Heaps sind nicht unbedingt des Entwicklers liebstes Kind, da sie insbesondere bei der Auswahl von Daten nicht sehr performant sind (so denken die meisten!). Sicherlich ist da etwas Wahres dran – aber letztendlich entscheidet immer der Workload. In diesem Artikel beschreibe ich die Arbeitsweise eines Heaps, wenn Daten selektiert werden.
Inhaltsverzeichnis
Daten in Heap selektieren
Da ein Heap keine Indexstrukturen aufweist, muss Microsoft SQL Server immer die komplette Tabelle lesen. Das Problem bei Prädikaten löst Microsoft SQL Server mit einem FILTER-Operator (Predicate Pushdown)
Für alle in diesem Artikel gezeigten Beispiele erstelle ich eine Tabelle mit ~4.000.000 Datensätzen aus meiner Demo-Datenbank [CustomerOrders].
-- Create a BIG table with ~4.000.000 rows
SELECT C.ID AS Customer_Id,
C.Name,
A.CCode,
A.ZIP,
A.City,
A.Street,
A.[State],
CO.OrderNumber,
CO.InvoiceNumber,
CO.OrderDate,
CO.OrderStatus_Id,
CO.Employee_Id,
CO.InsertUser,
CO.InsertDate
INTO dbo.CustomerOrderList
FROM CustomerOrders.dbo.Customers AS C
INNER JOIN CustomerOrders.dbo.CustomerAddresses AS CA
ON (C.Id = CA.Customer_Id)
INNER JOIN CustomerOrders.dbo.Addresses AS A
ON (CA.Address_Id = A.Id) INNER JOIN CustomerOrders.dbo.CustomerOrders AS CO
ON (C.Id = CO.Customer_Id)
ORDER BY
C.Id,
CO.OrderDate
OPTION (MAXDOP 1);
GO
Wenn Daten aus einem Heap gelesen werden, wird im Ausführungsplan ein TABLE SCAN Operator verwendet – unabhängig von der Anzahl der Datensätze, die an den Client geliefert werden müssen.
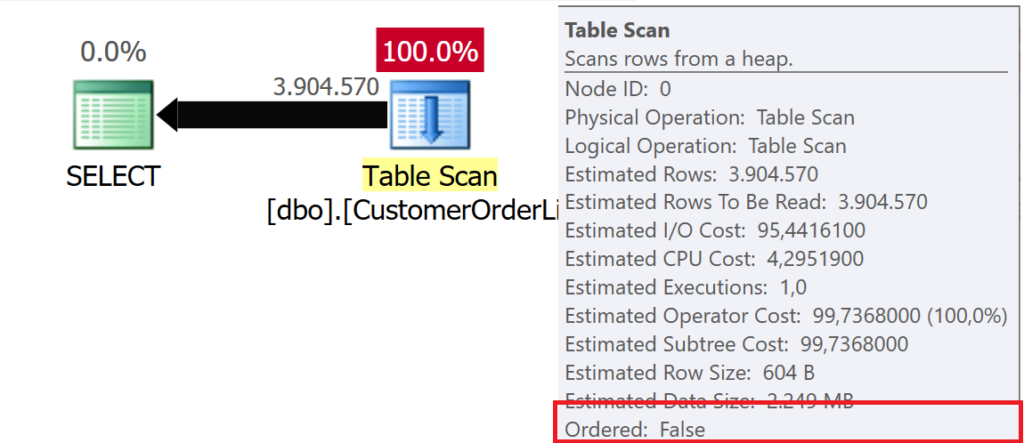
Wenn Microsoft SQL Server Daten aus einer Tabelle liest, kann das auf zwei Arten erfolgen:
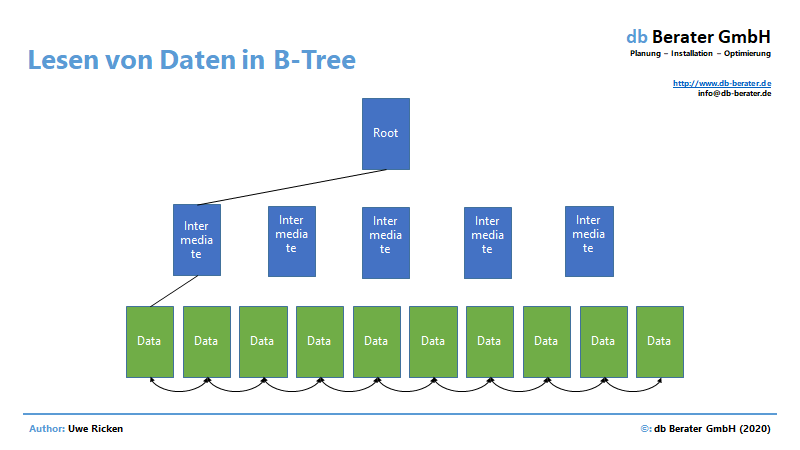
- Die Datenauswahl folgt der B-Tree-Struktur eines Indexes
- Die Datenauswahl erfolgt gem. der logischen Anordnung von Datenseiten
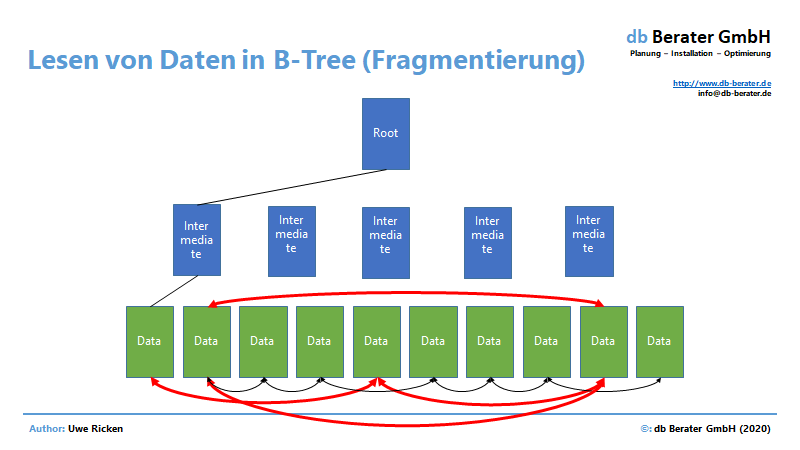
In einem Heap erfolgt der Leseprozess in der Reihenfolge, in der Daten auf den Datenseiten gespeichert wurden. Informationen über die Datenseiten des Heaps liest Microsoft SQL Server aus der IAM-Seite einer Tabelle, die im Artikel „Heaps – Systemstrukturen“ beschrieben wird.
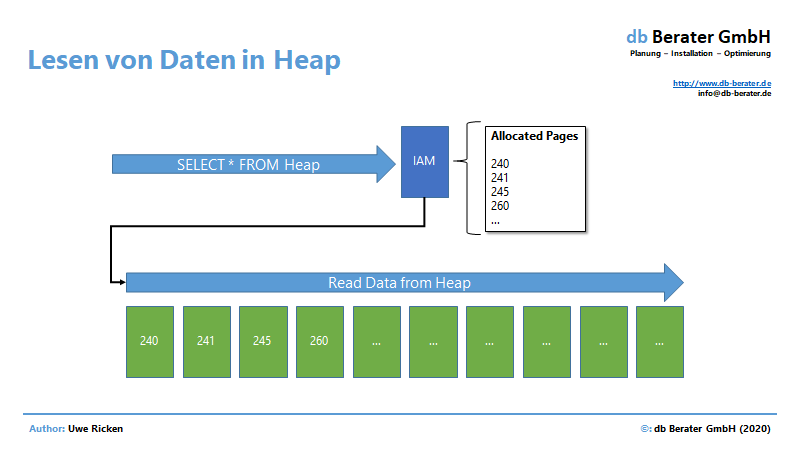
Nachdem die „Route“ für das Lesen der Daten aus der IAM ausgelesen wurde, beginnt der SCAN-Prozess, um die Daten an den Client zu senden. Diese Technik wird „Allocation Order Scan“ genannt und ist vor allen Dingen bei Heaps zu beobachten.
Werden die Daten durch ein Prädikat eingegrenzt, ändert sich die Arbeitsweise nicht. Da die Daten in einem Heap unsortiert vorliegen, muss Microsoft SQL Server immer die vollständige Tabelle (Alle Datenseiten) durchsuchen.
SELECT * FROM dbo.CustomerOrderList
WHERE Customer_Id = 10;
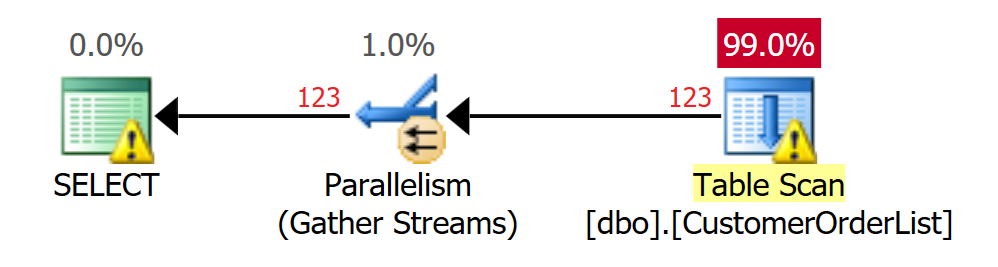
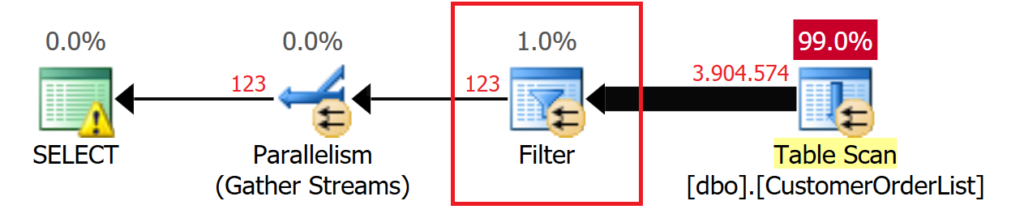
Die Filterung wird „Pushdown-Prädikat“ genannt; bevor weitere Prozesse verarbeitet werden, wird die Anzahl der Datensätze so weit wie möglich reduziert! Ein Pushdown-Prädikat kann mit Hilfe des Traceflags 9130 im Ausführungsplan sichtbar gemacht werden!
SELECT * FROM dbo.CustomerOrderList
WHERE Customer_Id = 10
OPTION (QUERYTRACEON 9130);
Vorteile beim Lesen aus Heaps
Scheinbar sind Heaps beim Lesen von Daten einem Index unterlegen. Diese Aussage trifft aber nur dann zu, wenn eine Eingrenzung der Daten durch ein Prädikat erreicht werden soll.
Tatsächlich hat der Heap beim Lesen der kompletten Tabelle zwei – aus meiner Sicht – wesentliche Vorteile:
- Es muss keine B-Tree-Struktur gelesen werden; es werden ausschließlich die Datenseiten gelesen.
- Ist der Heap nicht fragmentiert und besitzt keine Forwarded Records (wird in einem späteren Artikel beschrieben), können Heaps sequentiell gelesen werden. Daten werden also in der Reihenfolge ihrer Eintragungen vom Storage gelesen.
- Ein Index folgt immer den Pointern zur nächsten Datenseite. Ist der Index fragmentiert, entstehen Random Reads, die nicht so leistungsfähig sind, wie sequentielle Leseoperationen.
Nachteile beim Lesen aus Heaps
Einer der größten Nachteile beim Lesen von Daten aus einem Heap ist der IAM-Scan während des Lesens der Daten. Diese Sperre muss von Microsoft SQL Server gehalten werden, um sicherzustellen, dass während des Lesevorgangs die Metadaten der Tabellenstruktur nicht verändert werden.
CREATE EVENT SESSION [Track Lockings]
ON SERVER
ADD EVENT sqlserver.lock_acquired
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.lock_released
(ACTION (package0.event_sequence)
WHERE
(
sqlserver.session_id = 55
AND mode = 1
)
),
ADD EVENT sqlserver.sql_statement_completed
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
),
ADD EVENT sqlserver.sql_statement_starting
(ACTION (package0.event_sequence)
WHERE (sqlserver.session_id = 55)
)
WITH
(
MAX_MEMORY = 4096KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
);
Mit dem oben abgebildeten Code wird ein Extended Event erstellt, dass alle in einer Transaktion gesetzten Sperren aufzeichnet. Das Skript zeichnet nur für eine vordefinierten Benutzersitzung die Aktivitäten auf.

Erst, wenn die SCAN-Operation abgeschlossen ist, wird die Sperre wieder aufgehoben.
Hinweis
Entscheidet sich Microsoft SQL Server bei der Ausführung der Abfrage für einen parallelen Plan, hält JEDER Thread eine SCH-S Sperre auf der Tabelle.
In einem hoch konkurrierenden System sind solche Sperren nicht gewünscht, da sie Operationen serialisieren. Je größer der Heap ist, um so länger werden die Sperren weitere Metadaten-Operationen verhindern:
- Erstellen von Indexen
- Neuaufbau von Indexen
- Hinzufügen oder Löschen von Spalten
- TRUNCATE-Operationen
- …
Ein weiteres „Manko“ von Heaps kann die hohe Anzahl von I/O sein, wenn nur kleinere Datenmengen ermittelt werden müssen. Hier bietet sich aber die Verwendung eines NONCLUSTERED INDEX an, um die Operationen zu optimieren.
SELECT-Operationen optimieren
Wie bereits weiter oben ausgeführt, muss Microsoft SQL Server die Tabelle immer vollständig lesen, wenn eine SELECT-Anweisung ausgeführt wird. Da Microsoft SQL Server einen Allocation Order Scan durchführt, werden die Daten in der Reihenfolge ihrer logischen Speicherorte gelesen.
Verwendung des TOP-Operators
Mit Hilfe des TOP (n) Operators „kann“ man Glück haben, wenn die betroffenen Datensätze auf den ersten Datenseiten des Heaps gespeichert wurden.
-- Select the very first record
SELECT TOP (1) * FROM dbo.CustomerOrderList
OPTION (QUERYTRACEON 9130);
GO
-- Select the very first record with a predicate
-- which determines a record at the beginning of
-- the heap
SELECT TOP (1) * FROM dbo.CustomerOrderList
WHERE Customer_Id = 41483
OPTION (QUERYTRACEON 9130);
GO
-- Select the very first record with a predicate
-- which determines a record at any position in
-- the heap
SELECT TOP (1) * FROM dbo.CustomerOrderList
WHERE Customer_Id = 22844
OPTION (QUERYTRACEON 9130);
GO
Der obige Code führt drei Abfragen unter Verwendung des TOP-Operators aus. Die erste Abfrage findet den physikalisch ersten Datensatz, der in der Tabelle abgespeichert wurde.
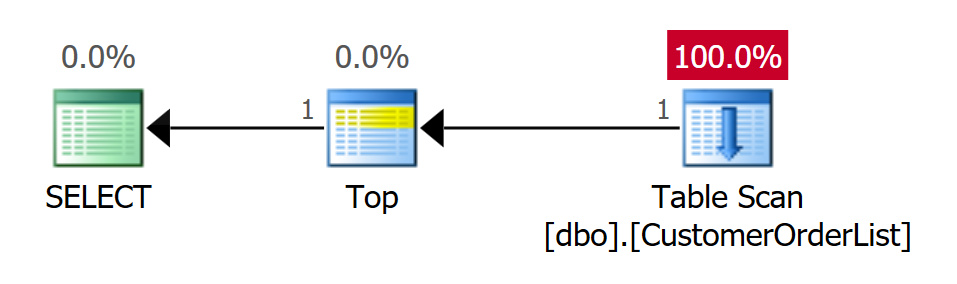
Der Ausführungsplan verwendet – wie erwartet – einen Table Scan Operator. Das ist der einzige Operator, der für einen Heap verwendet werden kann. Der TOP-Operator verhindert jedoch, dass die Tabelle vollständig durchsucht werden muss. Wenn die Anzahl der Datensätze erreicht wurde, die an den Client geliefert werden sollen, bricht der TOP-Operator die Verbindung zum Table Scan ab und der Prozess ist beendet.
Hinweis
Obwohl nur ein Datensatz ermittelt werden soll, wird eine SCH-S Sperre auf die Tabelle gesetzt!
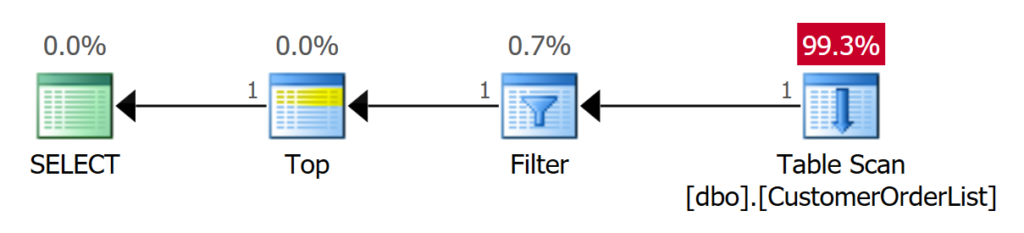
Die zweite Abfrage benötigt ebenfalls nur 1 I/O. Das liegt aber daran, dass der gesuchte Datensatz der erste Datensatz in der Tabelle ist. Dennoch muss Microsoft SQL Server einen FILTER-Operator für das Prädikat verwenden. Der TOP Operator bricht nach Erhalt des ersten Datensatzes die nachfolgenden Operationen sofort ab.
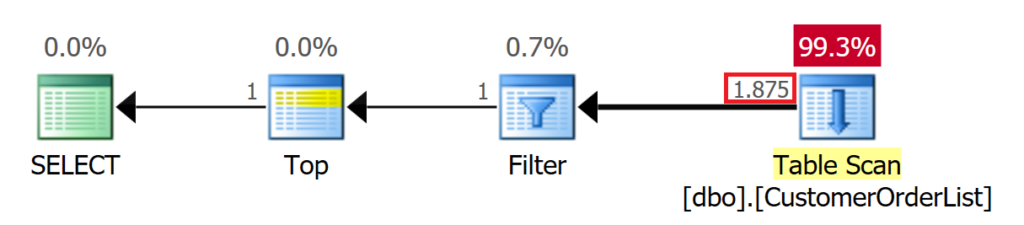
Die dritte Abfrage verwendet ein Prädikat, das einen Datensatz erst an der 1.875 Position findet. In diesem Sachverhalt muss Microsoft SQL Server weitaus mehr Datenseiten lesen, bevor der Prozess die gewünschte Ergebnismenge hat und automatisch den Prozess beendet.
Als Fazit bleibt hier festzuhalten, dass ein TOP-Operator hilfreich sein kann; in der Praxis ist das aber eher nicht der Fall, da die Anzahl der zu lesenden Datenseiten immer von der gespeicherten Position des Datensatzes abhängig ist.
Komprimierung
Scheinbar ist es nicht möglich, das I/O für Operationen in einem Heap zu reduzieren (es müssen immer alle Datenseiten gelesen werden!), hilft für die Reduzierung von I/O die Komprimierung der Daten.
Hierfür stellt Microsoft SQL Server zwei Arten der Datenkomprimierung zur Verfügung:
- Zeilenkomprimierung
- Seitenkomprimierung
Hinweis
Für die Datenkomprimierung stehen noch die Optionen „ColumnStore“ und „ColumnStore_Archive“ zur Verfügung. Diese Komprimierungsarten können jedoch nicht auf einen Heap angewendet werden, sondern nur auf Columnstore-Indexen!
Für Heaps und partitionierte Heaps kann die Datenkomprimierung ein deutlicher Vorteil in Bezug auf I/O sein. Für die Komprimierung von Daten in einem Heap gelten jedoch ein paar Besonderheiten, die beachtet werden müssen:
Wenn ein Heap zur Komprimierung auf Seitenebene konfiguriert wird, erfolgt die Komprimierung mit folgenden Methoden:
- Die Zuordnung neuer Datenseiten in einem Heap als Teil von DML-Vorgängen verwendet die Seitenkomprimierung erst nach der Neuerstellung des Heaps.
- Die Änderung der Komprimierungseinstellung für einen Heap erzwingt die Neuerstellung aller Nonclustered Indexe, da die Positionszuordnungen neu geschrieben werden müssen.
- Die ROW- bzw. die PAGE-Komprimierung kann online oder offline aktiviert und deaktiviert werden.
- Die Online-Aktivierung der Komprimierung für einen Heap erfolgt mit einem einzelnen Thread.
Ob die Komprimierung von Tabellen und/oder Indexen tatsächlich einen Vorteil bringt, kann mit Hilfe der Systemprozedur [sp_estimate_data_compression_savings] ermittelt werden.
DECLARE @Result TABLE
(
Data_Compression CHAR(4) NOT NULL DEFAULT '---',
object_name SYSNAME NOT NULL,
schema_name SYSNAME NOT NULL,
index_id INT NOT NULL,
partition_number INT NOT NULL,
current_size_KB BIGINT NOT NULL,
request_size_KB BIGINT NOT NULL,
sample_size_KB BIGINT NOT NULL,
sample_request_KB BIGINT NOT NULL
);
-- Evaluate the savings by compression of data
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number, current_size_KB, request_size_KB, sample_size_KB, sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'PAGE';
UPDATE @Result
SET Data_Compression = 'PAGE'
WHERE Data_Compression = '---';
-- Evaluate the savings by compression of data
INSERT INTO @Result
(object_name, schema_name, index_id, partition_number, current_size_KB, request_size_KB, sample_size_KB, sample_request_KB)
EXEC sp_estimate_data_compression_savings
@schema_name = 'dbo',
@object_name = 'CustomerOrderList',
@index_id = 0,
@partition_number = NULL,
@data_compression = 'ROW';
UPDATE @Result
SET Data_Compression = 'ROW'
WHERE Data_Compression = '---';
SELECT Data_Compression,
current_size_KB,
request_size_KB
FROM @Result;
GO
Mit dem obigen Skript wird die mögliche Einsparungen des Datenvolumens für die Zeilen- und Datenseitenkomprimierung ermittelt.

Beide Komprimierungsraten versprechen eine Einsparung von >30%. In der Realität stellen sich die Vergleiche für einen vollständigen Table Scan wie folgt dar:
| Compression | Elapsed Time | I/O | CPU | Parallelism |
|---|---|---|---|---|
| None | 2.721 ms | 128.844 | 8.812 ms | 4 Cores |
| PAGE | 4.315 ms | 83.050 | 14.827 ms | 4 Cores |
| ROW | 3.957 ms | 88.813 | 12.936 ms | 4 Cores |
Die Messungen zeigen das Problem der Datenkomprimierung. Zwar wird das I/O deutlich reduziert; das Einsparpotenzial wird jedoch durch die erhöhte CPU-Verwendung wieder „aufgefressen“.
Als Fazit für die Datenkomprimierung bleibt festzuhalten, dass es sicherlich eine Option sein kann, um das I/O zu reduzieren. Leider wird dieser „Vorteil“ schnell wieder durch den überproportionalen Konsum anderer Ressourcen (CPU) zunichte gemacht. Hat man ein System mit ausreichend schnellen Prozessoren in höherer Zahl, sollte man diese Option in Betracht ziehen. Ansonsten sollte man sich zu Gunsten der CPU-Ressourcen entscheiden; das gilt um so mehr bei Systemen mit sehr vielen Einzelzugriffen.
Ebenfalls sollte man vor dem Einsatz von Komprimierungstechniken sehr sorgfältig seine Applikation überprüfen. Microsoft SQL Server erstellt Ausführungspläne, die sehr stark auf das geschätzte I/O berücksichtigt. Wird z. Bl durch die Verwendung einer Komprimierung deutlich weniger I/O generiert, kann es dazu führen, dass ein Ausführungsplan geändert wird (aus einem HASH- oder MERGE-Operator wird ein NESTED LOOP-Operator).
Wer glaubt, dass durch die Datenkomprimierung Arbeitsspeicher (sowohl für den Bufferpool als auch für SORT-Operationen) gespart wird, der irrt!
- Daten liegen im Bufferpool immer dekomprimiert vor
- Ein SORT-Operator berechnet seinen Bedarf an Arbeitsspeicher anhand der zu verarbeitenden Datensätze
Partitionierung
Mit Hilfe von Partitionierung werden Tabellen horizontal aufgeteilt. Dabei werden mehrere Gruppen gebildet, die innerhalb der Grenzen von Partitionen liegen.
Hinweis
Partitionierung ist ein sehr komplexes Thema und kann im Rahmen dieser Artikelreihe nicht detailliert behandelt werden. Mehr Informationen zu Partitioning findet man in der Online-Dokumentation von Microsoft SQL Server:
https://docs.microsoft.com/de-de/sql/relational-databases/partitions/partitioned-tables-and-indexes
Eine von mir sehr geschätzte Kollegin aus Norwegen (Cathrine Wilhelmsen (b | t) hat ebenfalls eine sehr bemerkenswerte Artikelserie zu Partitionierung geschrieben, die hier nachgelesen werden kann.
Der Vorteil von Partitionierung von Heaps kann nur greifen, wenn im Heap nach Prädikatsmustern gesucht wird, die dem Partitionsschlüssel entsprechen. Sofern nicht nach dem Partitionsschlüssel gesucht wird, kann Partitionierung nicht wirklich bei der Suche nach Daten helfen.
Anwender suchen in der Demotabellen häufig nach Aufträgen, die sich über einen Zeitraum bewegen.
-- Find all orders from 2016
SELECT * FROM dbo.CustomerOrderList
WHERE OrderDate >= '20160101'
AND OrderDate <= '20161231'
ORDER BY
Customer_Id,
OrderDate DESC
OPTION (QUERYTRACEON 9130);
GO

Für die Ausführung der Abfrage musste Microsoft SQL Server die vollständige Tabelle durchsuchen. Das macht sich sowohl im I/O als auch in der CPU-Belastung bemerkbar!
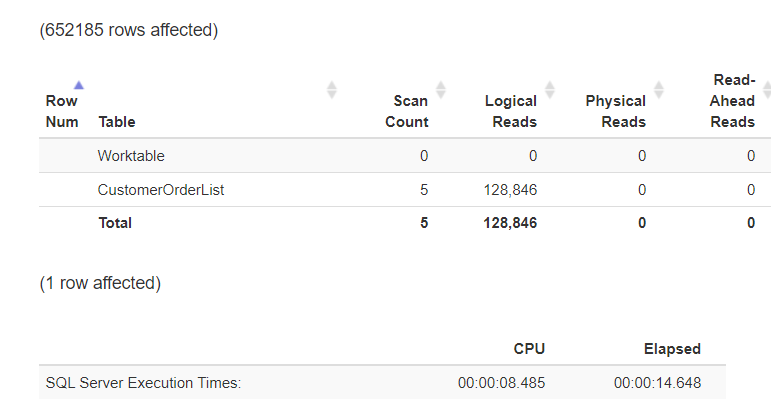
Ohne Index besteht keine Möglichkeit, das I/O oder die CPU-Last zu reduzieren. Eine Reduktion kann nur dadurch erfolgen, dass die zu lesende Datenmenge reduziert wird. Aus diesem Grund wird die Tabelle so partitioniert, dass für jedes Jahr eine eigene Partition verwendet wird.
Die Daten für die einzelnen Jahre werden auf 20 Jahre aufgesplittet und das Ergebnis sieht wie folgt aus:
SELECT p.partition_number AS [Partition #],
CASE pf.boundary_value_on_right
WHEN 1 THEN 'Right / Lower'
ELSE 'Left / Upper'
END AS [Boundary Type],
prv.value,
stat.row_count,
stat.in_row_reserved_page_count
FROM sys.partition_functions AS pf
INNER JOIN sys.partition_schemes AS ps
ON ps.function_id=pf.function_id
INNER JOIN sys.indexes AS si
ON si.data_space_id=ps.data_space_id
INNER JOIN sys.partitions AS p
ON
(
si.object_id=p.object_id
AND si.index_id=p.index_id
)
LEFT JOIN sys.partition_range_values AS prv
ON
(
prv.function_id=pf.function_id
AND p.partition_number= CASE pf.boundary_value_on_right
WHEN 1 THEN prv.boundary_id + 1
ELSE prv.boundary_id
END
)
INNER JOIN sys.dm_db_partition_stats AS stat
ON
(
stat.object_id=p.object_id
AND stat.index_id=p.index_id
AND stat.index_id=p.index_id
AND stat.partition_id=p.partition_id
AND stat.partition_number=p.partition_number
)
ORDER BY
[Partition #];
GO
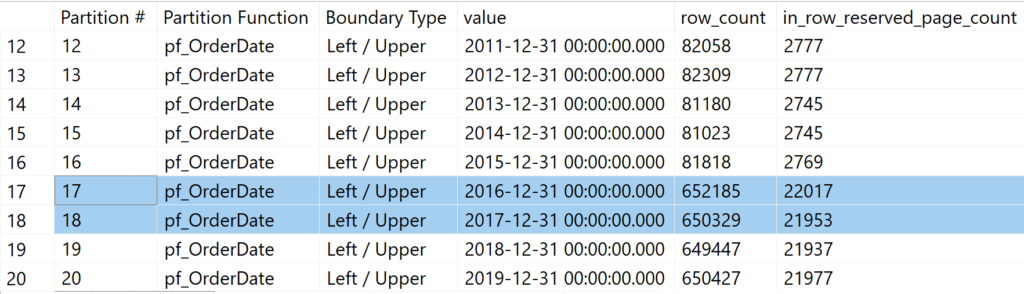
Wird die zuvor ausgeführte Abfrage auf Basis einer Partitionierung auf der Prädikatsspalte ausgeführt, ergibt sich daraus ein komplett anderes Laufzeitverhalten:
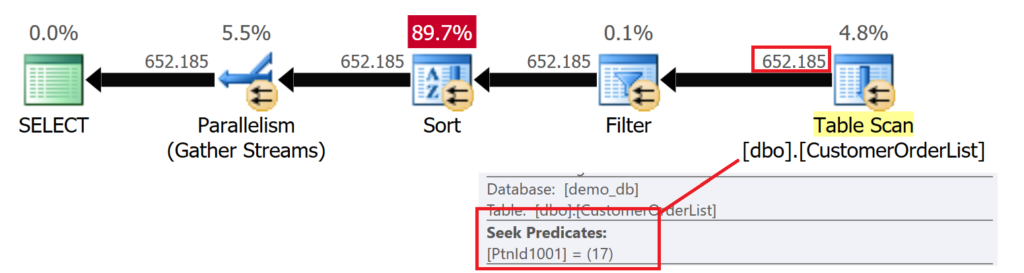
Microsoft SQL Server erkennt anhand der Grenzen für die Partitionen, in welcher Partition die zu suchenden Werte vorkommen können. Andere Partitionen werden nicht mehr berücksichtigt und somit von dem Table Scan „ausgeschlossen“.
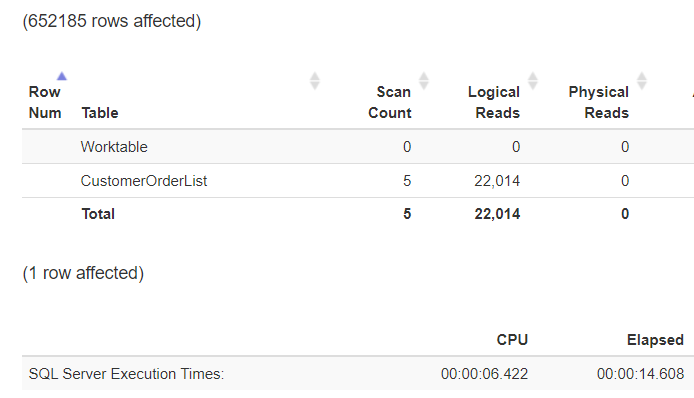
Die Laufzeit hat sich nicht wesentlich verändert (der Anzahl der Datensätze, die an den Client gesendet werden, hat sich ja nicht geändert!) aber man kann sehr gut erkennen, dass die CPU-Last um ca. 25% reduziert wurde.
Ist der ganze Workload auf I/O und nicht auf die CPU-Last fokussiert, besteht als letzte Möglichkeit der Reduktion die Kompression der Daten auf Partitionsebene!
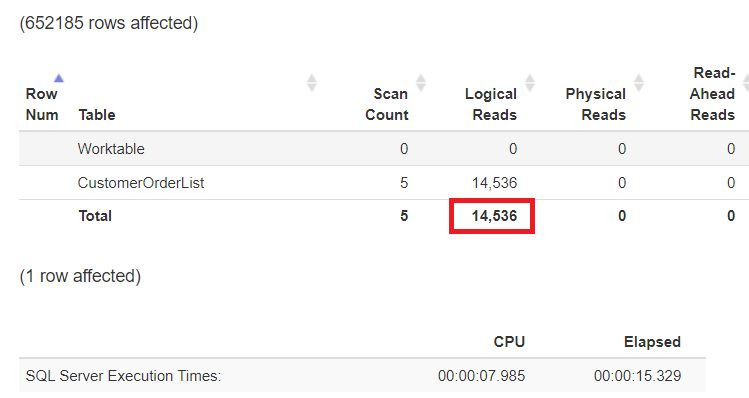
ALTER TABLE dbo.CustomerOrderList
REBUILD PARTITION = 17 WITH (DATA_COMPRESSION = ROW);
GO
Der Ausführungsplan ändert sich nicht, jedoch kann das I/O noch einmal deutlich reduziert werden!
Zusammenfassung
Heaps sind einem Index hoffnungslos unterlegen, wenn es darum geht, höchst selektiv Daten zu eruieren. Sofern jedoch – wie z. B. in einem DWH – große Datenmengen verarbeitet werden müssen, kann ein Heap eher punkten. Voraussetzungen und technische Möglichkeiten für eine solche Anwendung habe ich hoffentlich mit diesem Artikel aufzeigen können.
Herzlichen Dank fürs Lesen!





