von Uwe Ricken | Aug. 20, 2019 | DB Engine, Indexierung, SQL Blog
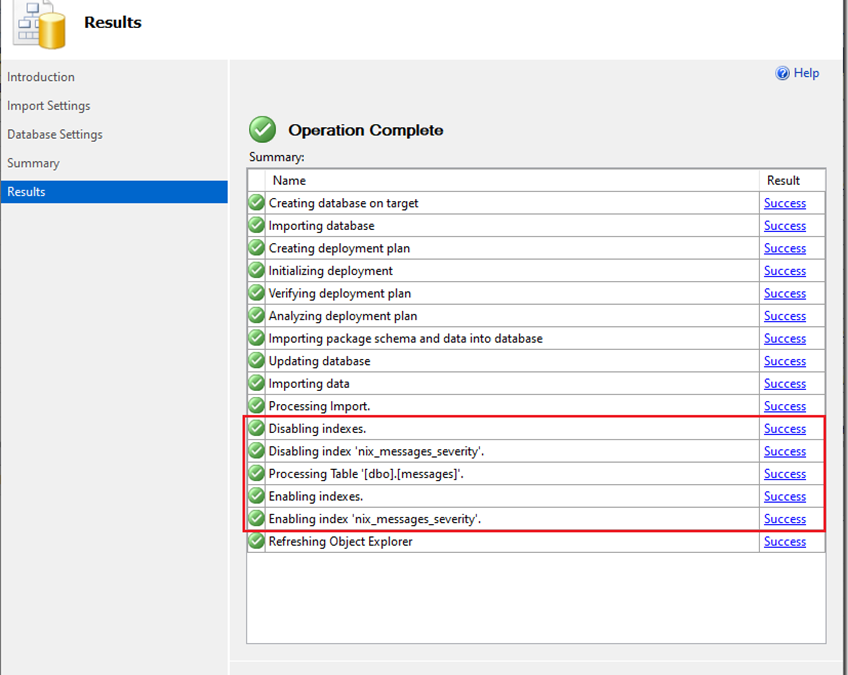
Vor kurzem erreichte mich die Email eines Teilnehmers von einem Workshop. In der Email wurde beschrieben, dass eine Abfrage, die in einer Datenbank [A] sehr schnell ausgeführt wird, nach dem Import auf dem gleichen Server als “Data Tier Application” ein sehr viel...
von Uwe Ricken | Feb. 26, 2017 | DB Engine, Indexierung, Optimierung, SQL Blog
Ein Kunde beklagte sich über die schlechte Ausführungsgeschwindigkeit einer Funktion, die er von einem Programmierer erhalten hatte. Bei der Durchsicht des Codes der Funktion war das Problem schnell gefunden. Statt eines performanten Indexseek hat die Abfrage einen...
von Uwe Ricken | Jan. 31, 2016 | 300, Indexierung, Optimierung, Tipps und Tricks
In einem aktuellen Projekt bin ich auf eine Technik gestoßen, die – LEIDER – noch viel zu häufig von Programmierern im Umfeld von Microsoft SQL Server angewendet wird; Konkatenation von Texten zu vollständigen SQL-Befehlen und deren Ausführung mittels EXEC(). Dieser...
von Uwe Ricken | Sep. 9, 2015 | 400, Administration, Indexierung, SQL Blog, Tipps und Tricks
Während der Erstellung eines Artikels für SIMPLE-TALK kam ein sehr interessanter Aspekt in Bezug auf HEAPS in Verbindung mit non-clustered Indexen in den Fokus: „Wird beim Neuaufbau eines non-clustered Index die Position des Forwarded Record im non-clustered...
von Uwe Ricken | Aug. 2, 2015 | 300, DB Engine, Indexierung, Optimierung, SQL Blog, Tipps und Tricks
Bei der täglichen Arbeit mit Microsoft SQL Server in mittelständischen und großen Unternehmen kommt es immer wieder mal vor, dass Programmcodes in die Testsysteme und Produktionssysteme implementiert werden mussten. Beim durchgeführten Code Review stößt man immer...
von Uwe Ricken | Juni 15, 2015 | Administration, Allgemein, DB Engine, Indexierung, SQL Blog
Welche Strategie ist am besten geeignet, um Daten, die temporär für weitere Aufgaben benötigt werden, zu speichern und zu verwalten? Mit Microsoft SQL Server 2000 wurden zum ersten Mal Tabellenvariablen als Erweiterung eingeführt. Die Arbeit mit temporären Tabellen...





