von Uwe Ricken | Feb. 13, 2024 | 400, DB Engine, SQL Blog
Berichte, Analysen, PowerBI-Dashboards… – es gibt so gut wie keinen Anwendungsbereich, der nicht regelmäßig Aggregationen über Zeitintervalle benötigt. Es ist dabei unerheblich, ob es nur das reine Zählen von Datenreihen oder aber die Suche nach dem...
von Uwe Ricken | Sep. 29, 2023 | DB Engine, Informationen, SQL Blog
Ich hatte gerade einen interessanten Email-Austausch mit einem Kunden, der eine Modernisierung seiner SQL Server Landschaft plant. In der EMail erwähnte er unter anderem, dass er gerne die Modernisierung verschieben wolle oder aber auf eine vom Hersteller der Software...
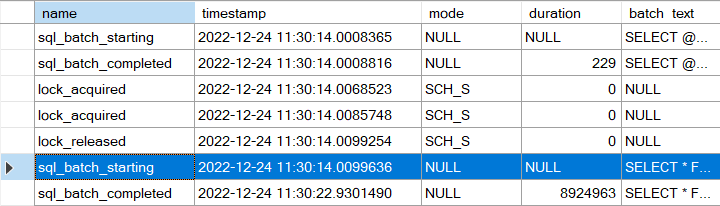
von Uwe Ricken | Dez. 26, 2022 | DB Engine, SQL Blog, Tipps und Tricks
Immer wieder treffe ich auf Applikationen, die inflationär die Option WITH (NOLOCK) verwenden. Bitte hört damit auf. NOLOCK bedeutet nicht, dass ohne Sperren gearbeitet wird. Vielmehr können durch die Verwendung mehr Probleme auftreten, als vermeintlich gelöst werden....
von Uwe Ricken | Dez. 24, 2020 | 300, Administration, DB Engine, Optimierung, SQL Blog
Transaktionale Replikationen können eine wahre Herausforderung sein, wenn es darum geht, die Daten effizient zu den Subscribern zu übertragen. Letzte Woche ergab es sich, dass ein Kunde in einer Datenbank sehr große Datenvolumen änderte. Die Datenbank ist der...
von Uwe Ricken | Apr. 19, 2020 | 300, DB Engine, Indexierung, SQL Blog
Im vorherigen Artikel „Heaps – Lesen von Daten“ wurden die Möglichkeiten beschrieben, wie die Performance für das Auswählen von Daten aus einem Heap optimiert werden kann. Dieser Artikel beschreibt die Möglichkeit, mit Hilfe von NonClustered Indexes...
von Uwe Ricken | Apr. 18, 2020 | 300, DB Engine, Indexierung, SQL Blog
Heaps sind nicht unbedingt des Entwicklers liebstes Kind, da sie insbesondere bei der Auswahl von Daten nicht sehr performant sind (so denken die meisten!). Sicherlich ist da etwas Wahres dran – aber letztendlich entscheidet immer der Workload. In diesem Artikel...





