How often do you read on blogs and/or social media platforms that it simplifies work to use „1 = 1“ as the first statement in a WHERE clause, followed by „AND…“ in subsequent lines? Some comments point out that it’s pointless, while others claim it’s either good or bad. This blog post will show whether it’s beneficial, detrimental, or even irrelevant when using this technique in Microsoft SQL Server (!).
Inhaltsverzeichnis
Common Arguments for using 1 = 1
- Avoiding syntax errors
- Enabling programmatic filter stacking
- Supporting dynamic query generation in tools and applications
Common Arguments against using 1 = 1
- Redundant logic: Adds a condition that always evaluates to true.
- No performance gain: SQL Server and other engines ignore it during optimization.
- Clutters code: Makes queries harder to read for those unfamiliar with the pattern.
- Better alternatives: Use query builders, ORMs, or conditional logic in code.
Is there any performance benefit?
Short and sweet answer: No, it makes NO difference to the query optimizer whether you use this condition or not. SQL Server and other RDBMS engines optimize away tautological conditions like 1 = 1 during query compilation.
Example
For the proof, I use a simple query on a table. Since „1 = 1“ has other – negative – consequences, I try to keep the query as simple as possible in order to be able to present the proofs.
SELECT c_custkey,
c_name
FROM dbo.customers
WHERE c_custkey = 10
OPTION (
RECOMPILE,
QUERYTRACEON 3604,
QUERYTRACEON 8605
);
*** Converted Tree: ***
LogOp_Project QCOL: [ERP_Demo].[dbo].[customers].c_custkey QCOL: [ERP_Demo].[dbo].[customers].c_name
LogOp_Select
LogOp_Get TBL: dbo.customers dbo.customers TableID=565577053 TableReferenceID=0 IsRow: COL: IsBaseRow1000
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [ERP_Demo].[dbo].[customers].c_custkey
ScaOp_Const TI(bigint,ML=8) XVAR(bigint,Not Owned,Value=10)
AncOp_PrjList
The query looks for customers with a c_custkey = 10. In the „Converted Tree“ pay attention to lines 5-7. They show that the comparison operator is „<=“ (x_cmpEq) and that the search must be performed in column [c_custkey]. The search is restricted to a scalar operator (ScaOp_Const) with the following Type Information (TI):
- Data type: BIGINT
- Value: 10
SELECT c_custkey,
c_name
FROM dbo.customers
WHERE 1 = 0
AND c_custkey = 10
OPTION (
RECOMPILE,
QUERYTRACEON 3604,
QUERYTRACEON 8605
);
*** Converted Tree: ***
LogOp_Project QCOL: [ERP_Demo].[dbo].[customers].c_custkey QCOL: [ERP_Demo].[dbo].[customers].c_name
LogOp_Select
LogOp_Get TBL: dbo.customers dbo.customers TableID=565577053 TableReferenceID=0 IsRow: COL: IsBaseRow1000
ScaOp_Comp x_cmpEq
ScaOp_Identifier QCOL: [ERP_Demo].[dbo].[customers].c_custkey
ScaOp_Const TI(bigint,ML=8) XVAR(bigint,Not Owned,Value=10)
AncOp_PrjList
Is there a difference in the query tree? No, there is no difference; both query variants are treated identically by the query optimizer. From a performance perspective, it makes absolutely no difference whether you write your queries with or without the comparison!
Important!
Trace Flag 8605 in SQL Server enables internal debugging output that shows the query tree after the algebrizer phase. This trace flag is undocumented and primarily used for diagnostic or research purposes.
Dynamic Query Generation
For dynamic queries constructed using string concatenation, the „1 = 1“ option is useful, provided the developer ensures that the concatenation is performed using variables and not direct text concatenation. Warning: SQL injection!
DECLARE @Country NVARCHAR(50) = 'Germany';
DECLARE @MinAge INT = NULL;
DECLARE @Status NVARCHAR(20) = 'Active';
DECLARE @SQL NVARCHAR(MAX);
SET @SQL = 'SELECT * FROM Customers WHERE 1 = 1';
IF @Country IS NOT NULL
SET @SQL += ' AND Country = @Country';
IF @MinAge IS NOT NULL
SET @SQL += ' AND Age >= @MinAge';
IF @Status IS NOT NULL
SET @SQL += ' AND Status = @Status';
-- Execute with parameters
EXEC sp_executesql
@SQL,
N'@Country NVARCHAR(50), @MinAge INT, @Status NVARCHAR(20)',
@Country = @Country,
@MinAge = @MinAge,
@Status = @Status;
GO
Disadvantage of 1 = 1 for Simple Parameterization
Simple Parameterization in SQL Server occurs when the query engine automatically replaces literal values with parameters during query compilation – but only under specific conditions. This helps improve plan reuse and reduce compilation overhead.
When Does Simple Parameterization Happen?
SQL Server applies simple parameterization when:
- The query is eligible
- The database is using the default setting
- The query contains simple equality predicates with constant literals
Example
SELECT c_custkey,
c_name
FROM dbo.customers
WHERE c_custkey = 10;
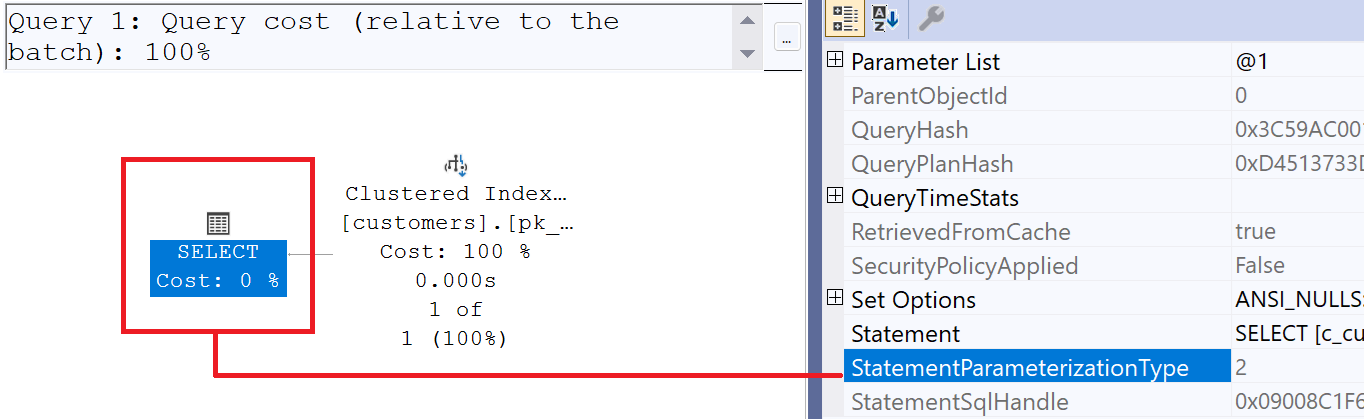
If the query is executed with the option „1 = 1“, this automatically results in execution without parameterization, because the expression is too complex for Microsoft SQL Server to execute using Simple Parameterization.If the query is executed without the „1 = 1“ option, Microsoft SQL Server may replace the literal in the execution plan with a variable.
SELECT c_custkey,
c_name
FROM dbo.customers
WHERE 1 = 1
AND c_custkey = 10;
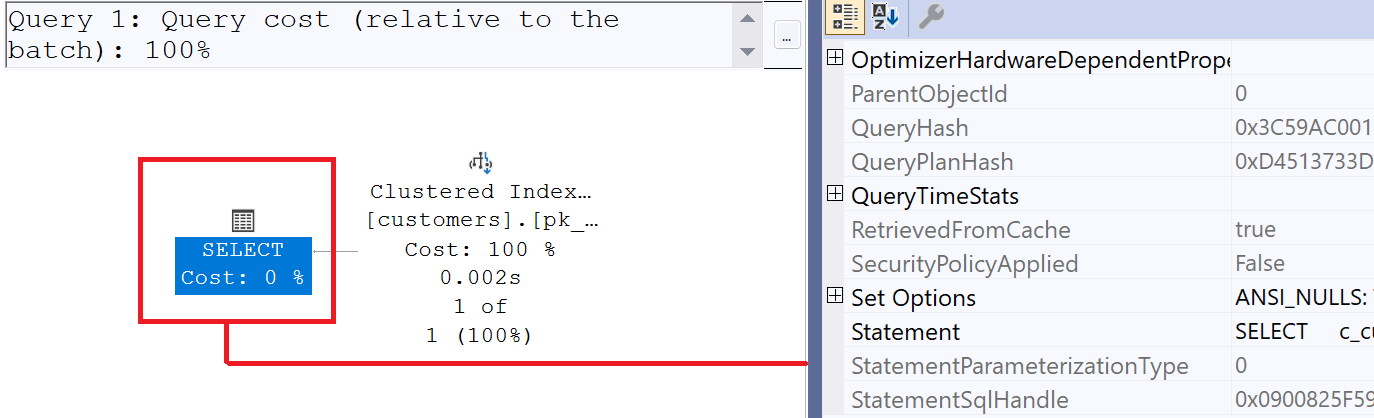
The disadvantage becomes apparent in the plan cache of Microsoft SQL Server. With Simple Parameterization, a once-generated execution plan can be reused. An ad-hoc plan without a prepared statement is recompiled and stored in the plan cache every time the literal being searched for changes.
/* Get an inside into the cached plans! */
SELECT CP.usecounts,
CP.cacheobjtype,
CP.objtype,
CP.size_in_bytes,
ST.[text],
QP.query_plan
FROM sys.dm_exec_cached_plans AS CP
OUTER APPLY sys.dm_exec_sql_text (CP.plan_handle) AS ST
OUTER APPLY sys.dm_exec_query_plan (CP.plan_handle) AS QP
WHERE ST.[text] NOT LIKE '%dm_exec_cached_plans%'
AND ST.[text] LIKE '%customers%'
ORDER BY
CP.usecounts ASC;
GO

Note the size of the execution plan in line 1; it is 50% larger than the execution plan in line 3. Line 2 does not contain an ad-hoc plan but a prepared plan. The reason the execution plan in line 3 consumes less memory is that it obtains its information from the prepared statement and does not need to be recompiled.
Conclusion
Three key takeaways from the tests are:
- Microsoft SQL Server can detect „1 = 1“ and hides this information when creating an execution plan. It has NO effect on the query itself.
- This technique can help with dynamic query codes as long as it uses variables in the query text instead of dynamically added literals!
- If the query is a simple query with an „=“ operator in the WHERE clause to extract data, 1 = 1″ can be counterproductive, as it is no longer considered a „simple“ query, and Microsoft SQL Server cannot use „Simple Parameterization“. This leads to the plan cache being agressivly filled with execution plans.
Note
This discussion is irrelevant for database systems like PostgreSQL. PostgreSQL creates and stores execution plans per session, not per database server!
Thank you for reading!






Great post! One thing: I am on a solo campaign to get people to use „prepared SQL“ or „anonymous stored procedures“ when referring to properly parameterized SQL run through sp_executesql. I think we should reserve the term „dynamic SQL“ only for anything (including stored procedures that include parameters in one concatenated string) that is run as unprepared strings.
The reason for this is that non-dev DBAs and other decision makers who don’t understand SQL as well as you do hear that „dynamic SQL is bad,“ and they think that also means that „sp_executesql is bad,“ especially when we call it dynamic SQL.
I invented the phrase „anonymous stored procedures“ at GoDaddy 19 years ago, and it has been tremendously helpful in changing the culture there to distinguish between non-prepared and prepared SQL.
Thoughts?