Ein Kunde beklagte sich über die schlechte Ausführungsgeschwindigkeit einer Funktion, die er von einem Programmierer erhalten hatte. Bei der Durchsicht des Codes der Funktion war das Problem schnell gefunden. Statt eines performanten Indexseek hat die Abfrage einen Indexscan durchgeführt. Ursache für die schlechte Performance war, dass die WHERE-Klausel keine SARGable Argumente verwendete.
Was bedeutet SARGable?
Hinter dem Begriff “SARGable” verbirgt sich ein Akronym für “Search ARGumentable Query”. Dieser Ausdruck sagt aus, dass ein RDBMS-System mit Hilfe eines Prädikats in der Lage ist, Werte innerhalb eines Index zu finden. Dabei kann das RDBMS-System gezielt nach den Werten innerhalb des Index mit Hilfe einer SEEK-Operation suchen. Wenn als Prädikat (WHERE-Klausel) eine Transformation der Werte einer Spalte durchführen muss, spricht man von “NONSARGable” Abfragen. In diesem Fall kann das RDBMS-System einen Index nicht gezielt durchsuchen sondern muss jeden Eintrag transformieren und mit dem Prädikat vergleichen. Eine SEEK-Operation ist dann nicht mehr möglich und es muss eine SCAN-Operation verwendet werden.
Testumgebung
Für die Demonstration der unterschiedlichen Verfahren dient eine einfache Tabelle, in der Mitarbeiter und deren Kostenstellen gespeichert werden.
Tabelle
CREATE TABLE dbo.Employees
(
ID INT NOT NULL,
[Name] CHAR(1000) NOT NULL,
[CostCenter] CHAR(5) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX nix_Employees_CostCenter ON dbo.Employees (CostCenter);
GO
Die Tabelle besitzt ~12.500 Datensätze.
Distribution der Daten
Die Beispieldaten in der indexierten Spalte [CostCenter] sind wie folgt verteilt
DBCC SHOW_STATISTICS (N'dbo.Employees', N'nix_Employees_CostCenter') WITH HISTOGRAM;

Für die nachfolgenden Beispiele sollen alle Mitarbeiter der Kostenstellen Cxxxx dienen.
Funktion
Die vom Programmierer zur Verfügung gestellte Funktion hatte den – korrespondierend zum Beispiel – folgenden Inhalt:
CREATE FUNCTION dbo.GetEmployeesByCostCenter
(@CostCenterPrefix CHAR(1))
RETURNS TABLE
AS
RETURN
(
SELECT Id, Name, CostCenter
FROM dbo.Employees
WHERE SUBSTRING(CostCenter, 1, 1) = @CostCenterPrefix
);
Die Funktion erwartet als Parameter lediglich das Präfix der gewünschten Kostenstellen. Der Programmierer hat die Funktion SUBSTRING verwendet, um aus dem gespeicherten Wert das Präfix zu filtern.
Demonstrationen
Ursprüngliche Funktion
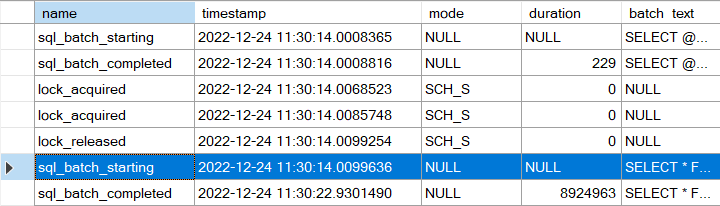
Die Abfrage nach Daten der Kostenstellen, die mit “C” beginnen (160 Datensätze) generieren den folgenden Ausführungsplan.
SELECT * FROM dbo.GetEmployeesByCostCenter('C');

Die Abfrage verwendet einen TABLE SCAN und kann den Index auf [CostCenter] nicht verwenden. Ein Blick in die Eigenschaften des Operators zeigt das Problem. Statt einen performanten INDEX SEEK verwendet Microsoft SQL Server für ALLE Datensätze einen transformierten Wert, der aus der Spalte [ConstCenter] resultiert. Das erste Zeichen aus [CostCenter] wird extrahiert. Anschließend kann dieser extrahierte Wert mit dem Übergabeparameter verglichen werden. Da erst JEDER Wert transformiert werden muss, ist ein INDEX SEEK nicht möglich.

Die obige Abbildung zeigt, wie sich die Abfrage verhält. Das Ergebnis der [Transformation] wird mit dem Präfix verglichen, das der Funktion übergeben wird. Alle Datensätze, deren Transformation der Spalte [CostCenter] ein “C” ergeben, werden an den Client zurückgeliefert. Dazu ist es aber erforderlich, erst für ALLE Datensätze die Transformation durchzuführen.
Modifizierte Funktion
Um Microsoft SQL Server zu veranlassen, einen Index effektiv zu nutzen, darf ein Attribut nicht durch eine Funktion oder durch Operationen geändert werden, bevor das Ergebnis ausgewertet werden soll. Das Ziel muss sein, dass unmittelbar im Wert selbst gesucht werden soll. Die Funktion wurde in der Auswertung des Prädikats geringfügig geändert – im Ergebnis kann Microsoft SQL Server einen performanten INDEX SEEK verwenden.
CREATE FUNCTION dbo.GetEmployeesByCostCenter
(@CostCenterPrefix CHAR(1))
RETURNS TABLE
AS
RETURN
(
SELECT Id, Name, CostCenter
FROM dbo.Employees
WHERE CostCenter >= @CostCenterPrefix
AND CostCenter < CHAR(ASCII(@CostCenterPrefix) + 1)
);

Zusammenfassung
Es ist unumgänglich, bei der Suche nach Optimierungsmöglichkeiten Details innerhalb eines Ausführungsplans zu beachten. Bei Einschränkungen mittels WHERE-Klausel sollte immer darauf geachtet werden, eine SEEK-Einschränkung (Predicate) zu erzielen. Funktionen und Operationen von Attributen verhindern in der Regel diesen Optimierungsschritt.
Herzlichen Dank fürs Lesen!