Sie gehen ins Internet und immer wieder stoßen Sie auf Blogartikel, Posts in Social Media und Kommentare, die Ihnen erzählen, dass Partitionierung Abfragen optimieren, weil sie nicht alle Daten lesen müssen. Fakt ist „Partitioning will NOT improve the performance of a query“. Das ist eher ein „Seiteneffekt“ von Partitionierung. Die wahre Aufgabe lautet: Management von großen Datenbeständen.
Inhaltsverzeichnis
Partitionierung – eine kurze Zusammenfassung
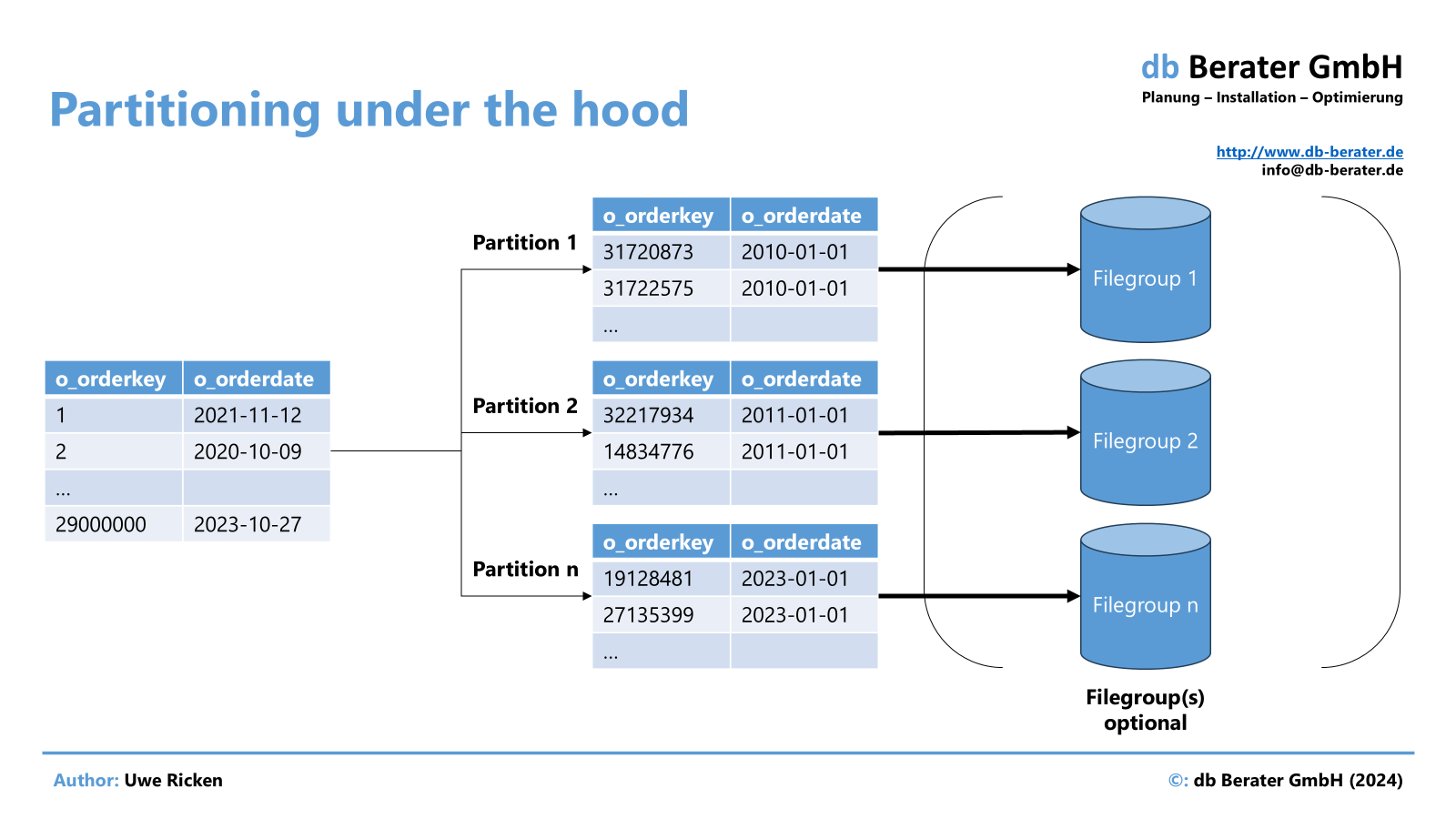
Wer mit Partitionierung noch nicht gearbeitet hat, wird sich vielleicht fragen, wie sie funktioniert. Kurz gesagt bedeutet Partitionierung das horizontale Aufteilen einer Tabelle in Segmente. Dabei werden – einfach ausgedrückt – im Hintergrund für jeden Partitionsbereich (z. B. ein Datum) separate „Allocation Units“ gebildet. Nach Außen bleibt diese Aufteilung transparent und wird durch das Tabellenobjekt und das RDBMS-System gemanagt.
Aussagen aus Blog- oder Social Media Beiträgen
Stellvertretend für den ganzen „Humbug“ soll ein Textauszug aus einer Social Media Plattform sein, den man so immer wieder antrifft.
Partitioned tables divide a large table into smaller, more manageable segments (e.g., based on date ranges or geographical regions).
This improves query performance by limiting scanned rows.
- nicht nur „große“ Tabellen kann man partitionieren. Manchmal ist es sinnvoll, auch kleine Tabellen zu partitionieren, um „Last Page Contention“ in einem Index zu vermeiden.
- Partitionierung verbessert die Performance nur, wenn zwei Bedingungen erfüllt sind:
- Die Abfrage verwendet einen Range-Filter auf dem Partitionsschlüssel
- Der Partitionsschlüssel ist nicht indexiert
Take nothing on its look. Take everything on evidence. There’s no better rule
Ich nehme das Zitat von Charles Dickens zum Anlass, meine Aussage etwas zu spezifizieren. Dazu verwende ich meine Workshop-Datenbank ERP_Demo und partitioniere die Tabelle dbo.orders auf Basis von o_orderdate (Partitionsschlüssel) und o_orderdate als eindeutiges Indexattribut.

Partition Eliminiation
Von Partition Elimination spricht man, wenn Microsoft SQL Server – basierend auf einer Abfrage des Partitionsschlüssels – nur bestimmte Partitionen auswählen muss und somit andere Partitionen nicht berücksichtigt. In dem gezeigten Beispiel wird als Partitionsschlüssel [o_orderdate] verwendet.
SELECT o_orderdate,
o_orderkey,
o_custkey,
o_orderpriority,
o_shippriority,
o_clerk,
o_orderstatus,
o_totalprice,
o_comment
FROM dbo.orders
WHERE o_orderdate = '2022-02-01';
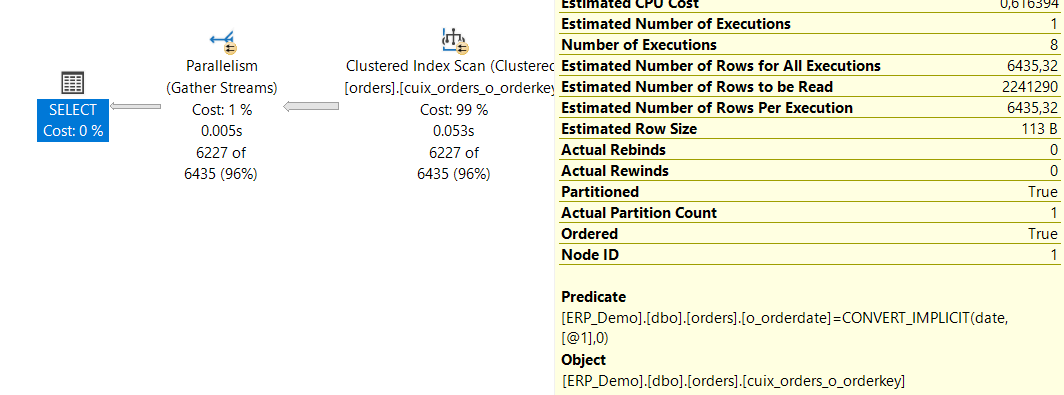
Jetzt kann man natürlich sagen, der Autor hat mit seiner Aussage Recht. Schließlich wird nur eine Partition durchsucht (Actual Partition Count = 1). Unter der Voraussetzung, dass bei jeder Abfrage der Partitionsschlüssel verwendet wird, lässt sich das zweifelsfrei nachweisen. Aber sind wir mal ehrlich – haben wir ausschließlich Abfragen, die den Partitionsschlüssel verwenden? Ich sage: NEIN!
Wenn Partition Eliminiation nicht funktioniert
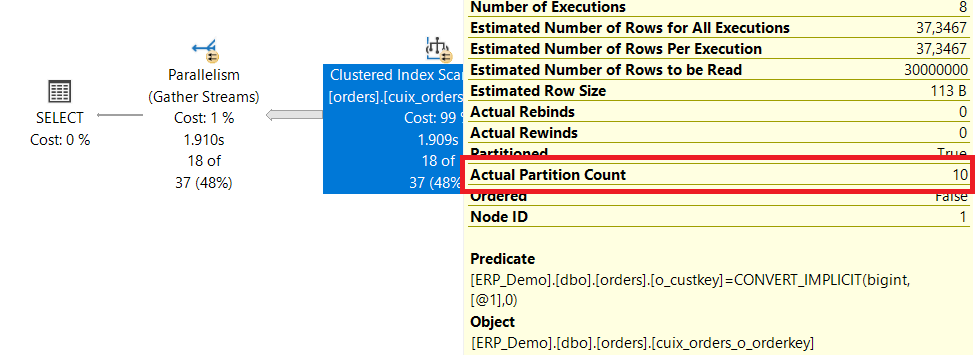
Ein weiteres Beispiel, dieses mal ohne Partitionsschlüssel. Wir suchen alle Bestellungen des Kunden 10.
SELECT o_orderdate,
o_orderkey,
o_custkey,
o_orderpriority,
o_shippriority,
o_clerk,
o_orderstatus,
o_totalprice,
o_comment
FROM dbo.orders
WHERE o_custkey = 10;
Partition Eliminiation mit „aligned“ Index
„Ist doch logisch“ wird man sagen. „Es fehlt ein Index auf [o_custkey]“. Wird ein Index in einer partitionierten Tabelle erstellt, wird er per Standard als „aligned“ – also ebenfalls auf dem Partitionsschema – erstellt.
CREATE NONCLUSTERED INDEX nix_orders_o_custkey
ON dbo.orders (o_custkey)
WITH (DATA_COMPRESSION = PAGE);
Die gleiche Abfrage – mit dem Index – ergibt nun den folgenden Ausführungsplan:
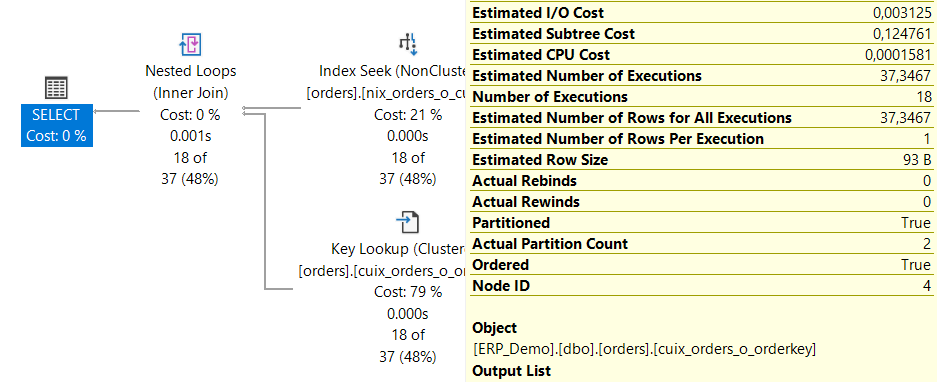
Es werden zwei Partitionen berücksichtigt. Das bedeutet, dass der Kunden in zwei Jahren Bestellungen aufgegeben hat. Scheint also „effektiv“. Wenn man aber genauer hinschaut, wird man erkennen, dass diese Abfrage – gemessen am IO – in einer partitionierten Tabelle teurer ist, als in einer nicht-partitionierten Tabelle.
„Aligned“ Index vs. „non alligned“ Index
Der nachfolgende Ausführungsplan wird erstellt, wenn EIN Kunde gesucht wird. Die Kosten sind nahezu identisch. Dennoch werden die Kosten für die Suche in einer partitionierten Tabelle höher eingeschätzt (sie sind es auch (I/O)! – es werden ca. 15% mehr Datenseiten gelesen!)

Hinweis: Gerne verwende ich in meinen Workshops den Ausdruck „Think big“. Die Beispiele umfassen nur eine begrenzte Datenmenge. Aber was wäre, wenn die Datenmenge um den Faktor 10 größer wären oder die Abfrage in kurzen Abständen immer wieder ausgeführt wird?

Kommen mehr als ein Schlüssel in die Auswahl, gehen die Kostendifferenzen weiter auseinander. Für einen optimierten Zugriff auf die Partitionen wird die Ergebnismenge aus dem partitionierten Index sortiert. Damit wird verhindert, das mehrmals auf die gleiche Partition zugegriffen werden muss.
Nimmt die Datenmenge erneut um den Faktor 10 zu, ist bei meinen Beispieldaten der „Break Even“ erreicht und die Abfrage auf die partitionierte Tabelle parallelisiert. Ja nee – is‘ klar. „Partitioning improves your queries“!
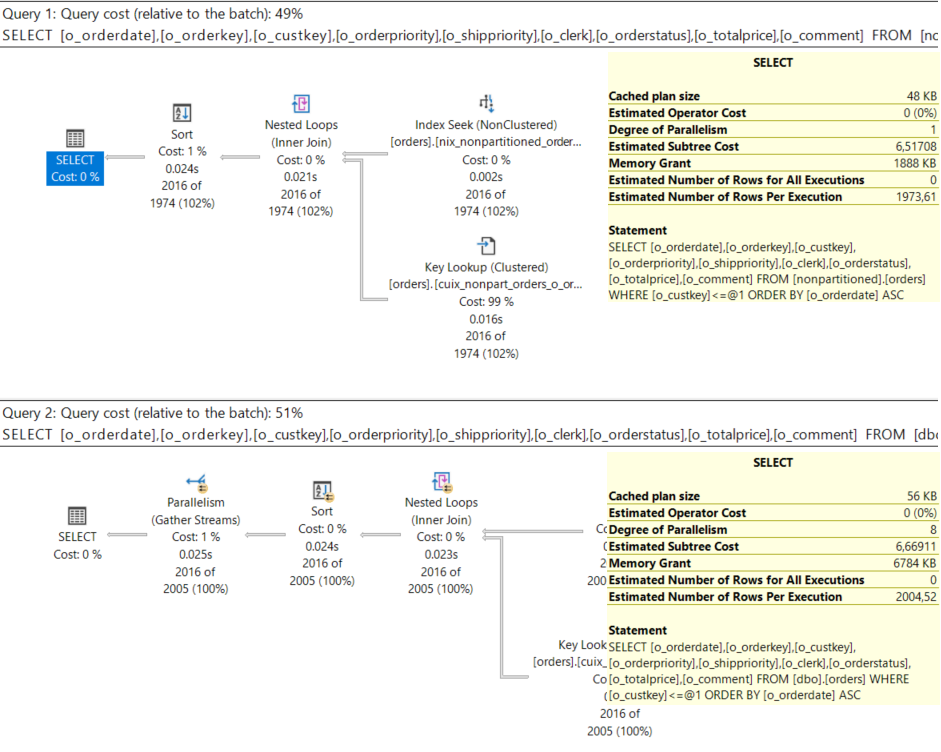
Wichtige Parameter spielen natürlich bei der Entscheidung pro/contra Parallelisierung eine Rolle. Je mehr Partitionen vorhanden sind, um so früher beginnt die Parallelisierung. So kann Microsoft SQL Server (in meinem Fall) 8 Partitionen parallel verarbeiten. Das geht aber zu Lasten der Ressourcen. Fast 7 MB RAM für die Sortierung der gleichen Datenmenge. Wahrlich eine Performance-Tuning-Orgie :).
Aggregationen – Grenzen von Partitionierung
Der Super GAU kommt, wenn man versucht, in einer partitionierten Tabelle ein Aggregatsfunktion zu verwenden. Als Beispiel soll die folgende Anforderung gelten. Wann hat der Kunde 10 seine letzte Bestellung gehabt.
SELECT o_custkey,
MAX(o_orderdate) AS last_order
FROM dbo.orders
WHERE o_custkey = 10
GROUP BY
o_custkey
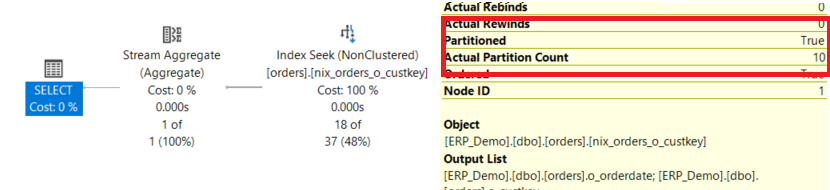
Der Index MUSS in allen Partitionen suchen, da [o_custkey] das führende Attribut ist. Dieser Schlüssel kann in jedem Jahr vorkommen; demzufolge muss jede Partition (egal, ob Daten vorhanden sind oder nicht) durchsucht werden. Das gibt es bei einer nicht partitionierten Tabelle natürlich nicht.
10 Partitionen * 3 I/O (INDEX SEEK) = 30 I/O
Table ‚dbo.orders‘. Scan count 10, logical reads 30,…
Table ’nonpartitioned.orders‘. Scan count 1, logical reads 3…
Nimmt die Datenmenge zu, laufen die Kosten erneut aus dem Ruder!
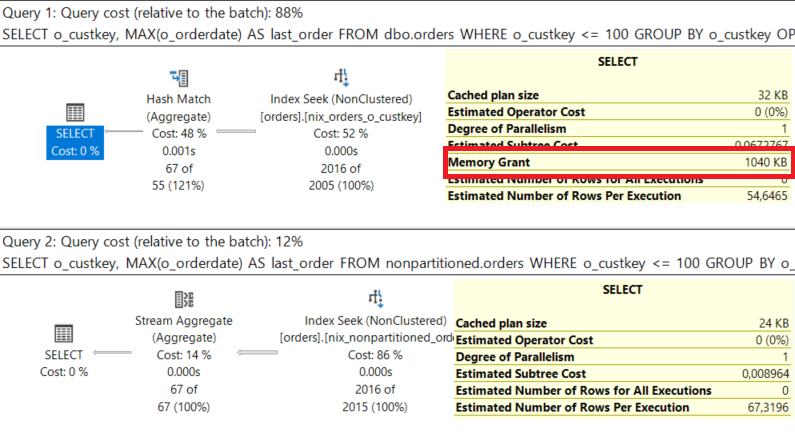
Ein HASH MATCH Operator wird bei Aggregationen verwendet, wenn die Daten aus dem Vorgänger-Operator nicht sortiert geliefert werden. Das trifft bei der Partitionierung zu. Da die Daten aus der partitionierten Tabelle kommen, werden sie nach [o_orderdate] (pro Partition) sortiert und erst danach nach [o_custkey]. Folglich müssen die Daten nachträglich nach [o_custkey] sortiert werden. Dazu verwendet Microsoft SQL Server einen HASH MATCH Operator. Nachteil: Wir brauchen Memory!
In der nicht partitionierten Tabelle ist der Index auf [o_custkey] und [o_orderdate] ebenfalls vorhanden. Somit kommen die Daten bereits sortiert in den STREAM AGGREGATE Operator. Ein STREAM AGGREGATE Operator verlangt, dass die Daten bereits sortiert ankommen!
Lächle und sei froh, es könnte schlimmer kommen!
Und ich lächelte und war froh – und es kam schlimmer.
Ich habe einen Kunden, der in einer partitionierten Tabelle den größten Wert ermitteln muss. Diese Tabelle hat ca. 50 Mrd. Datensätze. Obwohl ein Index auf dem Attribut für die Aggregation liegt, dauerte die Abfrage ca. 45 Sekunden. Schuld war – logisch – die Partitionierung.
Für die Demonstration reicht ein simples Beispiel: Es soll die höchsten Auftragssumme gezeigt werden.
/* Highest order amount - no index */
SELECT MAX(o_totalprice)
FROM dbo.orders;

Da kein Index auf dem Attribut ist, wird ein – aligned – Index erstellt.
CREATE NONCLUSTERED INDEX nix_orders_o_totalprice
ON dbo.orders (o_totalprice)
WITH (DATA_COMPRESSION = PAGE);
GO
Kürzen wir es ab – es funktioniert nicht. Die Abfrage wird erneut einen FULL SCAN durchführen. Nur diesmal geht die Suche durch ALLE Partitionen. Der Index liegt ebenfalls auf dem Partitionsschema!
Versuchen wir es mit Hilfe des Partitionsschlüssels, schließlich wird ja behauptet, dass durch Partition Elimination alles besser wird.
SELECT MAX(o_totalprice)
FROM dbo.orders
WHERE o_orderdate >= '2023-01-01'
AND o_orderdate < '2024-01-01';
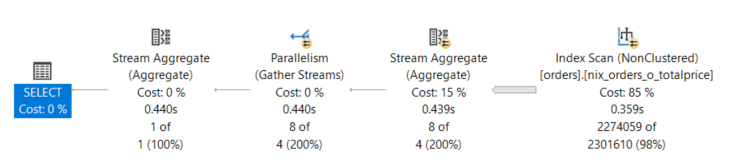
WTH – Partitionierung soll Abfragen doch schneller machen, warum geht das nicht? Was passiert mit dieser Abfrage? Tatsächlich haben wir den Vorteil der „Partition Elimination“ jedoch bezahlen wir das mit einem SCAN der vollständigen Partition. Das scheint auf dem ersten Blick keinen Sinn zu ergeben. Leider doch, eben WEIL Partitionierung verwendet wird. Das Geheimnis liegt im Aufbau des Indexes. Vorrangig wird der Partitionsschlüssel verwendet und nachrangig mein Attribut, das ich aggregieren möchte.
Da die Abfrage einen Datumsbereich anwendet, muss erst der Datumsbereich gefiltert werden und erst danach kann der maximale Wert gefunden werden. Wenn das „Improvement“ ist, dann … – aber das Internet hat immer Recht und AI macht alles besser.
Aggregationen – ein Workaround
Das Problem des obigen Beispiels ist der Range-Scan. Dadurch kann keine Ordnung nach o_totalprice (ist ja unser Indexschlüssel) gebildet werden. Im ersten Schritt muss also der Range Scan eliminiert werden. Das kann man mit einem Trick bewerkstelligen. Statt eines Range Scans verwendet man die ID der Partition!
/* Use $PARTITION to recieve the partition id for the given key value */
SELECT $PARTITION.pf_orders('2023-01-01');
Das obige Beispiel gibt den Wert „9“ aus, der besagt, dass sich Daten für den 01.01.2023 in der 9. Partition befinden. Schreiben wir die Abfrage um, erhalten wir das gewünschte Ergebnis mit entsprechender Performance.
/* Search for the max total price in partition 9 */
SELECT MAX(o_totalprice)
FROM dbo.orders
WHERE $PARTITION.pf_orders(o_orderdate) = 9;

Der TOP-Operator verhindert, dass die vollständige Partition durchsucht wird. Der INDEX SCAN ist „orders“ und beginnt von hinten. Somit wird der erste Datensatz gefunden und an den TOP-Operator geleitet. Der wiederum beendet sofort den SCAN.
Aggregationen – Finale
Nehmen wir die Erkenntnisse aus dem vorherigen Abschnitt, können wir das Maximum ermitteln, indem für JEDE Partition die [partition_id] verwendet wird.
SELECT MAX(total.o_total_price) AS max_price
FROM sys.partitions AS p
CROSS APPLY
(
SELECT MAX(o_totalprice) AS o_total_price
FROM dbo.orders AS o
WHERE $PARTITION.pf_orders(o_orderdate) = p.partition_number
) AS total
WHERE p.OBJECT_ID = OBJECT_ID(N'dbo.orders', N'U')
AND index_id <= 1;
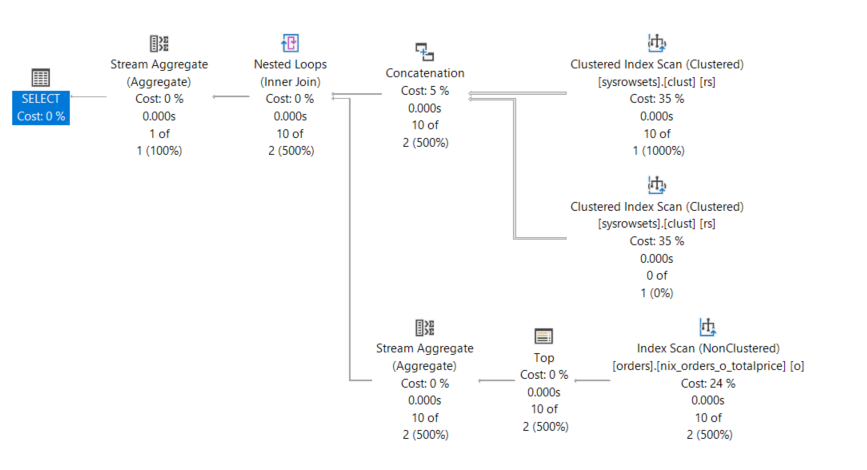
Als Fazit bleibt festzuhalten, dass Partitioning in einem sehr eingeschränkten Verwendungsspektrum Performance-Vorteile bietet; die Nachteile – in Bezug auf „Improvement“ dominieren diese Technik. Es ist eine Binsenweisheit, die sich konsequent im Internet hält und hinterfragt werden sollte. Insbesondere dann, wenn diese Antworten von den Intelligenzbestien – ich weiß nicht warum – als mögliche „Interviewfragen“ verkauft werden.
Vielen Dank fürs Lesen!






Sehr schön und informativ!