large number of applications allow customers to customize applications to meet their requirements. Very often these applicatinos are ERP systems. I would like to use such a case in the following example.
We need a new attribute
This is usually how it starts. A new attribute is added to a table that will be used as a query parameter in the future.
I am using the table [dbo].[customers] from my database ERP_Demo that I use in my workshops.
A new attribute called [char_c_custkey] is added that stores the customer number as text.
/*
Create a new attribute which stores the c_custkey as a varchar(10)
*/
IF NOT EXISTS
(
SELECT *
FROM sys.columns AS c
WHERE name = 'char_c_custkey'
AND c.object_id = OBJECT_ID(N'dbo.customers', N'U')
)
ALTER TABLE dbo.customers
ADD [char_c_custkey] VARCHAR(10) NOT NULL
CONSTRAINT df_char_c_custkey DEFAULT ('--');
GO
/* Fill the new column with data */
UPDATE dbo.customers WITH (TABLOCKX)
SET char_c_custkey = CAST(c_custkey AS VARCHAR(10))
WHERE char_c_custkey <> CAST(c_custkey AS VARCHAR(10));
GO
/*
and create an index on the new attribut for the demo queries.
*/
IF NOT EXISTS
(
SELECT *
FROM sys.indexes AS i
WHERE name = N'nix_customers_char_c_custkey'
AND i.object_id = OBJECT_ID(N'dbo.customers')
)
CREATE NONCLUSTERED INDEX nix_customers_char_c_custkey
ON dbo.customers (char_c_custkey)
WITH (DATA_COMPRESSION = PAGE);
GO
![The picture shows the output of the table with the columns [c_custkey], [c_mktsegment], [c_nationkey], [c_name], [c_phone], [c_accbal] and the new column [char_c_custkey]](https://www.db-berater.de/wp-content/uploads/2024/11/image-12.png)
Quod erat demonstrandum
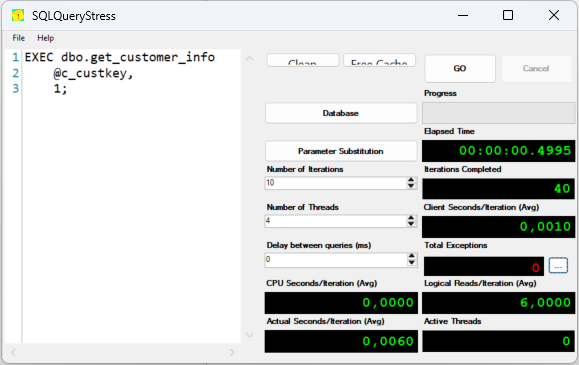
To prove the differences between using correct data types and incorrect data types for the predicate, a stored procedure is used to which a customer key with the correct data type is passed. A second parameter controls whether the attribute [c_custkey] (correct data type) or [char_c_custkey] should be used.
/*
Let's create a stored procedure which will be used with SQLQueryStress
to run it with multiple threads against the database
*/
CREATE OR ALTER PROCEDURE dbo.get_customer_info
@c_custkey BIGINT,
@use_wrong_datat_type BIT = 0
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @use_wrong_datat_type = 0
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment,
char_c_custkey
FROM dbo.customers
WHERE c_custkey = @c_custkey;
ELSE
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment,
char_c_custkey
FROM dbo.customers
WHERE char_c_custkey = @c_custkey;
END
GO
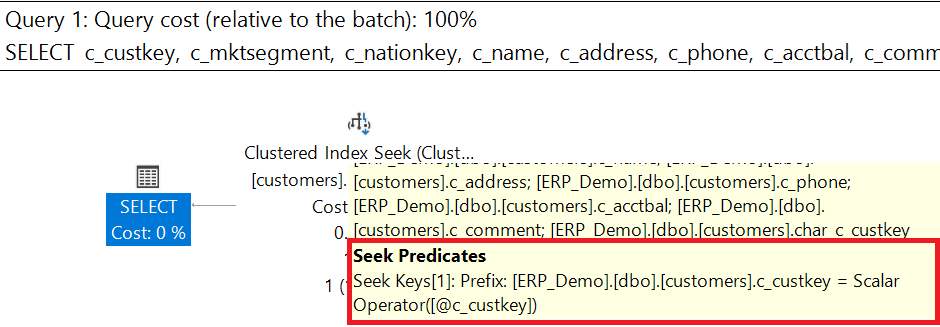
Execution Plan with correct data type
The execution plan uses an optimal INDEX SEEK on the primary key (clustered index) to find the record. The query executes efficiently/quickly because it can specifically search for the value in the index.
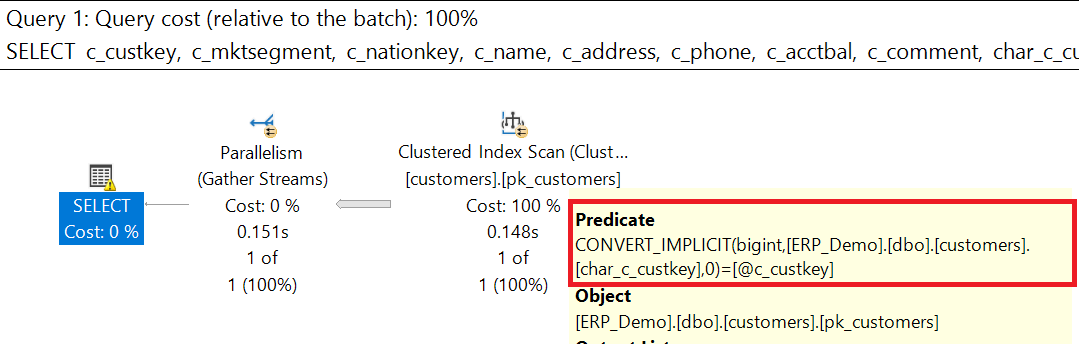
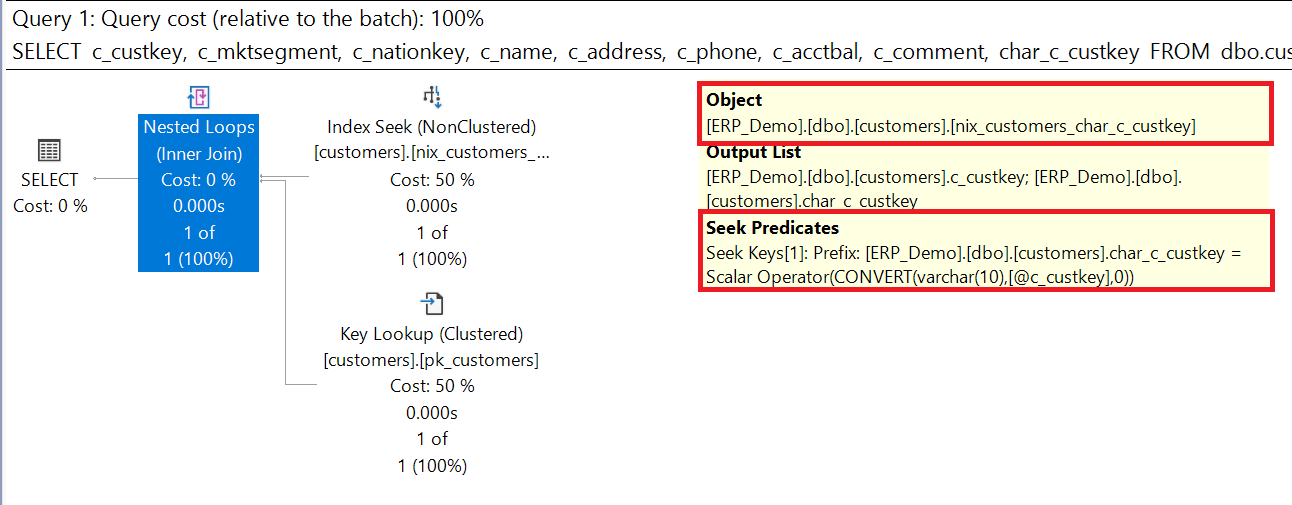
Execution Plan with wrong data type
If the query is executed with the parameter against the attribute with the inappropriate data type, the performance of the query deteriorates.
Microsoft SQL Server must adjust the data type on one side so that there is a match between the data types. In the example, the attribute with data type VARCHAR(10) is converted to a BIGINT (convert_implicit).
| Execution statistics for the bad plan | Execution statistics for the good plan |
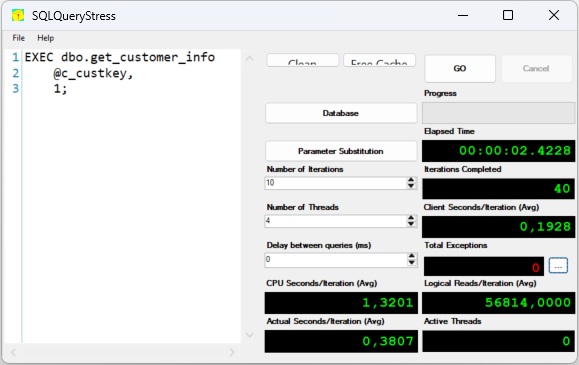 | 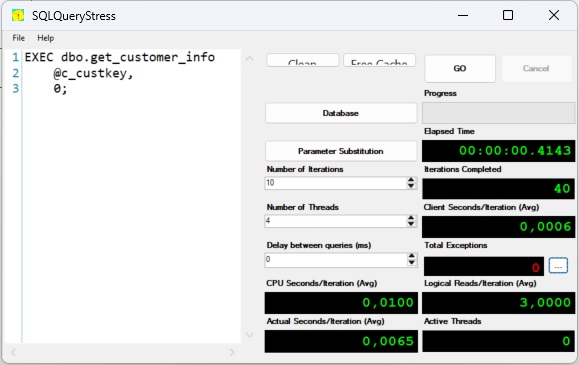 |
| Because the table must be scanned, the average runtime of the query is about 200 ms. | If an efficient index can be used, the average runtime is reduced to < 1ms. |
Why does the efficiency of the query change?
Computers use precedences when using different data types. For example, numeric data types are easier for a CPU to manage; they have a „higher“ precedence than, for example, string data types. These rules also apply to a database system, in which the data types are applied in a hierarchy.
If there is a mismatch between different data types, the database system converts the „lower“ data type to the „higher“ data type.
This can cause problems if, for example, you try to convert text to an integer.
The order of the data types is fixed and Microsoft has documented the order here:
https://learn.microsoft.com/en-us/sql/t-sql/data-types/data-type-precedence-transact-sql

Let’s remember the data types used in the example. The attribute [char_c_custkey] stores an attribute that stores the value as a string. The parameter passed to the procedure is a BIGINT.
According to the list in the documentation, the BIGINT data type has a higher ranking position than a VARCHAR; it follows that SQL Server must convert the VARCHAR to a BIGINT! The attribute [char_c_custkey] is „victim“ and the stored information is converted to a BIGINT so that the values can be compared with the predicate. The result is that the entire table gets scanned!
Solution to the problem
It is important to consider the correct data types. There are two ways to solve this problem:
- Use an identical data type for parameters and attributes
- Avoid conversion on the attribute side by converting the variable.
The data type cannot be changed because it is specified by the stored procedure. But it is possible to convert the variable IN the procedure.
CREATE OR ALTER PROCEDURE dbo.get_customer_info
@c_custkey BIGINT,
@use_wrong_datat_type BIT = 0
AS
BEGIN
SET NOCOUNT ON;
SET XACT_ABORT ON;
IF @use_wrong_datat_type = 0
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment,
char_c_custkey
FROM dbo.customers
WHERE c_custkey = @c_custkey;
ELSE
SELECT c_custkey,
c_mktsegment,
c_nationkey,
c_name,
c_address,
c_phone,
c_acctbal,
c_comment,
char_c_custkey
FROM dbo.customers
WHERE char_c_custkey = CAST(@c_custkey AS VARCHAR(10));
END
GO
By converting the variable from a BIGINT to a VARCHAR using CAST, the Quey Optimizer takes the decision away from it.
The data type of the predicate now corresponds to the data type of the attribute and the index can be used efficiently.
Thank you for reading!





