Im vorherigen Artikel habe ich mich intensiv mit INSERT-Operationen und den Besonderheiten bei Heaps beschäftigt. Da aber in Datenbanken nicht nur neue Daten geschrieben werden, müssen auch Besonderheiten bei Aktualisierungen berücksichtigt werden. Dieser Artikel beschreibt detailliert Aktualisierungen von Datensätzen und deren mögliche Problematik für Heaps.
Inhaltsverzeichnis
Aktualisierung von Daten
Die Aktualisierung von Daten gehört zu den alltäglichen Prozessen in einer Datenbank. Für Heaps gibt es Besonderheiten, die berücksichtigt werden müssen.
Für alle Demonstrationen in diesem Artikel verwende ich meine Kundendatenbank [CustomerOrders], die ich in meinen Workshops verwende. In einer Demo-Datenbank verwende ich ~3 Millionen Aufträge in einem Heap.
SELECT c.Id AS Customer_Id,
c.Name AS CustomerName,
CO.Id AS Order_Id,
CO.OrderNumber,
CO.InvoiceNumber,
CO.OrderDate,
CO.OrderStatus_Id,
CO.Employee_Id,
CO.InsertUser,
CO.InsertDate
INTO demo_db.dbo.CustomerOrders
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerOrders AS CO
ON (C.Id = CO.Customer_Id)
GO
Probleme bei Aktualsierungen
Die Aktualisierung eines Datensatzes / mehrerer Datensätze in einem Heap unterliegt bestimmten Regularien, die – insbesondere – in einem konkurrierenden System beachtet werden müssen. Microsoft SQL Server verhält sich beim Sperrverhalten vollständig unterschiedlich, wenn eine Aktualisierung parallel oder single threaded ausgeführt wird!
Abhängig von der gesamten Datenmenge in einem Heap entstehen unterschiedliche Kosten für Aktualisierungen bedingt durch die Anzahl der Datenseiten, die Microsoft SQL Server für eine Aktualisierung durchsuchen muss. Um festzustellen, wie viele Datenseiten die Beispieltabelle verwendet, wird die folgende Abfrage ausgeführt:
-- How many data pages do we have for the table
SELECT index_id,
used_page_count,
reserved_page_count,
row_count
FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID(N'dbo.CustomerOrders', N'U');
GO

Bei der Aktualisierung eines Datensatzes oder mehrerer Datensätze muss Microsoft SQL Server IMMER 79.541 Datenseiten durchsuchen, da ja ein Heap bekanntlich keinen Index besitzt!
Für die folgende Aktualisierungsabfrage ergibt sich – ohne Abfragehinweise – ein Ausführungsplan, der parallel ausgeführt wird!
UPDATE dbo.CustomerOrders
SET OrderDate = CAST(GETDATE() AS DATE)
WHERE Order_Id = 10000;
GO

Werden Heaps durch parallele Ausführungen aktualisiert, kann ein System – bei gleichzeitigen SELECT-Statements auf die Tabelle – nicht mehr skalieren!
LCK_U Sperren
Bei der Aktualisierung von Datensätzen in einem Heap ergeben sich Probleme durch die gesetzten Sperren auf die unterschiedlichen Objekte.
Hinweis
Locking und Blocking kann auf Grund der Komplexität in diesem Artikel nicht beschrieben werden. Eine sehr detaillierte Übersicht und Funktionsweise findet sich in der Dokumentation zu Microsoft SQL Server!
https://docs.microsoft.com/de-de/sql/relational-databases/sql-server-transaction-locking-and-row-versioning-guide
Wenn eine Aktualisierung von Datensätzen in einem Heap durchgeführt werden soll, muss Microsoft SQL Server zwei Phasen durchlaufen:
- Suchen aller Datensätze, die dem Suchkriterium entsprechen
- Datensätze exklusiv sperren und aktualisieren
Besonderes Augenmerk gilt der Tatsache, dass Microsoft SQL Server erst die Datensätze für eine Aktualisierung markiert (LCK_M_U). Wenn alle Datensätze gefunden wurden, wird die LCK_M_U-Sperre in eine exklusive Sperre (LCK_M_X) konvertiert und der Datensatz kann aktualisiert werden.
Ein Beispiel aus dem realen Leben
Stellen Sie sich vor, Sie möchten gerne eine Tafel Schokolade in einem Süßigkeiten-Shop kaufen. Wenn Sie nicht genau wissen, welche Marke und welcher Geschmack es sein soll (Heap), durchsuchen Sie den Laden und markieren alle Schokolade-Tafeln, die Sie gerne hätten. Wenn Sie den gesamten Laden durchsucht haben, kehren Sie zu den markierten Schokoladen-Tafeln zurück und packen sie in Ihren Einkaufswagen.
Wissen Sie bereits im Vorfeld, dass Sie eine Nussschokolade von Hersteller X möchten (Index), gehen Sie gezielt zu der Position, an der die Schokolade deponiert ist und packen sie in Ihren Einkaufswagen.
SQL Server verwendet dieses Vorgehen, da eine U-Sperre kompatibel mit einer S-Sperre ist; somit können die Datensätze, die mit einer U-Sperre versehen sind, so lange gelesen werden, bis sie zu einer exklusiven Sperre konvertiert werden!
Um die Unterschiede zwischen der Aktualisierung mit paralleler Ausführung und serieller Ausführung hervorzuheben, wird ein Extended Event erstellt, das die Sperren aufzeichnet.
-- Extended Event for audit of lockings
CREATE EVENT SESSION [Track Lockings]
ON SERVER
ADD EVENT sqlserver.sql_statement_starting
(WHERE sqlserver.session_id = 61),
ADD EVENT sqlserver.sql_statement_completed
(WHERE sqlserver.session_id = 61),
ADD EVENT sqlserver.lock_acquired
(
WHERE sqlserver.session_id = 61
AND mode <= 10
),
ADD EVENT sqlserver.lock_released
(
WHERE sqlserver.session_id = 61
AND mode <= 10
),
ADD EVENT sqlserver.lock_escalation
(WHERE sqlserver.session_id = 61)
ADD TARGET package0.histogram
(
SET filtering_event_name = N'sqlserver.lock_acquired',
source=N'mode',
source_type=0
),
ADD TARGET package0.event_file
(SET filename=N'F:\TraceFiles\Track Lockings'),
ADD TARGET package0.pair_matching
(
SET begin_event=N'sqlserver.lock_acquired',
begin_matching_columns=N'transaction_id',
end_event=N'sqlserver.lock_released',
end_matching_columns=N'transaction_id'
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
)
GO
ALTER EVENT SESSION [Track Lockings] ON SERVER STATE = START;
GO
Mit dem obigen Extended Event wird (für eine vorher festgelegte Session!) aufgezeichnet, wann eine Sperre angefordert und wieder freigegeben wird. Ebenfalls zeichnet das Extended Event auf, wenn eine Lock Escalation angefordert wird.
Als Ziele für die Aufzeichnung werden sowohl die Speicherung in einer Datei als auch in einem Histogramm verwendet, damit die Ergebnisse sowohl kumuliert (Histogramm) als auch einzeln (Datei) ausgewertet werden können.
Parallele Ausführung
Werden keine Hinweise in der Abfrage zur Parallelisierung angegeben, wird die Abfrage parallelisieren, sobald die Gesamtkosten der Ausführung den „Cost Threshold for Parallelism“ überschreiten, der auf meinem Testsystem den Wert von „5“ besitzt
UPDATE dbo.CustomerOrders
SET OrderDate = CAST(GETDATE() AS DATE)
WHERE Order_Id = 10000;
Die obige Abfrage aktualisiert alle Bestellungen mit der [Order_Id] = 10000 mit dem aktuellen Tagesdatum. Die Ausführung wird – auf Grund der hohen Kosten – parallel durchgeführt. Aus den Aufzeichnungen der Extended Event Sitzung ergeben sich folgende – interessante – Informationen:
Die Anzahl der unterschiedlichen Sperrtypen können aus dem Histogramm des Extended Events evaluiert werden.
| Sperre | XE-Value | Anzahl |
|---|---|---|
| LCK_M_U | 4 | 24.997 |
| LCK_M_IX | 8 | 7 |
| LCK_M_SCH_S | 1 | 6 |
| LCK_M_X | 5 | 5 |
| LCK_M_SCH_M | 2 | 3 |
| LCK_M_S | 3 | 1 |
| LCK_M_IU | 7 | 1 |
Die (U)pdate-Sperren dominieren in der Aufzeichnung. Um jedoch die Problematik dieses Verhaltens zu erkennen, muss die Aufzeichnung in der Datei der Extended Event Session analysiert werden. Die Abbildungen sind Extrakte aus der Aufzeichnung, die die Besonderheiten hervorheben.
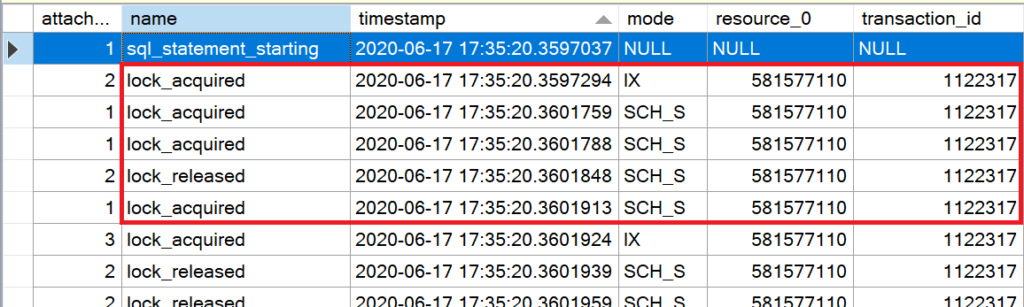
In Zeile 1 beginnt die Aufzeichnung der UPDATE-Aktion. Unmittelbar zu Beginn der Ausführung (Zeile 2) versieht Microsoft SQL Server die Tabelle (resource_0) mit einer IX-Sperre (mode). IX bedeutet „Intent eXclusive“; Microsoft SQL Server signalisiert mit dieser Sperre auf der Tabelle, dass Daten in der Tabelle exklusiv für Schreibprozesse gesperrt werden sollen.
Da es sich um einen Heap handelt, muss Microsoft SQL Server die vollständige Tabelle durchsuchen; wie bereits im Artikel „Heaps – Lesen von Daten“ beschrieben, sorgt diese Sperre dafür, dass keine Metadatenänderungen an der Tabelle vorgenommen werden müssen.
Hinweis
Diese Sperren werden in der Aufzeichnung häufiger auftreten. Das liegt daran, dass der Prozess parallelisiert und somit jeder Thread im Prozess das gleiche Verhalten zeigt!
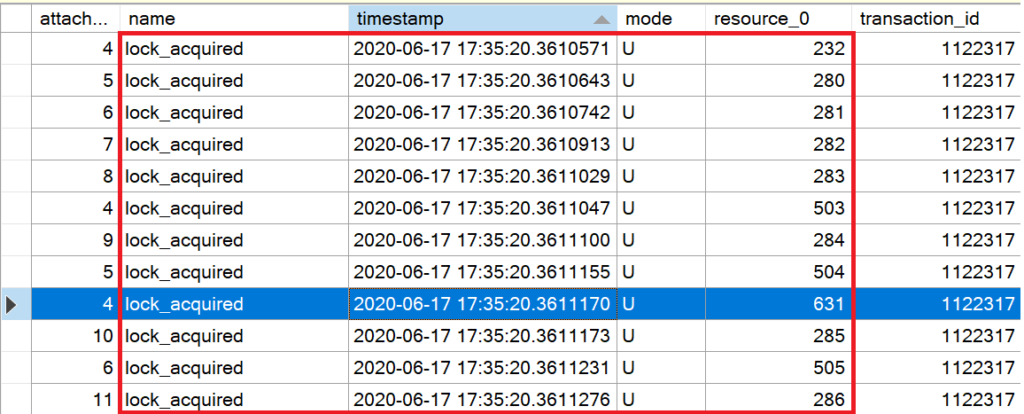
Nachdem die Tabelle gegen Änderungen an den Metadaten geschützt ist und dem System mitgeteilt wurde, dass in der Tabelle Änderungen vorgenommen werden (IX), beginnt Microsoft SQL Server, die Datenseiten des Heaps zu durchsuchen. Dabei wird jede Datenseite mit eine (U)-Sperre versehen. Man beachte, dass die Sperren nicht wieder aufgehoben werden!
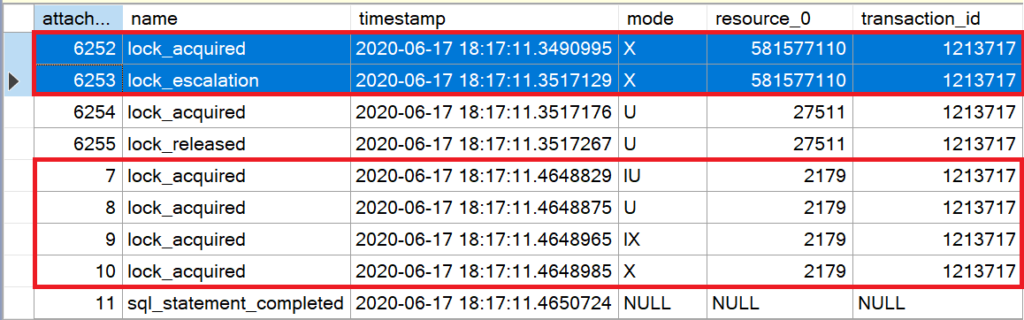
Sind zu viele Einzelsperren in einer Transaktion geöffnet, eskaliert Microsoft SQL Server die Sperren zu einer vollständigen Tabellensperre. Zum Schluss wird die betroffene Seite (2179) exklusiv gesperrt, um die Aktualisierungen an dem Datensatz vorzunehmen.
SELECT resource_type,
resource_subtype,
resource_description,
resource_associated_entity_id,
request_mode,
request_type,
request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID
ORDER BY
resource_type;
GO

Dieses Verhalten ist in einem konkurrierenden Prozessumfeld störend und ist unter anderem ein wichtiger Grund, der gegen die Verwendung von Heaps in hoch transaktionalen Umgebungen angeführt wird. Würde während der Aktualisierung des Datensatzes (Order_Id = 10.000) ein weiterer Prozess z. B. auf einen Datensatz zugreifen, der nicht auf der gleichen Datenseite gespeichert ist, wie der zu ändernde Datensatz, muss dieser Prozess darauf warten, dass die exklusive Sperre auf der Tabelle wieder aufgehoben wird.

Serielle Ausführung
Bei der seriellen Ausführung einer Aktualisierung in einem Heap verändert sich das Sperrverhalten zu Gunsten eines verbesserten (nicht optimalen!) Konkurrenzverhaltens.
UPDATE dbo.CustomerOrders
SET OrderDate = GETDATE()
WHERE Order_Id = 10000
OPTION (MAXDOP 1);
GO
Eine serielle Ausführung kann durch den Abfragehinweis MAXDOP erzwungen werden. Nach der Ausführung der seriellen Abfrage sollte man sofort die Unterschiede im Histogramm sowie in der Aufzeichnungsdatei des Extended Events erkennen können!
| Sperre | XE-Value | Anzahl |
|---|---|---|
| LCK_M_U | 4 | 79.540 |
| LCK_M_SCH_S | 1 | 21 |
| LCK_M_S | 3 | 4 |
| LCK_M_X | 5 | 1 |
| LCK_M_IS | 6 | 1 |
| LCK_M_IX | 8 | 1 |
Die Anzahl der angeforderten (U)pdate-Sperren hat sich massiv erhöht. Ein direkter Zusammenhang zwischen Sperranforderungen und Anzahl der von der Tabelle belegten Datenseiten lässt sich nicht verleugnen.
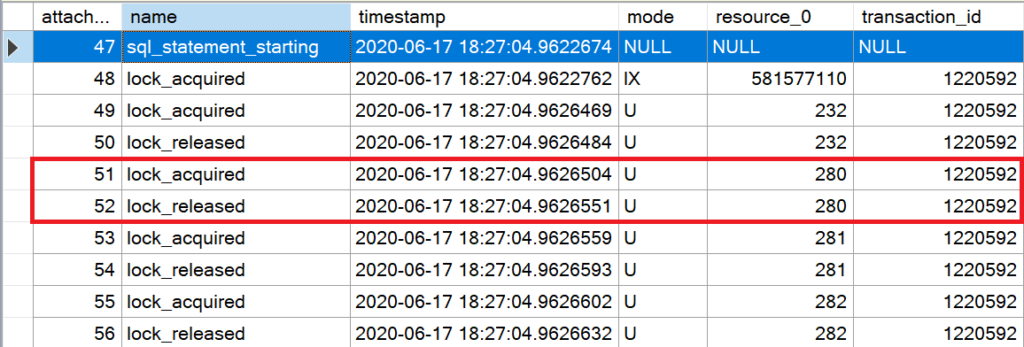
Die Analyse der durch die Extended Event Session gespeicherten Aktionen zeigt einen – entscheidenden – Unterschied. Während bei der parallelisierten Ausführung die gesetzten Sperren auf den Datenseiten aufrecht erhalten werden, werden sie bei einer seriellen Ausführung sofort wieder freigegeben; ein typisches Verhalten, das so auch bei SELECT-Anweisungen in Heaps zu erkennen ist.
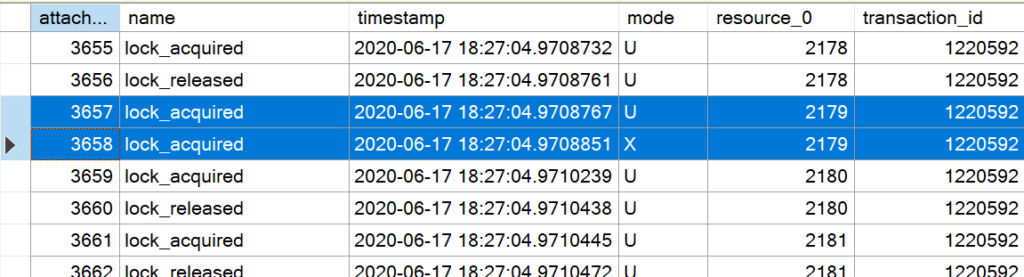
Anders als bei der parallelen Ausführung wird der Datensatz bereits während des SCAN-Vorgangs aktualisiert; die e(X)klusive Sperre wird erst aufgehoben, wenn der SCAN-Vorgang vollständig abgeschlossen wird.
Da nur die Datenseiten gesperrt bleiben, auf denen eine Aktualisierung durchgeführt wird, kann – besonders bei kleinen Datenmengen – eine Lock Escalation vollständig verhindert werden!
Konkurrierender Zugriff
Die Vorteile bei konkurrierenden Systemen kann nur die serielle Ausführung bieten. Weiß man, dass die Sperre auf einer Datenseite bis zum Ende der Transaktion / des SCAN-Vorgangs aufrecht erhalten bleibt, sollten Zugriffe auf Datensätze, die NICHT auf der zu aktualisierenden Datenseite gespeichert sind, möglich sein!
SELECT * FROM dbo.CustomerOrders WHERE Order_Id = 1
Wird diese Abfrage in einem konkurrierenden Prozess ausgeführt, bleibt das erhoffte Ergebnis leider aus. Der Grund dafür liegt in der Natur des Heaps und seinen Eigenschaften bei der Suche nach Datensätzen.
Ein SELECT – egal, ob mit oder ohne Prädikat – muss IMMER die vollständige Tabelle durchsuchen (SCAN). Somit kann der Datensatz mit der ORDER_ID = 1 bereits längst gefunden worden sein; jedoch muss die Anweisung die vollständige Tabelle durchsuchen.

Ein Blick in die Transaktionssperren zeigt das Verhalten; während ein X-Lock auf der Datenseite 2.179 gehalten wird, muss der Prozess, der das SELECT-Statement ausführt, warten, um eine S-Sperre setzen zu können.
SELECT TOP (1) * FROM dbo.CustomerOrders WHERE Order_Id = 1
Weiß man, dass es nur einen Datensatz mit dem Prädikat geben kann oder der Workload prüft nur die Existenz eines Datensatzes, kann die TOP-Klausel helfen, das Problem zu umgehen.
Hinweis
Eigentlich ist diese Technik gemein. Sie funktioniert nur dann, wenn sich der Datensatz auf einer Datenseite befindet, die sich VOR der gesperrten Datenseite befindet :)
Die Suche nach Order_Id = 100.000 wird – leider – auch warten müssen, wenn sich der Datensatz auf einer Datenseite befindet, die sich hinter der gesperrten Datenseite 2.179 befindet!
In diesem Fall hilft nur die Verwendung eines NonClustered Index für das Prädikat.
<Ironie An>
Dafür gibt es den Hinweis (NOLOCK) oder den Isolation Level READUNCOMMITTED
<Ironie Aus>
Forwarded Records
Ein Forwarded Record ist ein Datensatz in einem Heap, der – bedingt durch eine Aktualisierung – im Volumen so stark anwächst, dass er nicht mehr vollständig auf die ursprüngliche Datenseite passt. Microsoft SQL Server erstellt eine neue Datenseite und speichert den Datensatz auf der neu erstellten Datenseite. Auf der ursprünglichen Datenseite verbleibt ein Eintrag, der auf die neue Adresse/Datenseite verweist. Obwohl Microsoft SQL Server den Datensatz auf einer neuen Datenseite speichert, bleibt die Originaladresse immer noch gültig damit ein Update der Position in eventuell vorhandenen Non Clustered Indexes nicht ausgeführt werden muss.
Um zu veranschaulichen, wie sich Forwarded Records auf die Performance auswirken können, wird zunächst eine Testtabelle angelegt, in der 20 Datensätze gespeichert werden.
/* Create the demo table for 20 records */
CREATE TABLE dbo.demo_table
(
Id INT NOT NULL IDENTITY (1, 1),
C1 VARCHAR(4000) NOT NULL
);
GO
/* Now insert 20 records into the table */
INSERT INTO dbo.demo_table (C1) VALUES
(REPLICATE('A', 2000)),
(REPLICATE('B', 2000)),
(REPLICATE('C', 2000)),
(REPLICATE('D', 2000));
GO 5
/* On what pages are the records stored? */
SELECT FPLC.*,
DT.*
FROM dbo.demo_table AS DT
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%) AS FPLC;
GO

Eine SELECT Anweisung generiert 5 I/O, wenn die Tabelle ausgegeben werden soll.
SET STATISTICS IO ON;
GO
SELECT * FROM dbo.demo_table;
GO
SET STATISTICS IO OFF;
GO

Wird ein Datensatz so bearbeitet, dass er – bedingt durch seine Größe – nicht mehr auf die ursprüngliche Datenseite passt, muss Microsoft SQL Server eine neue Datenseite allokieren, um den Datensatz auf diese neue Datenseite zu verschieben.
BEGIN TRANSACTION UpdateRecord;
GO
UPDATE dbo.demo_table
SET C1 = REPLICATE('Z', 2500)
WHERE Id = 1;
-- Check the transaction log activity
SELECT FD.[Current LSN],
FD.Operation,
FD.Context,
FD.AllocUnitName,
FD.[Page ID],
FD.[Slot ID]
FROM sys.fn_dblog(NULL, NULL) AS FD
ORDER BY
FD.[Current LSN];
GO
COMMIT TRANSACTION UpdateRecord;
GO
Ein Blick in das Transaktionsprotokoll zeigt den detaillierten Prozess!

Zunächst wird eine neue Datenseite angelegt, damit anschließend der aktualisierte Datensatz auf dieser Datenseite gespeichert werden kann.
- Der „alte“ Datensatz wird auf die neue Datenseite kopiert
- Die PFS-Seite muss aktualisiert werden, da sich die Datenmenge auf der neuen Datenseite geändert hat.
- Der „alte“ Datensatz auf der neuen Datenseite wird aktualisiert
- Der „alte“ Datensatz auf der ursprünglichen Datenseite wird aktualisiert
- Durch die Änderung der Datengröße des ursprünglichen Datensatzes wird eine Aktualisierung der PFS-Seite erzwungen.
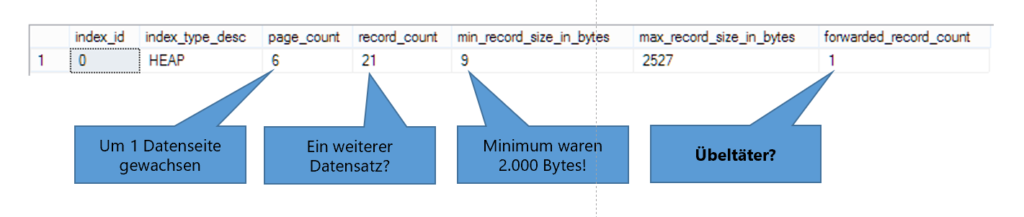
Insgesamt allokiert die Tabelle nun 6 Datenseiten!
-- How many data pages do we have for the table
SELECT index_id,
index_type_desc,
page_count,
record_count,
min_record_size_in_bytes,
max_record_size_in_bytes,
forwarded_record_count
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.demo_table', N'U'),
0,
NULL,
N'DETAILED'
);
GO
Wird nun erneut ein SELECT auf die Tabelle ausgeführt, um die Daten an den Client zu senden, überrascht das Ergebnis jedoch!
SET STATISTICS IO ON;
GO
SELECT * FROM dbo.demo_table;
GO
SET STATISTICS IO OFF;
GO

Obwohl nur 6 Datenseiten belegt sind, muss Microsoft SQL Server 7 Datenseiten durchsuchen! Seltsam, oder?
Stellen Sie sich vor, Sie machen es wie der nette Herr in dem Video, weil Ihr Arzt Ihnen sagt, dass Sie das Bier streichen sollen. Genau das gleiche Verhalten legt Microsoft SQL Server an den Tag, wenn es darum geht, einen Heap zu scannen.
Ein Forwarded Record ist wie ein Nachsendeantrag, der verwendet wird, um sich die Post an eine neue Adresse senden zu lassen.

Die Aufzeichnungen in der Extended Event Session geben detaillierten Aufschluss darüber, welches Problem bei Forwarded Records auftritt!
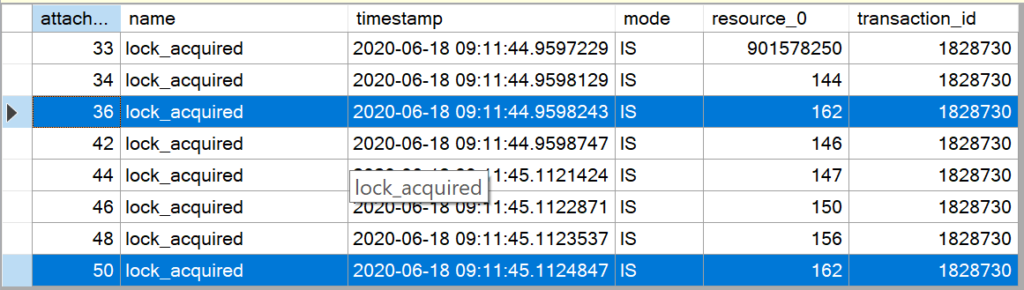
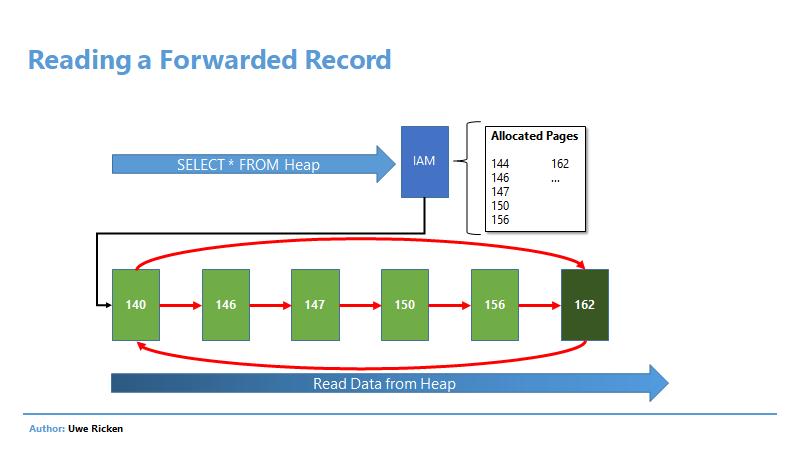
Nachdem die IAM-Seite gelesen wurde, kennt Microsoft SQL Server die Datenseiten, die gelesen werden müssen. Beim Lesen der Datenseite 142 stellt Microsoft SQL Server fest, dass es einen Verweis zur Seite 162 gibt und liest den Datensatz von Seite 162. Anschließend wird mit dem Lesen der Datenseiten weiter gemacht, wie in der IAM beschrieben ist.
Obwohl Microsoft SQL Server den Inhalt des Datensatzes auf Seite 162 bereits gelesen hat, muss die Seite erneut gelesen werden, da ja noch weitere Datensätze vorhanden sein könnten.
Ein Beispiel aus dem wahren Leben
Sie sind ein Postbote, der sich so verhält, wie der freundliche Herr, der sein Bier streicht. Sie lesen Ihre Auslieferungsroute (IAM) und beginnen nun mit der Auslieferung der Briefe.
Bereits bei der ersten Adresse (142) stellen Sie fest, dass der Empfänger verzogen ist (Auf dem Briefkasten steht die neue Adresse (162)). Also gehen Sie direkt zur Adresse 162, um den Brief dort abzuliefern. Anschließend gehen Sie wieder zur ersten Adresse zurück, um die Briefe gemäß Ihrer Route (IAM) weiter auszuliefern.
Dumm nur, dass Sie zum Schluss erneut bei der Adresse 162 landen, um dort – eventuell – auch noch Briefe auszuliefern!
Die häufigste Frage, die ich häufig auf Konferenzen zu diesem Thema erhalte, richtet sich nach dem Grund für die Implementierung von Aktualisierungen in Verbindung mit Forwarded Records.
Der Grund für die Implementierung von Forwarded Records liegt in der Struktur von Nonclustered Indexen. Ein Nonclustered Index in einem Heap speichert kein Schlüsselattribut sondern die Position des Datensatzes. Diesse Strukturen habe ich ausführlich im Artikel „Heaps – Nonclustered Indizes“ beschrieben.
Damit Microsoft SQL Server nach der Aktualisierung eines Datensatzes die Nonclustered Indizes nicht aktualisieren muss, wenn ein Datensatz verschoben wird, wird mit Forwarded Records gearbeitet!
Best Practice
Lässt man sich auf Heaps ein, müssen die Nachteile, die sich durch Aktualisierungen ergeben, berücksichtigt werden. Direkte Vorteile gegenüber einem Clustered Index sind auf dem ersten Blick nicht erkennbar und – teilweise – sogar kontra-produktiv. Wer dennoch auf Heaps als Speichermedium setzt, dem seien die folgenden Möglichkeiten ans Herz gelegt, um die Nachteile zu mildern.
NonClustered Index gegen LCK_U-Sperren
Die oben beschriebene Problematik mit Sperren lässt sich sehr leicht umgehen, indem man den Einsatz eines NonClustered Index in Erwägung zieht. Sofern eine Aktualisierung von Abfragen nicht zu einer parallelen Ausführung führt, kann man – unter Umständen – mit der SCH_M-Sperre auf der Tabelle leben; das hängt aber vom Workload ab, der auf die Tabelle einwirkt.
Schaut man sich die Aktualisierungsabfrage aus dem ersten Beispiel an, könnte daraus abgeleitet werden, dass ein Index auf dem Attribut [Order_Id] den Prozess optimieren kann.
UPDATE dbo.CustomerOrders
SET OrderDate = CAST(GETDATE() AS DATE)
WHERE Order_Id = 10000;
Das Attribut [Order_Id] ist eindeutig und ein entsprechender NonClustered Index wird wie folgt implementiert:
-- Implementation of unique nonclustered index
CREATE UNIQUE NONCLUSTERED INDEX nuix_CustomerOrders_Order_Id
ON dbo.CustomerOrders (Order_Id);
GO
Wird anschließend die Aktualisierung des Datensatzes durchgeführt, ergibt sich ein vollständig anderer Ausführungsplan.
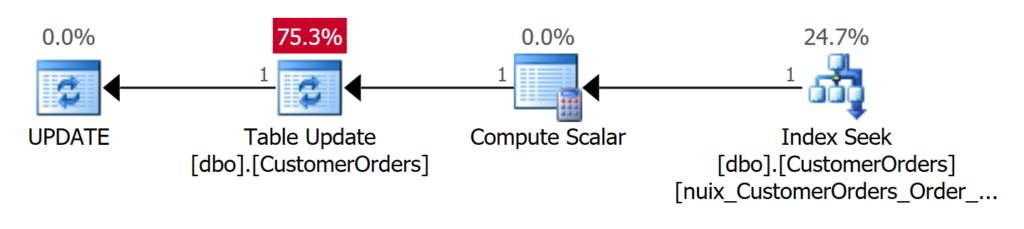
Microsoft SQL Server sucht effizient in dem zuvor angelegten NonClustered Index, um die entsprechende Order_Id zu finden. Durch die Row Locator Id (RID) kann Microsoft SQL Server mit einem I/O auf den betroffenen Datensatz im Heap springen und die Aktualisierung vornehmen.
Die benötigten Sperren reduzieren sich auf ein Minimum, wie in der Aufzeichnung durch die Extended Event Session erkennbar ist.

- Zunächst erhält die Tabelle eine IX-Sperre (Intent Exclusive), um zu signalisieren, dass auf Datenänderungen Schreibaktivitäten durchgeführt werden sollen (Zeile 381).
- Die Datenseite 78.742 ist der Leaf-Level des Nonclustered Index, der das zu suchende Schlüsselattribut [Order_Id] = 10000 besitzt. Diese Sperre wird vorsorglich gesetzt, da es ja sein könnte, dass auch der Index selbst aktualisiert werden könnte.
- Die Datenseite 2.179 betrifft den Datensatz, der im Heap gespeichert ist. Zunächst wird mittels einer U-Sperre signalisiert, dass Änderungen vorgenommen werden sollen, bevor zu zu einer X-Sperre (Exklusiv) umgewandelt wird, um die Änderungen zu implementieren.
Durch die Verwendung eines NonClustered Index werden gleich vier der oben beschriebenen Probleme eliminiert:
- Die Parallelisierung wird eliminiert
- Mögliche Lock Escalation wird verhindert, wenn die Ausführung nicht mehr parallelisiert
- Ein vollständiger Scan der Tabelle ist nicht mehr erforderlich, da über den NonClustered Index gezielt zu dem Datensatz gesprungen werden kann, der geändert werden soll. Dadurch lassen sich Sperren beim Scannen des Heaps vermeiden
- Es wird keine SCH_M Sperre mehr verwendet, da gezielt über den NonClustered Index auf die Daten zugegriffen werden kann.
Feste Satzlänge für Vermeidung von Forwarded Records
Forwarded Records sind ein echtes Problem bei Heaps, das nicht nur bei SELECT-Anweisungen nachteilig ist sondern besonders ineffizient bei Aktualisierungen von Attributen mit variablen Datenlängen ist.
Dem kann man entgegenwirken, indem man den Heap gleich so designed, dass Forwarded Records nicht mehr vorkommen können – Attribute mit Datentypen mit fester Datenlänge.
Der Nachteil dieses Konzepts ist jedoch, dass u. U. wertvolle Speicherressourcen verloren gehen.
-- Table with fixed length attributes
IF OBJECT_ID (N'dbo.demo_table', N'U') IS NOT NULL
DROP TABLE dbo.demo_table;
GO
/* Create the demo table for 20 records */
CREATE TABLE dbo.demo_table
(
Id INT NOT NULL IDENTITY (1, 1),
C1 CHAR(4000) NOT NULL
);
GO
/* Now insert 20 records into the table */
INSERT INTO dbo.demo_table (C1) VALUES
(REPLICATE('A', 2000)),
(REPLICATE('B', 2000)),
(REPLICATE('C', 2000)),
(REPLICATE('D', 2000));
GO 5
/* On what pages are the records stored? */
SELECT FPLC.*,
DT.*
FROM dbo.demo_table AS DT
CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%) AS FPLC;
GO

Die Abbildung zeigt, dass lediglich zwei Datensätze auf eine Datenseite passen. Der Vorteil liegt natürlich darin, dass keine Forwarded Records mehr produziert werden können, jedoch wird dieser Vorteil beim Speicherverbrauch teuer bezahlt.
Diese Lösung bietet sich nur an, wenn der Heap nicht zu groß ist und wenn tatsächlich häufig Aktualisierungen an den bestehenden Datensätzen vorgenommen werden.
Wer jedoch meint, dass diese Problematik bei einem Clustered Index nicht existiert, der irrt. In einem Clustered Index führt die Aktualisierung eines Datensatzes dazu, dass – wenn die Änderungen nicht mehr auf der Datenseite gespeichert werden können – ein Page Split durchgeführt wird.
Einzig die Besonderheit, dass Datenseiten mehrmals gelesen werden, spricht FÜR den Clustered Index. Das I/O bei Einzelzugriffen auf die Datensätze in einem Heap liegt bei maximal 2 I/O, wenn über einen NonClustered Index gesucht wird.
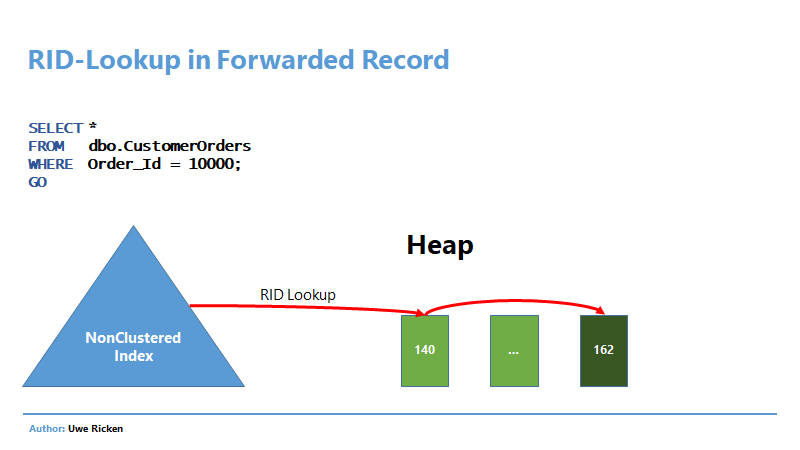
Zunächst wird nach dem Prädikat im NonClustered Index gesucht. Der Eintrag im Index verweist durch die RID auf die Originalseite (140), auf der sich der Datensatz befunden hatte. Auf Seite 140 steht jedoch statt des Datensatzes nur ein Verweis auf die aktuelle Seite, auf der sich der Datensatz durch die Aktualisierung befindet (162).
Partitionierung gegen Lock Escalation?
Insbesondere in Heaps mit einer hohen Anzahl von Datensätzen kann die Aktualisierung einzelner Datensätze dazu führen, dass eine Lock Escalation die vollständige Tabelle sperrt. Dieses Verhalten tritt jedoch nur unter folgenden Bedingungen auf:
- parallele Ausführung der Abfrage
- restriktiver Isolation Level
Damit nicht die vollständige Tabelle gesperrt wird, kann mit Hilfe von Partitionierung die Sperre auf die Partition beschränkt werden, in der sich die zu ändernden Daten befinden. Diese Option ist aber nur dann möglich, wenn das Prädikat der WHERE-Klausel dem Partitionsschlüssel entspricht.
Vielen Dank fürs Lesen!





