Immer wieder hört oder liest man, dass ein Clustered Index möglichst fortlaufend/aufsteigend organisiert sein soll. Am besten sei immer ein Clustered Index mit möglichst kleinen Datentypen (z. B. INT); außerdem sollte ein Clustered Index nach Möglichkeit nicht aus zusammengesetzten Attributen bestehen. Die mit Abstand größte Abneigung besteht bei vielen Entwicklern gegen den Einsatz von GUID als Clustered Keys. Die generelle “Verteufelung” von GUID ist nicht gerechtfertigt – GUID sind in einigen Workloadmustern performanter als die “Heilige Kuh” IDENTITY (1, 1).
Die Vorbehalte vieler SQL Experten gegen GUID kann man z. B. in den kontroversen Foreneinträgen zu dem Artikel “^Are there that many GUIDs?” von Steve Jones auf sqlservercentral.com nachlesen.
Der nachfolgende Artikel soll zeigen, dass der schlechte Ruf, der einer GUID vorausgeht, nicht immer gerechtfertigt ist sondern seiner Nutzung immer eine sorgfältige Betrachtung des Workloads vorausgehen sollte. Pro und Contra GUID soll der Artikel etwas näher beleuchten.
Testumgebung
Für die nachfolgenden Demonstrationen und Diskussionen wird eine Datenbank mit einer Initialgröße von 1 GB erstellt. In dieser Datenbank befinden sich zwei Tabellen mit identischer Datensatzlänge sowie eine Stored Procedure, die im Beispiel von jeweils 200 Benutzern gleichzeitig ausgeführt werden wird.
CREATE DATABASE [demo_db]
ON PRIMARY
(
NAME = N'demo_db',
FILENAME = N'F:\DATA\demo_db.mdf',
SIZE = 1000MB,
MAXSIZE = 20000MB,
FILEGROWTH = 1000MB
)
LOG ON
(
NAME = N'demo_log',
FILENAME = N'F:\DATA\demo_db.ldf',
SIZE = 500MB,
MAXSIZE = 1000MB,
FILEGROWTH = 100MB
);
GO
ALTER AUTHORIZATION ON DATABASE::demo_db TO sa;
ALTER DATABASE [demo_db] SET RECOVERY SIMPLE;
GO
Die Initialgröße von 1 GB sorgt bei den Tests dafür, dass keine Abweichungen bei der Messung entstehen, weil die Datenbank auf Grund der hohen Datenmenge wachsen muss. Die Größe von 500 MB für die Protokolldatei ist ausreichend, da die Datenbank im Modus “SIMPLE” betrieben wird.
USE demo_db;
GO
-- Tabelle mit fortlaufender Nummerierung als Clustered Index
CREATE TABLE dbo.numeric_table
(
Id INT NOT NULL IDENTITY(1, 1),
c1 CHAR(400) NOT NULL DEFAULT ('just a filler'),
CONSTRAINT pk_numeric_table PRIMARY KEY CLUSTERED (Id)
);
GO
-- Tabelle mit zufälligem Clustered Index
CREATE TABLE dbo.guid_table
(
Id uniqueidentifier NOT NULL DEFAULT(NEWID()),
c1 CHAR(388) NOT NULL DEFAULT ('just a filler'),
CONSTRAINT pk_guid_table PRIMARY KEY CLUSTERED (Id)
);
GO
Beide Tabellen haben eine identische Datensatzlänge um Abweichungen bei den Messungen zu verhindern, weil unterschiedliche Datensatzlängen dazu führen können, dass mehr oder weniger Datensätze auf eine Datenseite passen. Jeder Datensatz hat eine Länge von 411 Bytes. Da ein [uniqueidentifier] eine Länge von 16 Bytes besitzt, muss lediglich der Füllbereich um 12 Bytes reduziert werden.
-- Procedure for insertion of 1,000 records in dedicated table
CREATE PROC dbo.proc_insert_data
@type varchar(10)
AS
SET NOCOUNT ON
DECLARE @i INT = 1;
IF @type = 'numeric'
BEGIN
WHILE @i <= 1000
BEGIN
INSERT INTO dbo.numeric_table DEFAULT VALUES
SET @i += 1;
END
END
ELSE
BEGIN
WHILE @i <= 1000
BEGIN
INSERT INTO dbo.guid_table DEFAULT VALUES
SET @i += 1;
END
END
SET NOCOUNT OFF;
GO
Die Prozedur hat eine triviale Aufgabe; sie soll – abhängig vom übergebenen Parameter @type – jeweils 1.000 Datensätze pro Aufruf in eine der beiden Tabellen eintragen. Wird der Prozedur der Parameter @type mit dem Wert ’numeric‘ übergeben, trägt die Prozedur entsprechende Daten in die Tabelle mit fortlaufendem Clustered Key ein während bei einem anderen Parameterwert Daten in die Tabelle mit zufälligem Clustered Key eingetragen werden.
Vor jeder Ausführung der Prozedur werden die Statistiken in sys.dm_os_wait_stats gelöscht. Dadurch sollen die während der Laufzeit registrierten Wartevorgänge analysiert werden:
DBCC SQLPERF('sys.dm_os_wait_stats', 'CLEAR');
GO
Während die Prozedur ausgeführt wird, wird in einer zweiten Sitzung in SQL Server Management Studio die folgende Abfrage wiederholt ausgeführt:
SELECT DOWT.session_id,
DOWT.wait_duration_ms,
DOWT.wait_type,
DOWT.resource_description,
DOWT.blocking_session_id
FROM sys.dm_exec_sessions AS DES INNER JOIN sys.dm_os_waiting_tasks AS DOWT
ON (DES.session_id = DOWT.session_id)
WHERE DES.is_user_process = 1;
GO
Um einen Workload mit mehreren Clients zu simulieren, wird das Tool “ostress.exe” verwendet. Dieses – von Microsoft kostenlos angebotene Tool – ermöglicht die Simulation von Workloads mit mehreren Clients und ist – insbesondere für PoC-Simulationen – sehr zu empfehlen.
Daten in Tabelle mit fortlaufendem Clustered Key
Zunächst wird die Prozedur für die Ausführung in die Tabelle [dbo].[numeric_table] ausgeführt:

Mit einer vertrauten Verbindung (-E) wird auf den Testserver zugegriffen und die Prozedur [dbo].[proc_insert_data] (-Q) in der Datenbank [demo_db] (-d) für 200 Clients (-n) ausgeführt. Während der Ausführung dieser Prozedur wird mittels sys.dm_os_waiting_tasks überprüft, auf welche Ressourcen Microsoft SQL Server während der Clientzugriffe warten muss. Insgesamt benötigt das Eintragen von 200.000 Datensätzen ~12,500 Sekunden.

Diese Zeitspanne mag für Datenbanken mit geringem Transaktionsvolumen ausreichend sein; jedoch gibt es Systeme, die noch deutlich mehr Datensätze in kürzerer Zeit verarbeiten müssen. Warum also dauert dieser Prozess so lange?
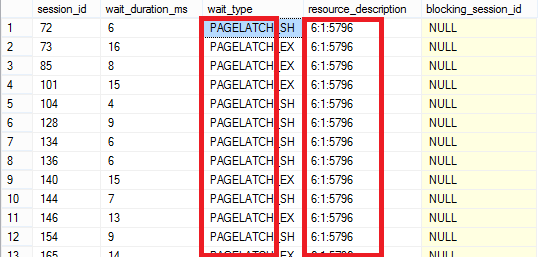
Die obige Abbildung zeigt die wartenden Prozesse während der Ausführung der Prozedur. Es ist deutlich zu erkennen, dass die Mehrzahl der Prozesse auf einen PAGELATCH_xx warten müssen.
PAGELATCH_XX
Als “Latch” bezeichnet man interne, nicht konfigurierbare Sperren, die von Microsoft SQL Server benötigt werden, um bei gleichzeitigem Zugriff (Konkurrierend) die im Speicher befindlichen Strukturen zu schützen. Latches werden häufig mit Locks verwechselt, da ihre Zwecke gleich gelagert aber nicht identisch sind. Ein Latch bezeichnet ein Objekt, das die Integrität der Daten anderer Objekte im Speicher von SQL Server gewährleistet. Sie sind ein logisches Konstrukt, das für einen kontrollierten Zugriff auf eine Ressource sorgt. Im Gegensatz zu Locks sind Latches ein interner SQL Server-Mechanismus. Man kann sie grob in zwei Klassen aufteilen – Buffer Latches und Non-Buffer Latches. Für den in diesem Artikel beschriebenen Fall handelt es sich um Sperren auf Datenseiten, die sich bereits im Buffer Pool befinden. Wer sich intensiver mit Latches beschäftigen möchte, dem sei das Dokument “Diagnosing and Resolving Latch Contention on SQL Server” von Ewan Fairweather und Mike Ruthruff für das weitere Studium empfohlen. Es mag zwar schon älter sein aber sein Inhalt ist auch für die neueren Versionen von Microsoft SQL Server noch relevant!
Auffällig ist, dass alle Prozesse auf die gleiche Ressource warten müssen. Die Wartevorgänge variieren zwischen SH (Shared) und EX (Exclusive) Ressourcen. Diese Wartevorgänge sind der – in diesem Fall sehr schlechten – Eigenschaft des Clustered Index geschuldet. Da die Daten in sortierter Reihenfolge in den Index eingetragen werden müssen, werden alle neuen Datensätze immer am Ende des Index eingetragen. Der Clustered Index repräsentiert die Tabelle selbst und definiert die Sortierung nach einem vorher festgelegten Schlüsselattribut. Wenn dieses Attribut mit einem fortlaufenden Wert befüllt wird, reduziert sich der Zugriffspunkt für Microsoft SQL Server immer auf die letzte Datenseite des Clustered Index im Leaf-Level.

Die Abbildung zeigt den – logischen – Aufbau eines Clustered Index. Aus Darstellungsgründen wurde auf die Beziehung der Datenseiten untereinander verzichtet. Alle Daten werden im Leaf-Level gespeichert. Da das Schlüsselattribut als fortlaufend definiert wurde, müssen ALLE Prozesse auf der letzten Seite des Index ihre Daten eintragen. Wenn – wie in diesem Beispiel gezeigt – mehrere Prozesse gleichzeitig eine INSERT-Operation durchführen, hat das den gleichen Effekt wie das Anstehen an einer Kasse im Supermarkt; man muss warten! Aber ACHTUNG: Das beschriebene Szenario gilt nicht für Workloads mit mehreren Verbindungen!
Fortlaufenden Index-Pages im Clustered Index
Sehr häufig verbindet man mit fortlaufender Nummerierung im Indexschlüssel die Vermeidung von Page Splits. Diese Aussage hat aber nur Bestand, wenn das Eintragen von neuen Datensätzen durch einen einzigen Thread geschieht. Wird jedoch – wie im aktuellen Beispiel – der Einfügevorgang von 200 Benutzern gleichzeitig gestartet, kann eine sequentielle Folge in den Eintragungen nicht mehr gewährleistet werden. Ein Blick in das Transaktionsprotokoll zeigt die Details:
SELECT [Current LSN],
Operation,
Context,
AllocUnitName,
[Page ID],
[Slot ID],
[RowLog Contents 0]
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE AllocUnitName = N'dbo.numeric_table.pk_numeric_table'
ORDER BY
[Current LSN];
Die nachfolgende Abbildung zeigt einen Extrakt aus dem Transaktionsprotokoll, der die Einfügevorgänge in chronologischer Reihenfolge ausgibt.

Hervorzuheben ist die [SLOT ID]! Aus der Slot Id ist erkennbar, dass die Datensätze nicht hintereinander eingetragen wurden, sondern nach dem 5 Eintrag (Zeile 48) ein neuer Datensatz in Slot 1 eingetragen worden ist. Das lässt nur den Rückschluss zu, dass ein kleinerer Indexwert erst später eingetragen wurde. Mit dem nachfolgenden SELECT-Statement werden die eingetragenen Indexschlüssel “entschlüsselt”:
SELECT CAST(0x14 AS INT) AS [Slot_0],
CAST(0x21 AS INT) AS [Slot 1],
CAST(0x22 AS INT) AS [Slot 2],
CAST(0x23 AS INT) AS [Slot 3],
CAST(0x24 AS INT) AS [Slot 4],
CAST(0x20 AS INT) AS [Slot w],
CAST(0x1F AS INT) AS [Slot x],
CAST(0x15 AS INT) AS [Slot y],
CAST(0x1D AS INT) AS [Slot z];
GO
Auf eine vollumfängliche Beschreibung der Strukturen eines Datensatzes kann in diesem Artikel nicht eingegangen werden! Kurz und Knapp gilt für die Berechnung des eingetragenen Wertes für die ID in der Tabelle [dbo].[numeric_table] jedoch folgende Richtlinie:
- Die ersten vier Bytes in [RowLog Contents 0] sind für den Rowheader reserviert und müssen extrahiert werden
- Die nächsten 4 Bytes entsprechen dem Wert, der in das Attribut [ID] (INTEGER) eingetragen wird
- Diese vier Bytes werden “geshifted” und übrig bleibt der Hexadezimalwert für den eingetragenen Dezimalwert
- Die Berechnung des Dezimalwertes erfolgt mittels CAST-Funktion
Das Ergebnis der obigen Abfrage sieht dann wie folgt aus:
![]()
Die ID-Werte sind in der chronologischen Reihenfolge ihres Einfügeprozesses dargestellt. Zunächst wurden die Werte 20, 33, 34, 35, 36 in die Tabelle eingetragen. Das entspricht exakt dem Auszug aus dem Transaktionsprotokoll (siehe [Slot ID]. Mit der sechsten Transaktion wurde ein neuer Datensatz mit dem Wert 32 in die Tabelle eingetragen. Der Clustered Key muss sortiert werden; also wird der Wert 32 in Slot 1 eingetragen. Anschließend wird der Wert 31 eingetragen und der Kreis schließt sich erneut!
Schaut man sich die Verteilung der eingetragenen Datensätze nach chronologischem Muster an, wird schnell klar, dass Page Splits zwangsläufig auftreten müssen. Der Grund für diese gemischte Verteilung ist schnell erkennbar, wenn man versteht, wie Microsoft SQL Server den Wert für IDENTITY ermittelt. Dieses Thema habe ich bereits ausführlich im Artikel “IDENTITY-Werte…–warum wird der Wert um <increment> erhöht, obwohl die Transaktion nicht beendet werden kann?” beschrieben.
Werden nur von einem Benutzer Daten in eine Tabelle eingetragen, wird der Indexschlüssel um jeweils 1 erhöht und der Datensatz wird eingetragen. Wir jedoch – wie im vorliegenden Beispiel – ein System mit hoher Concurrency betrieben, ist das nicht mehr gewährleistet. Die nachfolgende Abbildung zeigt den internen Sachverhalt:

Jeder Thread fordert – sobald er CPU-Zeit erhält – einen IDENTITY-Wert aus dem Pool an. Dieser Prozess ist nicht mehr umkehrbar; einmal einen Wert erhalten, wird dieser Wert von diesem Prozess für den ganzen Einfügezyklus beibehalten! Nachdem der IDENTITY-Wert vergeben wurde, kann der Thread mit diesem erhaltenen Wert den Einfügevorgang beenden. Dazu muss sich jeder Thread (mit dem ihm zugeteilten IDENTITY-Wert in eine Reihe mit anderen Threads anstellen, die ebenfalls auf die Ressource (Datenseite) warten müssen. Hierbei kann es zu Verschiebungen kommen; der Thread mit dem Wert 4 muss warten, weil die Threads mit den Werten 7 und 11 noch vor ihm ausgeführt werden müssen. Wird die Seite vollständig gefüllt, wenn der Thread mit Wert 11 seine Daten gespeichert hat, wird es unweigerlich für den Thread mit Wert 4 zu einem Page Split kommen.
Clustered Index mit zufälligem Schlüssel
Mit dem nachfolgenden Test werden ebenfalls 200.000 Datensätze in die Tabelle [dbo].[guid_table] eingetragen und erneut die Zeiten gemessen.

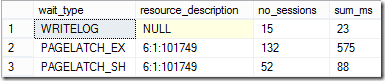
Während der Ausführung der Prozedur werden die wartenden Tasks überprüft und eine abschließende Abfrage über die Wartevorgänge ausgeführt. Insgesamt wird der Einfügevorgang in etwa 50% der Zeit ausgeführt. Das Eintragen in die Tabelle mit fortlaufendem Clustered Key hat: 6,833 Sekunden betragen!

Während der Ausführung wurden die Wartevorgänge überprüft und das Ergebnis unterscheidet sich deutlich vom vorherigen Prozess.

Während beim Eintragen von fortlaufenden Indexwerten PAGELATCH-Wartevorgänge das Bild dominiert haben, ist beim Eintragen von zufälligen Schlüsselwerten das Schreiben in die Protokolldatei der dominierende Wartevorgang – und das zu Recht!

Wie die Abbildung zeigt, konzentriert sich der Prozess nicht mehr an das Ende des Indexes sondern verteilt sich gleichmäßig auf alle Datenseiten im Leaf-Level. Somit können mehrere Schreibvorgänge parallel durchgeführt werden. Dieser Umstand wird in den Wartevorgängen abgebildet – fast alle Prozesse warten darauf, dass die Transaktionen in die Protokolldatei geschrieben werden.

Die Abbildung zeigt einen Mitschnitt im Microsoft WIndows Performance Monitor während der Ausführung der Prozedur für die Tabelle [dbo].[numeric_table] und für die Tabelle [dbo].[guid_table]. Während für das Einfügen von Datensätzen in die Tabelle mit aufsteigendem Indexschlüssel Pagelatches zu beobachten sind, ist das Eintragen der gleichen Datenmenge in die Tabelle mit zufälligem Indexschlüssel nur eine kurze “Episode” da kaum zu messende Pagelatches auftreten.
Vor- und Nachteile der verschiedenen Varianten
Jede der oben vorgestellten Varianten hat seine Vor- und Nachteile. Die Geschwindigkeit beim Eintragen von Daten, die man sich mit einer GUID-Variante erkauft, muss unter Umständen mit teuren Table Scans und mit erhöhtem Aufwand für Index Maintenance bezahlt werden.
Fragmentierung
Wie bereits weiter oben dargestellt, können Page Splits auch bei IDENTITY-Werten für einen Clustered Key vorkommen. Dieser Umstand führt dazu, dass trotz fortlaufendem numerischen Clustered Key die logische Fragmentierung auf den Datenseiten unverhältnismäßig hoch sein kann.
SELECT OBJECT_NAME(object_id),
index_type_desc,
fragment_count,
page_count,
record_count,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID('dbo.numeric_table', 'U'),
1,
NULL,
'DETAILED'
) AS DDIPS;
GO

Obwohl eine fortlaufende Nummerierung gewählt wurde, sind ca. 88% logische Fragmentierung zu verzeichnen. Insgesamt ist eine Datenseite zu ~65% gefüllt (Page Density). Das bedeutet für die Auslastung des Buffer Pools ca. 5.250 KB statt 8.060 Bytes.

Ein direkter Vergleich zwischen [dbo].[numeric_table] und [dbo].[guid_table] zeigt, dass es keinen nennenswerten Unterschied im Fragmentierungsgrad gibt. Beide Tabellen sind zwar hochgradig fragmentiert aber es gibt auf den ersten Blick keinen Vorteil, der für die numerische fortlaufende Variante spricht. Jedoch besitzt der fortlaufenden Clustered Keys den Vorteil, dass nach einem INDEX-REBUILD dieser Bereich des Indexes nicht mehr fragmentiert werden kann, da neue Datensätze immer an das Ende des Indexes geschrieben werden! Bei einer GUID besteht auch bei neuen Datensätzen noch das Risiko, dass der Index innerhalb von bereits bestehenden Daten erneut durch Page Splits fragmentiert wird!
Sind gleichzeitige Workloads das bestimmende Bild in Microsoft SQL Server muss sowohl bei fortlaufenden Indexschlüssel als auch bei variablen Indexschlüsseln mit Fragmentierung gerechnet werden. Grundsätzlich kann man aber behaupten, dass bei deutlich weniger Concurrency sowie nach dem Neuaufbau eines Index ein Vorteil für den fortlaufenden Indexschlüssel besteht!
Größere NONCLUSTERED Indexe
Jeder NONCLUSTERED Index muss den Clustered Key eines Clustered Index zusätzlich abspeichern, damit der Index einen Verweis zu den Daten der Datenzeile hat, die nicht im NONCLUSTERED Index hinterlegt sind. Tatsächlich ergibt sich dadurch mathematisch ein Nachteil für die Verwendung einer GUID als Clustered Index. Eine GUID hat eine Datenlänge von 16 Bytes während der Datentyp INT lediglich 4 Bytes an Speichervolumen konsumiert.

Das Ergebnis sollte nicht weiter überraschen. Es versteht sich von selbst, dass bei Verwendung eines größeren Schlüssels das Datenvolumen entsprechend wächst. Hier liegt der Vorteil eindeutig bei einem Clustered Key mit einem kleinen Datentypen (4 Bytes vs. 16 Bytes).
Ascending Key Problem
Das Problem von aufsteigenden Schlüsselattributen im Index habe ich im Artikel “Aufsteigende Indexschlüssel – Performancekiller” sehr detailliert beschrieben. Dieses Problem tritt IMMER auf, wenn ein Schlüsselattribut verwendet wird, dass beständig größere Werte in einen Index einträgt. Da die Statistiken eines Index nicht bei jedem Eintrag neu erstellt werden, kann es vorkommen, dass bei veralteten Statistiken ein schlechter Ausführungsplan generiert wird. Selbstverständlich kann auch bei einer GUID ein solches Problem auftreten, wenn die neue GUID tatsächlich am Ende des Index erstellt wird. Mit zunehmender Datenmenge wird dieses Problem jedoch immer unwahrscheinlicher! Hier liegt ein Vorteil in der Verwendung einer GUID!
Dieser Vorteil ist jedoch für einen CLUSTERED INDEX mit fortlaufender Nummerierung eher vernachlässigbar da ein Wert immer nur ein Mal als Schlüsselattribut vorkommt. Somit ist das Problem “Ascending Key” hier eher eine unbedeutende Randerscheinung!
Replikation
Manche Replikationsszenarien (z. B. MERGE) verlangen ein Attribut in jeder Tabelle, die repliziert werden soll, dass von Datentyp [uniqueidentifier] ist und die Eigenschaft ROWGUIDCOL besitzt. Plant man das Datenbanksystem in einem Replikationsumfeld, bietet sich die GUID als Clustered Key an. Will man auf IDENTITY / INT als Clustered Key nicht verzichten, muss jeder Tabelle explizit ein neues Attribut hinzugefügt werden. Das nachfolgende Codebeispiel zeigt für beide Tabellen die jeweiligen “Änderungen/Anpassungen”:
-- table with contigious numbers as clustered key
CREATE TABLE dbo.numeric_table
(
Id INT NOT NULL IDENTITY(1, 1),
c1 CHAR(400) NOT NULL DEFAULT ('just a filler'),
rowguid UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL,
CONSTRAINT pk_numeric_table PRIMARY KEY CLUSTERED (Id),
CONSTRAINT uq_numeric_table UNIQUE (ROWGUID)
);
GO
-- table with random guid as clustered key
CREATE TABLE dbo.guid_table
(
Id UNIQUEIDENTIFIER NOT NULL ROWGUIDCOL DEFAULT(NEWID()),
c1 CHAR(388) NOT NULL DEFAULT ('just a filler'),
CONSTRAINT pk_guid_table PRIMARY KEY CLUSTERED (Id)
);
GO
Das Skript zeigt beide Tabellen aus den vorherigen Beispielen, wie sie für eine MERGE oder PEER-TO-PEER Replikation vorbereitet sein müssen. Während es für die Tabelle [dbo].[guid_table] lediglich der zusätzlichen Eigenschaft “ROWGUIDCOL” für den Clustered Key bedarf, ist der Aufwand (und auch die Länge eines Datensatzes) in einer Tabelle mit einem INT deutlich höher. Zunächst muss ein weiteres Attribut vom Datentypen UNIQUEIDENTIFIER angelegt werden, dass ebenfalls die Eigenschaft “ROWGUIDCOL” besitzt. Für eine bessere Performance wird mittels eines UNIQUE CONSTRAINTS ein weiterer Index hinzugefügt, der die Eindeutigkeit sicherstellt.
Hier geht der Punkt eindeutig an die GUID als Clustered Key, da sich die Datenstruktur / Metadaten nicht verändern. Während die Länge eines Datensatzes in der Tabelle [dbo].[numeric_table] um 16 Bytes erweitert werden muss, bleibt die Datensatzlänge in der Tabelle [dbo].[guid_table] unverändert bei 411 Bytes. Ebenfalls wird kein weiterer Index für die Durchsetzung der Eindeutigkeit benötigt!
Zusammenfassung
Die generelle Ablehnung von GUID als Schlüsselattribut in einem Clustered Index wird zu häufig mit pauschalen / schon mal gehörten / Behauptungen untermauert. Sie ist ungerechtfertigt, wenn man nicht den Workload berücksichtigt, der einem DML-Prozess zu Grunde liegt.
Die Verwendung von GUID macht aus der Sicht des Autors dann Sinn, wenn sehr viele Daten von sehr vielen Prozessen eingetragen werden. Handelt es sich eher um ein System, mit dem sehr wenig Benutzer arbeiten oder aber das nur “gelegentlich” neue Datensätze in der Datenbank speichert, so sollte auch weiterhin mit dem favorisierten IDENTITY / INT gearbeitet werden.
GUID sind ideal für parallele ETL-Workloads in Stagingtabellen wenn man unbedingt einen Clustered Index verwenden möchte. Grundsätzlich sollten ETL-Workloads nur in HEAPS ihre Daten speichern. Alle anderen Varianten sind aus Sicht von Durchsatz und Zeit eher eine Bremse im sonst so performanten Ladeprozess! Aber das ist ein ganz anderes Thema, auf das ich im nächsten Artikel detaillierter eingehen werde.
Herzlichen Dank fürs Lesen!





