Wer täglich mit Microsoft SQL Server arbeitet – sei es als DBA oder als Entwickler – wird sich schon mal mit dem Problem von Parameter Sniffing auseinandergesetzt haben. “Parameter Sniffing” bedeutet, dass Microsoft SQL Server beim Ausführen einer Stored Procedure/parametrisierten Abfrage den Übergabeparameter verwendet, um die Kardinalität des Wertes zu bestimmen und zukünftige Ausführungen der Abfrage auf Basis des ERSTEN Übergabeparameters durchführt. Die Kardinalität des Parameters fließt in die Bestimmung der Abfragestrategie mit ein. Die Abfragestrategie wird als Ausführungsplan im Plancache abgelegt. Dieser Artikel beschäftigt sich mit den Problemen, die sich aus dieser Arbeitsweise ergeben und zeigt mögliche Lösungsansätze.
Inhaltsverzeichnis
Testumgebung
Um das Problem von Parameter Sniffing darzustellen, wird eine Testtabelle mit ca. 10.000 Datensätzen (je nach Version von Microsoft SQL Server) benötigt. Ebenfalls wird eine Stored Procedure für die Ausführung der standardisierten Abfragen verwendet.
Tabelle
Als Datengrundlage dient eine Tabelle mit dem Namen [dbo].[Mitarbeiter]. Aus Gründen der Vereinfachung wird ein Attribut mit einer Datenlänge von 1.000 Bytes verwendet um „Volumen“ zu generieren.
-- Erstellen der Demotabelle
CREATE TABLE dbo.Mitarbeiter
(
Id INT NOT NULL IDENTITY(1,1),
Name CHAR(1000) NOT NULL,
CostCenter CHAR(7) NOT NULL
);
GO
-- Befüllen der Tabelle mit ca. 10.000 Datensätzen
INSERT INTO dbo.Mitarbeiter WITH (TABLOCK) (Name, CostCenter)
SELECT CAST(text AS CHAR(1000)),
'C' + RIGHT(REPLICATE('0', 6) + CAST(severity AS VARCHAR(4)), 6)
FROM sys.messages
WHERE language_id = 1033;
GO
-- Erstellung der benötigten Indexe
CREATE UNIQUE CLUSTERED INDEX cuix_Mitarbeiter_Id ON dbo.Mitarbeiter (Id);
CREATE NONCLUSTERED INDEX nix_Mitarbeiter_CostCenter ON dbo.Mitarbeiter (CostCenter);
GO
Die Verteilung der Schlüsselwerte des Indexes [nix_Mitarbeiter_CostCenter] kann aus dem Histogramm der gespeicherten Statistiken entnommen werden:
-- Verteilung der Kostenstellen DBCC SHOW_STATISTICS (N'dbo.Mitarbeiter', N'nix_Mitarbeiter_CostCenter') WITH HISTOGRAM;
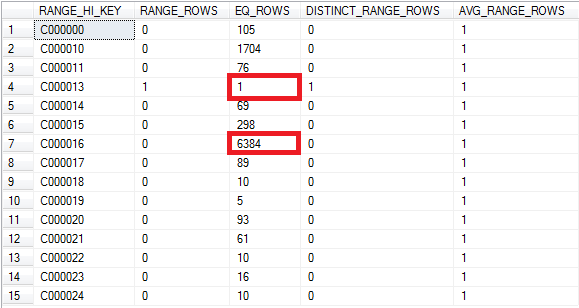
Die Analyse der Verteilung von Kostenstellen zeigt, dass es nur einen Datensatz gibt, der die Kostenstelle „C000013“ als Eintrag gespeichert hat während über 6.300 Einträge zur Kostenstelle „C000016“ vorhanden sind.
Prozedur
Für den Zugriff auf die Daten wird eine Stored Procedure erstellt, die als Parameter die gewünschte Kostenstelle bereitstellt.
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle
@CostCenter CHAR(7)
AS
SET NOCOUNT ON;
SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter
WHERE CostCenter = @CostCenter;
SET NOCOUNT OFF;
GO
Problemstellung
Sobald Microsoft SQL Server ein SQL-Statement ausführt, wird der generierte Ausführungsplan im Plan Cache gespeichert, um beim nächsten Aufruf des SQL Statements wiederverwendet zu werden. Dieses Verfahren ist bei komplexen Abfragen ein gewünschter Effekt. Bei der ersten Ausführung der Prozedur mit verschiedenen Parametern werden unterschiedliche Ausführungspläne generiert.
EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000016';
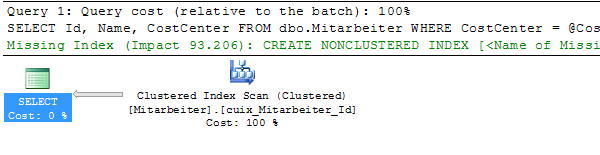
EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000013';
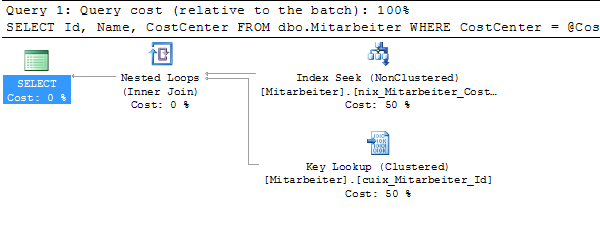
Die unterschiedlichen Ausführungspläne kommen zustande, da Microsoft SQL Server unter anderem das zu generierende I/O berücksichtigt. Ein INDEX SEEK (wie z. B. mit Kostenstelle C000013) verursacht zusätzliche 3 I/O pro gefundenen Datensatz. Würde für die Suche nach der Kostenstelle C000016 dieser Ausführungsplan verwendet, so würden insgsamt > 19.000 I/O nur für die Key Lookups produziert werden. Ein TABLE SCAN verursacht lediglich 1.300 I/O.
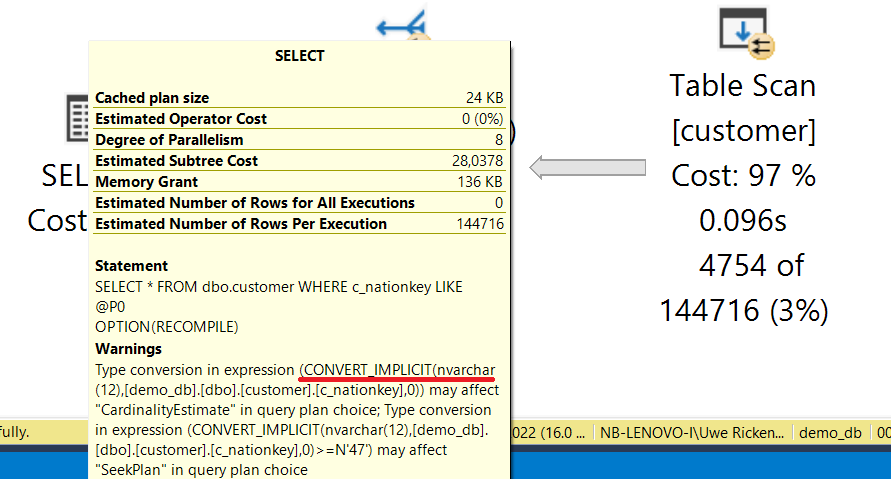
Entscheidend für die Performance der Stored Procedure ist – und genau das ist das Problem von Parameter Sniffing – die initiale Ausführung der Prozedur. Das folgende Beispiel zeigt die beiden Ausführungspläne, wenn zu Beginn (Plan Cache ist leer!) die Abfrage auf die Kostenstelle „C000013“ ausgeführt wird. Anschließend (der Ausführungsplan ist nun im Plan Cache) wird die Stored Procedure mit dem Wert „C000016“ für die Kostenstelle ausgeführt:
EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000013'; GO EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000016'; GO
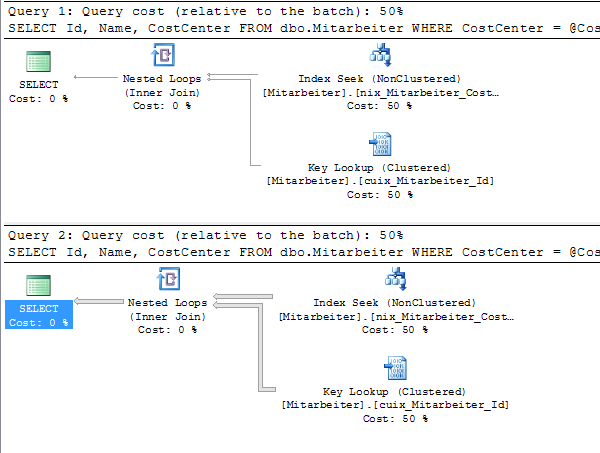
Bei der ersten Ausführung wird der Parameterwert „C000013“ von Microsoft SQL Server verwendet, um einen Ausführungsplan zu erzeugen. Dieser Ausführunsplan wird im Plan Cache gespeichert. Bei der zweiten Ausführung erkennt Microsoft SQL Server, dass der Ausführungsplan bereits vorhanden ist und verwendet ihn erneut. Hierbei kommt es dann jedoch zu einem gravierenden Nachteil; die Prozedur wurde unter der Annahme zwischengespeichert, dass nur 1 (!!!) Datensatz zurückgeliefert wird. Tatsächlich werden aber bei der zweiten Ausführung > 6.000 Datensätze geliefert. Ein Blick auf die Eigenschaften des gespeicherten Ausführungsplans verdeutlicht das Problem:
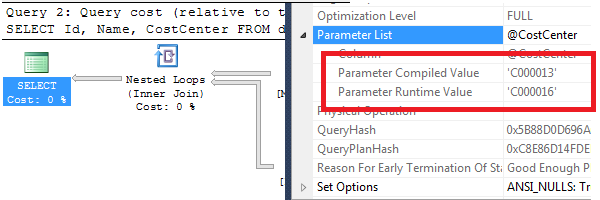
Die Strategie des gespeicherten Ausführungsplans basiert auf dem „Parameter Compiled Value“ während die Ausführung durch den „Parameter Runtime Value“ geprägt ist. Ist der Ausführungsplan für die initiale Kostenstelle ideal gewesen, dreht er für die erneute Verwendung mit anderen Parameterwerten ins Gegenteil. Dieses Problem wird Parameter Sniffing genannt. Die Frage, die jeden Programmierer in einem solchen Fall umtreibt: Wie kann man das Problem minimieren/verhindern?
Lösungsansätze
Das Speichern eines Ausführungsplans ist ein essentieller Bestandteil in der Optimierungsphase von Microsoft SQL Server. Wird ein Ausführungsplan im Plan Cache gespeichert, kann Microsoft SQL Server bei der Ausführung der Prozedur sowohl den Kompiliervorgang als auch den Optimierungsvorgang überspringen und die Prozedur unmittelbar ausführen. Für die Prozedur im Beispiel mag ein RECOMPILE nicht ins Gewicht fallen; aber man sollte nicht nur die absolute Zeit berücksichtigen sondern auch im Fokus behalten, wie stark die Prozedur innerhalb der Applikation genutzt wird. Sind es nur ein paar hundert Aufrufe am Tag oder millionenfache Aufrufe – das kann einen nicht unerheblichen Einfluss auf die Performance der Anwendung haben. Aus diesem Grund müssen unterschiedliche Optimierungsmöglichkeiten in Betracht gezogen werden.
Neukompilierung
Das generelle Problem von Parameter Sniffing ist der gespeicherter Ausführungsplan. Ziel des ersten Lösungsansatzes ist es, das Speichern von Ausführungsplänen zu vermeiden oder aber – abhängig vom Parameterwert – einen idealen Plan zu finden.
Neukompilierung durch Applikation
Sofern eine direkte Einflussnahme in den Applikationscode möglich ist, gibt es zwei Ansätze, um eine Neukompilierung zu erzwingen.
Manipulation von Planattributen
Ein Ausführungsplan speichert viele Informationen. Unter den vielen Informationen (z. B. Ausführungstext, Strategie, etc…) gibt es sogenannte Planattribute. Bei diesen Planattributen unterscheidet man zwischen cacherelevanten Einstellungen und nichtrelevanten Einstellungen.
SELECT A.*
FROM sys.dm_exec_query_stats AS S
CROSS APPLY sys.dm_exec_sql_text (S.sql_handle) AS T
CROSS APPLY
(
SELECT *
FROM sys.dm_exec_plan_attributes(S.plan_handle)
WHERE is_cache_key = 1
) AS A
WHERE T.text LIKE '%dbo.Mitarbeiter_pro_Kostenstelle%'
AND T.text NOT LIKE '%sys.dm_exec_sql_text%';
Der obige Code liefert alle cacherelevante Einstellungen, die Bestandtei des Ausführungsplans sind. Werden Einstelungen VOR der Ausführung der Prozedur geändert, wird ein neuer Ausführungsplan generiert, sofern nicht bereits ein Ausführungsplan vorhanden ist.
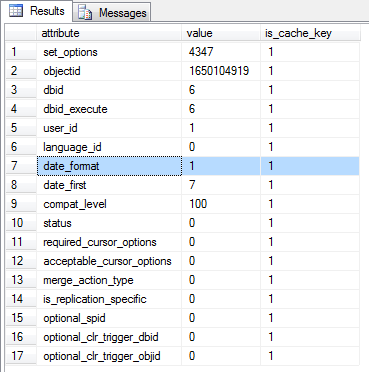
-- Ändern der Verbindungseinstellungen SET DATEFORMAT ymd; EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000016'; SET DATEFORMAT dmy;
Manipulation des Aufrufs der Prozedur
Die Idee, Sessionkonfigurationen zur Laufzeit anzupassen, ist keine gute Lösung. Das obige Beispiel könnte sogar dazu führen, dass die Applikation nicht mehr korrekt läuft, wenn das Datum nicht in einem vorher bestimmten Format verwendet wird. Oft reicht es aus, den Aufruf unmittelbar anzupassen, damit eine Neukompilierung durchgeführt wird. Ebenfalls wird diese Lösung nur bedingt helfen, da der Ausführungsplan für alle Anwender gilt – und somit bei erneuter Ausführung auf die gleichen Parameter und Cachesettings trifft!
Mit dem folgenden T-SQL-Aufruf (gestartet innerhalb der Applikation) kann eine Neukompilierung der Stored Procedure erzwungen werden:
EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000013' WITH RECOMPILE; GO EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000016' WITH RECOMPILE; GO
Durch die Option „WITH RECOMPILE“ auf Ebene der Prozedur wird die vollständige Prozedur neu kompiliert. Diese Technik ist nicht zu empfehlen, wenn die Prozedur sehr umfangreich ist und innerhalb der Prozedur komplexe Abfragen mit einer langen Optimierungsphase verwendet werden.
Neukompilierung in Prozedur
Wenn es an den Möglichkeiten mangelt, den Applikationscode zu manipulieren, bleibt als Alternativ die Optimierung IN der Prozedur. In diesem Fall muss die Neukompilierung durch die Prozedur selbst bestimmt werden. Hierzu gibt es zwei Lösungsansätze:
- Neukompilierung der vollständigen Prozedur
- Neukompilierung des betroffenen Statements
Bis einschließlich Microsoft SQL Server 2000 war eine Neukompilierung nur auf Ebene der Prozedur möglich; seit Microsoft SQL Server 2005 gibt es die Möglichkeit der Neukompilierung auf „Statementlevel“. Um eine Neukompilierung der vollständigen Prozedur zu erzwingen, ist der Hinweis unmittelbar im Prozedurkopf zu platzieren:
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle @CostCenter CHAR(7) WITH RECOMPILE AS SET NOCOUNT ON; SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter WHERE CostCenter = @CostCenter; SET NOCOUNT OFF; GO
Durch die Verwendung von „WITH RECOMPILE“ im Prozedurkopf wird die vollständige Prozedur bei jedem Aufruf neu kompiliert. Bei dieser Technik gilt es zu beachten, wie komplex die Prozedur ist und ob das Verhindern von Parameter Sniffing nicht durch lange Kompilier- und Optimierungszeiten erkauft wird.
Ist eine Prozedur sehr komplex und es lassen sich Statements isolieren, die Opfer von Parameter Sniffing sind, kann ein RECOMPILE seit Microsoft SQL Server 2005 auf einzelne Statements angewendet werden.
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle @CostCenter CHAR(7) AS SET NOCOUNT ON; SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter WHERE CostCenter = @CostCenter OPTION (RECOMPILE); SET NOCOUNT OFF; GO
Verwendung des Density Vectors
Wenn Microsoft SQL Server einen Ausführungsplan erstellt, gibt es zwei Möglichkeiten zur Bestimmung der geschätzten Anzahl von Datensätzen:
- Verwendung des Histogramms
- Verwendung des Density Vectors
Microsoft SQL Server kann das Histogramm eines Statistikobjekts nur verwenden, wenn zur Kompilierzeit des Befehls der Wert des Prädikats bekannt ist. Ist das nicht der Fall, muss Microsoft SQL Server vom Histogramm einer Statistik auf den Density Vektor ausweichen.
-- Density Vector der Statistiken DBCC SHOW_STATISTICS (N'dbo.Mitarbeiter', N'nix_Mitarbeiter_CostCenter') WITH STAT_HEADER; DBCC SHOW_STATISTICS (N'dbo.Mitarbeiter', N'nix_Mitarbeiter_CostCenter') WITH DENSITY_VECTOR;

Die Abbildung zeigt sowohl den Header als auch den Density Vektor der Statistiken des Index „nix_Mitarbeiter_CostCenter“. Zur Berechnung der geschätzten Anzahl von Datensätzen wird der Wert aus [All Density] im Density Vector mit dem [Rows] aus dem Header multipliziert.
0,0625 * 8932 = 558,25
Ein Problem bei der Verwendung des Density Vektors ist der generische Ansatz, der mit diesen Informationen verfolgt wird. Der Density Vektor kann nur einen Mittelwert bilden. Wenn die Datengrundlage eine gleichmäßige Verteilung der Daten gewährleistet, ist der Density Vektor ein probates Hilfsmittel zur Bestimmung der geschätzten Rückgabemenge; aber dann wäre Parameter Sniffing kein Problem.
Die Demodaten haben einen heterogenen Verteilungsschlüssel; mal sind es extrem viele Datensätze („C000016“) während auf der anderen Seite deutlich weniger Datensätze vorhanden sind („C000013“). Um Microsoft SQL Server zu zwingen, den Density Vektor statt das Histogramm zu verwenden, gibt es zwei programmatische Möglichkeiten:
- Verwendung einer neuen Variablen im Code der Prozedur
- Verwendung von OPTION (OPTIMIZE FOR UNKNOWN)
Verwendung von Variablen
Die Kompilierung erfolgt auf Statement-Level. Die Verwendung einer zusätzlichen Variablen innerhalb der Prozedur führt dazu, dass Microsoft SQL Server nicht bestimmen kann, welchen Wert die Variable hat, wenn sie im SELECT-Statement angewendet wird.
Da ein Wert beim Kompilieren des SELECT-Statements nicht deterministisch ist, kann Microsoft SQL Server kein Histogramm verwenden sondern muss auf den Density Vektor ausweichen. Das führt dazu, dass Microsoft SQL Server für JEDE Ausführung den Mittelwert von 558,25 Datensätzen annimmt. Dieser Wert ist für die Kostenstelle C000013 deutlich zu hoch während der Wert für die Kostenstelle C000016 klar zu niedrig ist.
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle
@CostCenter CHAR(7)
AS
SET NOCOUNT ON;
-- Deklaration einer neuen Variablen!
DECLARE @myCostCenter CHAR(7) = @CostCenter;
SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter
WHERE CostCenter = @myCostCenter;
SET NOCOUNT OFF;
GO
Die Abbildung zeigt die gespeicherten Ausführungspläne für die verwendeten Kostenstellen. In beiden Ausführungsplänen wird vom generischen Wert des Density Vektors als „geschätzte Zeilen“ ausgegangen.
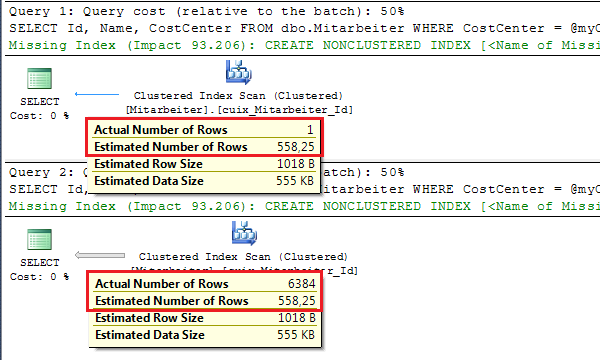
Verwendung von OPTION (OPTIMIZE FOR UNKNOWN)
Statt mit einer neuen Variablen in der Stored Procedure zu arbeiten, kann im Statement selbst die Option „OPTIMIZE FOR UNKNOWN“ verwendet werden. Wie es der Befehl bereits suggeriert, verhält sich die Anweisung so, als ob ihr der Wert der Prozedurvariablen zum Zeitpunkt der Kompilierung nicht bekannt ist. Diese Option verhält sich exakt wie die zuvor beschriebene Verwendung von neuen Variablen in der Stored Procedure; und erbt damit alle Vor- und Nachteilen dieser Technik.
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle
@CostCenter CHAR(7)
AS
SET NOCOUNT ON;
SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter
WHERE CostCenter = @CostCenter OPTION (OPTIMIZE FOR UNKNOWN);
SET NOCOUNT OFF;
GO
Verwendung von Plan Guides
Mit Planhinweislisten kann die Leistung von Abfragen optimiert werden, wenn die Abfrage nicht unmittelbar angepasst werden kann. Planhinweislisten beeinflussen die Abfrageoptimierung, indem Abfragehinweise oder ein fester Abfrageplan für die Abfragen verfügbar gemacht werden. Um einen Abfrageplan zu erstellen, wird die Prozedur sys.sp_create_plan_guide verwendet. Wenn z. B. für die Beispielprozedur angegeben werden soll, dass der Ausführungsplan jedes Mal neu berechnet werden soll (RECOMPILE), müsste ein Planhinweis für die Prozedur folgendermassen implementiert werden:
EXEC sp_create_plan_guide
@name = N'PG_Employee_By_CostCenter',
@stmt = N'SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter WHERE CostCenter = @CostCenter;',
@type = N'OBJECT',
@module_or_batch = N'dbo.Mitarbeiter_pro_Kostenstelle',
@params = NULL,
@hints = N'OPTION (RECOMPILE)';
GO
Die Verwendung von Planhinweislisten hat den Vorteil, dass Applikationselemente nicht geändert werden müssen. Es gibt viele Softwarehersteller, die – zu Recht – darauf verweisen, dass Anpassungen nicht erlaubt sind und somit ein Garantieanspruch verfällt. Nachteil der Planhinweislisten ist, dass diese Technik nicht in den Express-Editionen von Microsoft SQL Server zur Verfügung stehen.
Ob Microsoft SQL Server eine Planhinweisliste verwendet, kann ebenfalls in den Eigenschaften des Ausführungsplans überprüft werden:
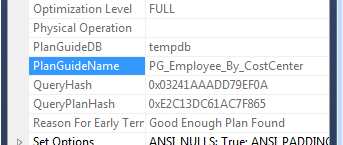
Verwendung von dynamischem Code
Dynamischer Code lässt sich in nicht immer verhindern; für die Lösung des Problems von Parameter Sniffing sollte die nachfolgende Lösung jedoch die letzte Alternative sein. Dynamischer Code bedeutet, dass die auszuführende Abfrage zunächst – dynamisch – in einer Variablen gespeichert wird und anschließend mit EXEC() ausgeführt wird. Die umgeschriebene Prozedur sieht anschließend wie folgt aus:
CREATE PROCEDURE dbo.Mitarbeiter_pro_Kostenstelle
@CostCenter CHAR(7)
AS
SET NOCOUNT ON;
DECLARE @sql_cmd NVARCHAR(256) = N'SELECT Id, Name, CostCenter FROM dbo.Mitarbeiter
WHERE CostCenter = ' + QUOTENAME(@CostCenter, '''');
EXEC (@sql_cmd);
SET NOCOUNT OFF;
GO
Mit der Verwendung von dynamischem SQL geht – neben Sicherheitsbedenken – ein weiterer nicht unerheblicher Nachteil einher, der von vielen Programmierern unterschätzt wird: Plan Cache Bloating!
Bei der Verwendung von dynamischem SQL werden Textfragmente miteinander kombiniert und ergeben so einen – neuen – auszuführenden SQL Befehl. Dieser SQL-Befehl wird dann mittels EXEC in einem eigenen Prozess ausgeführt. Durch die Konkatenation werden keine Variablen innerhalb des SQL-Befehls verwendet sondern ein „fertig designeder Code“ an die Engine gesendet; JEDER unterschiedliche SQL-Befehl wird mit einem eigenen Ausführungsplan im Plan Cache gespeichert!
Die Beispielprozedur wird mit drei unterschiedlichen Kostenstellen ausgeführt. Bei der Analyse der Ausführungspläne ist offensichtlich, dass Microsoft SQL Server für jedes Statement einen „individuellen“ Ausführungsplan erstellt.
EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000013'; GO EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000016'; GO EXEC dbo.Mitarbeiter_pro_Kostenstelle @CostCenter = 'C000019'; GO
SELECT T.Text,
QP.usecounts,
QP.size_in_bytes,
QP.objtype
FROM sys.dm_exec_cached_plans AS QP
CROSS APPLY sys.dm_exec_sql_text (QP.plan_handle) AS T
WHERE T.text LIKE '%FROM dbo.Mitarbeiter%'
AND T.text NOT LIKE '%sys.dm_exec_sql_text%';
Die Prozedur wurde insgesamt drei Mal ausgeführt und statt eines einzigen Ausführungsplans wurden drei Pläne erstellt.

Zusammenfassung
Parameter Sniffing ist bei ungleicher Verteilung von Daten eine Herausforderung für jeden SQL Entwickler. Es gibt keine allgemeine Lösung, die als „Silver Bullet“ alle Probleme löst. Sind – wie im verwendeten Beispiel – nur wenige Schlüsselwerte mit unterschiedicher Kardinalität vorhanden, kann die Verwendung von dynamischem Code eine gute Idee sein. Hierbeit gilt es jedoch, den Zugriff auf die Daten durch Views einzuschränken und keinen unmittelbaren Zugriff auf die Tabellen zu gewähren.
Sind die Datenmengen für die einzelnen Werte zu unterschiedlich und Sicherheit ist ein wichtiges Thema, dann scheidet eine Lösung mit dynamischem SQL aus.
Es verbleiben abschließend nur zwei Alternativen. Der Zugriff auf den Density Vekor wird für viele Situationen eine gute Alternative sein; es gibt jedoch Situationen, in denen diese Alternative nicht wirkt, da die verschiedenen Datenwerte zu große Abstände in der Datenmenge haben und somit den Density Vector als ungeeignetes Mittel erscheinen lassen.
Letzte Alternative ist – und bleibt – das Vermeiden einer Speicherung des Ausführungsplans. Nur so ist gewährleistet, dass für jeden einzelnen Wert ein geeigneter Ausführungsplan gewählt wird. Diese Lösung ist jedoch nur so lange ein adäquates Mittel, so lange die Kompilier- und Optimierungsphasen schnell und effizient sind. Wird für den Optimierungsvorgang mehr Zeit aufgewendet als für einen „schlechten“ Plan, sollte man eher den schlechten Plan in Kauf nehmen.
Lesenswert!
- Erland Sommerskog: Slow in the application, fast in SSMS
- Erland Sommarskog: The Curse and Blessings of Dynamic SQL
- Benjamin Nevarez: Parameter Sniffing and Plan Reuse Affecting SET Options
Herzlichen Dank furs Lesen!