
von Uwe Ricken | Dez. 12, 2024 | Administration, Allgemein, SQL Blog
You often read on social networks that a DBA’s job is to optimize databases, among other things. I think that’s a misinterpretation of the – important – role of a DBA. Why? I’m happy to share my opinion on the role a DBA has to play in a...
von Uwe Ricken | Dez. 9, 2024 | 200, DB Engine, SQL Blog
JOIN Elimination in Microsoft SQL Server is an optimization technique with foreign key constraints where the query engine removes redundant JOIN operations during query execution. This occurs when the data from the joined table is not used in the SELECT clause or any...
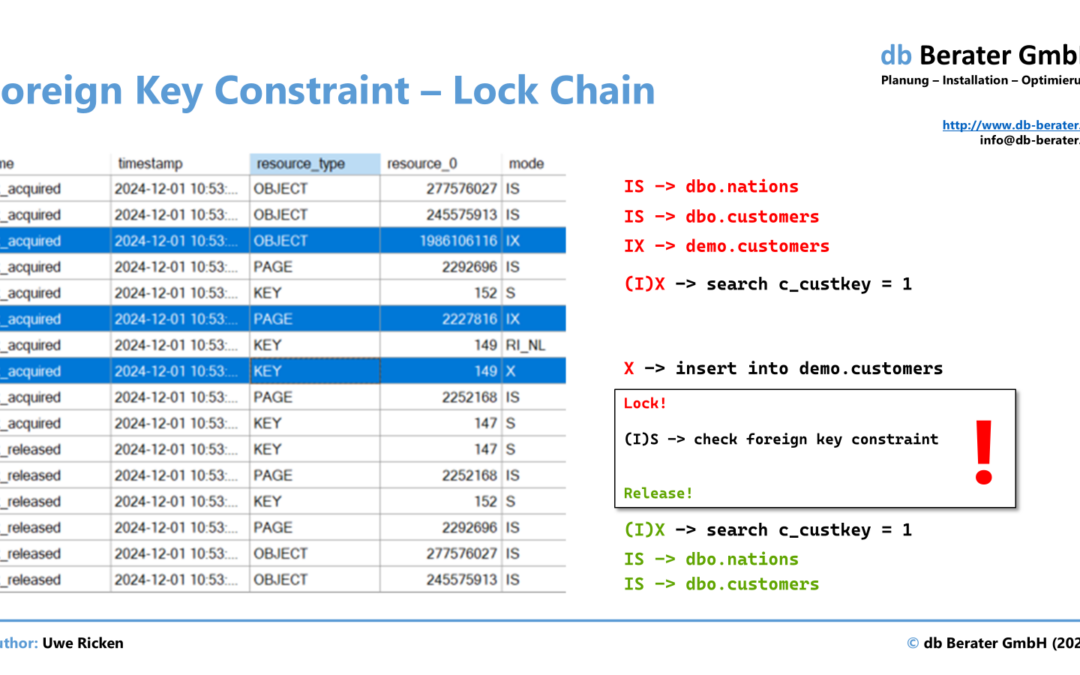
von Uwe Ricken | Dez. 1, 2024 | DB Engine, Optimierung, SQL Blog
My first article on using foreign key constraints in databases included the claim that using them slows down an application. This article addresses the claim that a Foreign Key Constraint use locks and can cause Deadlocks and thus slow down applications. Claim Foreign...
von Uwe Ricken | Nov. 25, 2024 | DB Engine, SQL Blog
When revising one of my popular sessions on scenarios in which indexes no longer help, one of the topics covered was foreign key constraints for data integrity and JOIN eliminiation. During my research, I came across various arguments from developers who reject...
von Uwe Ricken | Nov. 24, 2024 | SQL Blog
Although an index should provide a fast query, Microsoft SQL Server either does not want to use that index at all or does not want to use it optimally. The cause is not SQL Server or the index but think about the correct data types for your predicates in your queries!...
von Uwe Ricken | Nov. 22, 2024 | SQL Blog
Database developers like to use the ISNULL() function to check two conditions and compare them with a search value. This is often done with the intention of finding records that do not have a value stored in the attribute. Sometimes they can get lucky – but not...





