In einem aktuellen Projekt bin ich auf eine Technik gestoßen, die – LEIDER – noch viel zu häufig von Programmierern im Umfeld von Microsoft SQL Server angewendet wird; Konkatenation von Texten zu vollständigen SQL-Befehlen und deren Ausführung mittels EXEC(). Dieser Artikel beschreibt einen – von vielen – Nachteil, der sich aus dieser Technik ergibt und zeigt einen Lösungsweg, die in den nachfolgenden Beispielen gezeigten Nachteile zu umgehen.
Dynamisches SQL
Unter “dynamischem SQL“ versteht man eine Technik, mit der man SQL-Fragmente mit variablen Werten (meistens aus zuvor deklarierten Variablen) zur Laufzeit zusammensetzt so dass sich aus den Einzelteilen am Ende ein vollständiges SQL Statement gebildet hat. Dieser “SQL-Text“ wird entweder mit EXEC() oder mit sp_executesql ausgeführt. Das nachfolgende Code-Beispiel zeigt die – generelle – Vorgehensweise:
-- Erstellen einer Demotabelle mit verschiedenen Attributen
CREATE TABLE dbo.demo_table
(
Id INT NOT NULL IDENTITY (1, 1),
KundenNo CHAR(5) NOT NULL,
Vorname VARCHAR(20) NOT NULL,
Nachname VARCHAR(20) NOT NULL,
Strasse VARCHAR(20) NOT NULL,
PLZ VARCHAR(10) NOT NULL,
Ort VARCHAR(20) NOT NULL
);
GO
/* Eintragen von 5 Beispieldatensätzen */
SET NOCOUNT ON;
GO
INSERT INTO dbo.demo_table (KundenNo, Vorname, Nachname, Strasse, PLZ, Ort)
VALUES
('00001', 'Uwe', 'Ricken', 'Musterweg 10', '12345', 'Musterhausen'),
('00002', 'Berthold', 'Meyer', 'Parkstrasse 5', '98765', 'Musterburg'),
('00003', 'Beate', 'Ricken', 'Badstrasse 15', '87654', 'Monopoly'),
('00004', 'Emma', 'Ricken', 'Badstrasse 15', '87654', 'Monopoly'),
('00005', 'Udo', 'Lohmeyer', 'Brühlgasse 57', '01234', 'Irgendwo');
GO
Der Code erstellt eine Beispieltabelle und füllt sie mit 5 Datensätzen. Dynamisches SQL wird anschließend wie folgt angewendet:
DECLARE @stmt NVARCHAR(4000);
DECLARE @col NVARCHAR(100);
DECLARE @Value NVARCHAR(100);
SET @Col = N'Nachname';
SET @Value = N'Ricken';
SET @stmt = N'SELECT * FROM dbo.demo_table ' +
CASE WHEN @Col IS NOT NULL
THEN N'WHERE ' + @Col + N' = ' + QUOTENAME(@Value, '''') + N';'
ELSE N''
END
SELECT @stmt;
EXEC sp_executesql @stmt;
SET @Col = N'PLZ';
SET @Value = N'87654';
SET @stmt = N'SELECT * FROM dbo.demo_table ' +
CASE WHEN @Col IS NOT NULL
THEN N'WHERE ' + @Col + N' = ' + QUOTENAME(@Value, '''') + N';'
ELSE N''
END
SELECT @stmt;
EXEC sp_executesql @stmt;
Den deklarierten Variablen werden Parameterwerte zugewiesen und anschließend wird aus diesen Parametern ein SQL-Statement generiert. Dieses SQL-Statement wird im Anschluss ausgeführt und das Ergebnis ausgegeben.

Statistiken
Basierend auf Statistiken generiert Microsoft SQL Server einen Ausführungsplan für die Durchführung einer Abfrage. Wenn Statistiken nicht akkurat/aktuell sind, kann im Ergebnis die Abfrage unperformant sein, da Microsoft SQL Server zum Beispiel zu wenig Speicher für die Durchführung reserviert hat. Wie unterschiedlich Ausführungspläne sein können, wenn Microsoft SQL Server weiß, wie viele Datensätze zu erwarten sind, zeigt das nächste Beispiel:
CREATE TABLE dbo.Addresses
(
Id INT NOT NULL IDENTITY (1, 1),
Strasse CHAR(500) NOT NULL DEFAULT ('Einfach nur ein Füller'),
PLZ CHAR(5) NOT NULL,
Ort VARCHAR(100) NOT NULL
);
GO
CREATE UNIQUE CLUSTERED INDEX cix_Addresses_Id ON dbo.Addresses (Id);
GO
/* 5000 Adressen aus Frankfurt */
INSERT INTO dbo.Addresses (PLZ, Ort) VALUES ('60313', 'Frankfurt am Main');
GO 5000
/* 1000 Adressen aus Darmstadt */
INSERT INTO dbo.Addresses (PLZ, Ort) VALUES ('64283', 'Darmstadt');
GO 1000
/* 100 Adressen aus Hamburg */
INSERT INTO dbo.Addresses (PLZ, Ort) VALUES ('20095', 'Hamburg');
GO 100
/* 100 Adressen aus Erzhausen */
INSERT INTO dbo.Addresses (PLZ, Ort) VALUES ('64390', 'Erzhausen');
GO 100
/* Erstellung eines Index auf ZIP*/
CREATE NONCLUSTERED INDEX ix_Addresses_ZIP ON dbo.Addresses (PLZ);
GO
Der Code erstellt eine Tabelle mit dem Namen [dbo].[Addresses] und füllt sie mit unterschiedlichen Mengen verschiedener Adressen. Während für eine Großstadt wie Frankfurt am Main sehr viele Adressen in der Tabelle vorhanden sind, sind das für ein Dorf nur wenige Datensätze. Sobald alle Datensätze in die Tabelle eingetragen wurden, wird zu Guter Letzt auf dem Attribut [ZIP] ein Index erstellt, um effizient nach der PLZ zu suchen.
/* Beispiel für viele Datensätze */ SELECT * FROM dbo.Addresses WHERE PLZ = '60313'; GO /* Beispiel für wenige Datensätze */ SELECT * FROM dbo.Addresses WHERE PLZ = '64390'; GO
Die beiden Abfragen erzeugen unterschiedliche Abfragepläne, da – je nach Datenmenge – die Suche durch die gesamte Tabelle effizienter sein kann, als jeden Datensatz einzeln zu suchen.

Die Abbildung zeigt, dass für eine große Datenmenge (5.000 Datensätze) ein Suchmuster über die komplette Tabelle für den Query Optimizer die schnellste Möglichkeit ist, die gewünschten Daten zu liefern. Bei einer – deutlich – kleineren Datenmenge entscheidet sich der Query Optimizer für eine Strategie, die den Index auf [ix_Adresses_ZIP] berücksichtigt aber dafür in Kauf nimmt, dass fehlende Informationen aus der Tabelle entnommen werden müssen (Schlüsselsuche/Key Lookup).
Die entsprechende Abfragestrategie wird unter Zuhilfenahme von Statistiken realisiert. Microsoft SQL Server überprüft die Verteilung der Daten im Index [ix_Addresses_ZIP] und entscheidet sich – basierend auf dem Ergebnis – anschließend für eine geeignete Abfragestrategie.
DBCC SHOW_STATISTICS ('dbo.Addresses', 'ix_Adresses_ZIP') WITH HISTOGRAM;

Testumfeld
Im der Testumgebung wird eine Tabelle mit dem Namen [dbo].[Orders] angelegt. Diese Tabelle besitzt 10.000.000 Datensätze, die pro Handelstag die Orders aus einem Internetportal speichert. Dazu werden die Käufe jede Nacht von der Produktionsdatenbank in die Reporting-Datenbank übertragen. Insgesamt sind Bestellungen vom 01.01.2015 bis zum 10.01.2016 in der [dbo].[Orders] gespeichert. Pro Tag kommen 25.000 – 30.000 Bestellungen dazu. Die Tabelle hat folgende Struktur:
CREATE TABLE dbo.Orders
(
Order_Id INT NOT NULL IDENTITY (1, 1),
Customer_No CHAR(5) NOT NULL,
OrderDate DATE NOT NULL,
ShippingDate DATE NULL,
Cancelled BIT NOT NULL DEFAULT (0)
);
GO
CREATE UNIQUE CLUSTERED INDEX cix_Orders_Order_Id ON dbo.Orders(Order_ID);
CREATE NONCLUSTERED INDEX ix_Orders_Customer_No ON dbo.Orders (Customer_No);
CREATE NONCLUSTERED INDEX ix_Orders_OrderDate ON dbo.Orders (OrderDate);
GO
Die – aktuellen – Statistiken für das Bestelldatum (OrderDate) sind bis zum 10.01.2016 gepflegt!

Für die Abfrage(n) aus dieser Tabelle wird eine Stored Procedure mit dem folgenden Code programmiert:
CREATE PROC dbo.proc_SearchOrders
@Search_Shipping BIT,
@Search_Date DATE,
@Additional_Column NVARCHAR(64),
@Additional_Value VARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @stmt NVARCHAR(4000) = N'SELECT * FROM dbo.Orders'
IF @Search_Shipping = 1
SET @stmt = @stmt + N' WHERE ShippingDate = ''' + CONVERT(CHAR(8), @Search_Date, 112) + N''''
ELSE
SET @stmt = @stmt + N' WHERE OrderDate = ''' + CONVERT(CHAR(8), @Search_Date, 112) + N''''
IF @Additional_Column IS NOT NULL
SET @stmt = @stmt + N' AND ' + @Additional_Column + N' = ''' + @Additional_Value + ''''
EXEC sp_executesql @stmt;
SET NOCOUNT OFF;
END
GO
Der Code verwendet dynamisches SQL, um einen ausführbaren Abfragebefehl zu konkatenieren. Dabei werden nicht nur die zu verwendenden Spalten konkateniert sondern auch die abzufragenden Werte werden dynamisch dem SQL-String hinzugefügt. Somit ergibt sich bei der Ausführung der Prozedur je nach Parameter immer ein unterschiedlicher Abfragebefehl wie die folgenden Beispiele zeigen:
EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160101',
@Additional_Column = NULL,
@Additional_Value = NULL;
GO
EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160101',
@Additional_Column = 'Customer_No',
@Additional_Value = '44196';

Problem
Abhängig von den Parametern werden unterschiedliche Abfragebefehle konkateniert. Microsoft SQL Server kann – bedingt durch die unterschiedlichen Kombinationen aus abzufragenden Spalten und abzufragenden Werten – keinen einheitlichen Ausführungsplan für die Abfrage erstellen. Sobald ein ausführbarer SQL Code geringster Abweichungen (Kommentare, Leerzeichen, Werte) besitzt, behandelt Microsoft SQL Server den Ausführungstext wie eine NEUE Abfrage und erstellt für die auszuführende Abfrage einen neuen Ausführungsplan.
EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160105',
@Additional_Column = NULL,
@Additional_Value = NULL;
GO
Die Prozedur erzeugt den folgenden Ausführungsplan:

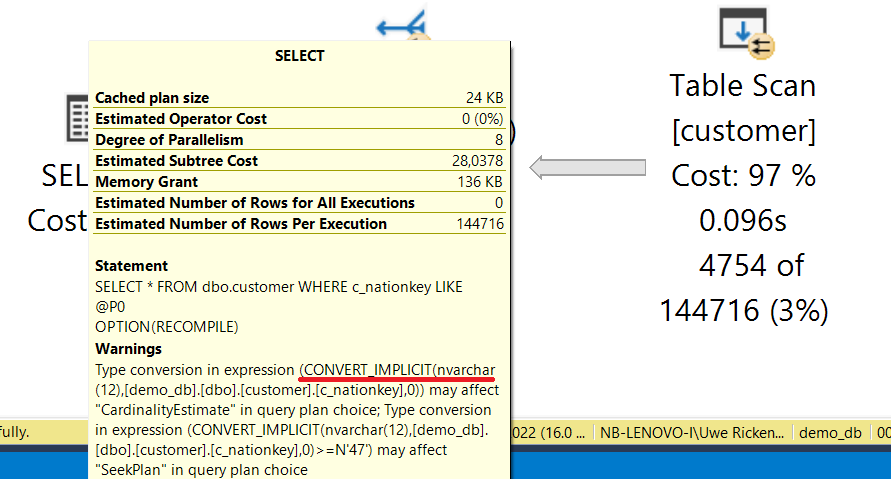
Microsoft SQL Server prüft die Daten für den 05.01.2016 im Histogramm und schätzt, dass ca. 26.600 Datensätze zurückgeliefert werden. Diese “Schätzung“ ist sehr nah an den realen Daten und die Abfrage wird mittels INDEX SCAN durchgeführt. Je nach Datum werden immer wieder NEUE Ausführungspläne generiert und im Prozedur Cache abgelegt.
Statistiken werden von Microsoft SQL Server automatisch aktualisiert, wenn mindestens 20% der Daten in einem Index geändert wurden. Sind sehr viele Datensätze in einem Index, dann kann diese Aktualisierung recht lange auf sich warten lassen.
Wenn Microsoft SQL Server mit einem Abfragewert konfrontiert wird, der NICHT in den Statistiken vorhanden ist, dann „schätzt“ Microsoft SQL Server immer, dass sich 1 Datensatz in der Tabelle befindet. Dieses Problem kommt im obigen Beispiel zum tragen. Jeden Tag werden die aktuellsten Orders in die Tabelle eingetragen. In der Tabelle befinden sich 10.000.000 Datensätze. Insgesamt müssten nun 2.000.000 Datenänderungen durchgeführt werden, um die Statistiken automatisch zu aktualisieren.
Die Stored Procedure wird im nächsten Beispiel für den 11.01.2016 aufgerufen. Wie aus der Abbildung erkennbar ist, sind Werte nach dem 10.01.2016 noch nicht in der Statistik vorhanden. Sollten also Werte in der Tabelle sein, dann verarbeitet Microsoft SQL Server die Anfrage wie folgt:
- Da der Parameter für das OrderDate im Abfragetext konkateniert wird, wird ein NEUER Abfrageplan erstellt
- Bei der Erstellung des Plans schaut Microsoft SQL Server in die Statistiken zum OrderDate und stellt fest, dass der letzte Eintrag vom 10.01.2016 ist
- Microsoft SQL Server geht davon aus, dass für den 11.01.2016 lediglich 1 Datensatz in der Datenbank vorhanden ist
- Der Ausführungsplan wird für 1 Datensatz geplant und gespeichert

Die Abbildung zeigt den Ausführungsplan in Microsoft SQL Server, wie er für den 11.01.2016 geplant wurde. Es ist erkennbar, dass die geschätzte Anzahl von Datensätzen DEUTLICH unter dem tatsächlichen Ergebnis liegt. Solche Fehleinschätzungen haben in einem Ausführungsplan Seiteneffekte:
- Der geplante Speicher für die Ausführung der Abfrage wird niedriger berechnet als er tatsächlich benötigt wird. Da nachträglich kein Speicher mehr allokiert werden kann, werden einige Operatoren die Daten in TEMPDB zwischenspeichern (SORT / HASH Spills)
- Nested Loops sind ideal für wenige Datensätze. Ein Nested Loop geht für jeden Datensatz aus der “OUTER TABLE“ in die “INNER TABLE“ und fragt dort über das Schlüsselattribut Informationen ab. Im obigen Beispiel hat sich Microsoft SQL Server für einen Nested Loop entschieden, da das geschätzte IO für einen Datensatz deutlich unter einem INDEX SCAN liegt. Tatsächlich müssen aber nicht 1 Datensatz aus dem Clustered Index gesucht werden sondern 2.701 Datensätze!
Konkatenierte SQL Strings verhalten sich wie Ad Hoc Abfragen. Sie führen dazu, dass der Prozedur/Plan Cache übermäßig gefüllt wird. Ebenfalls geht wertvolle Zeit verloren, da für jede neue Konkatentation ein neuer Plan berechnet und gespeichert werden muss!
Die nächste Abfrage ermittelt – aus den obigen Beispielen – die gespeicherten Ausführungspläne.
SELECT DEST.text,
DECP.usecounts,
DECP.size_in_bytes,
DECP.cacheobjtype
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text (DECP.plan_handle) AS DEST
WHERE DEST.text LIKE '%Orders%' AND
DEST.text NOT LIKE '%dm_exec_sql_text%';

Das Ergebnis zeigt, dass die Prozedur zwei Mal aufgerufen wurde. Dennoch musste für JEDEN konkatenierten Ausführungstext ein eigener Plan erstellt und gespeichert werden.
Lösung
Nicht immer kann man auf dynamisches SQL verzichten. Es wird immer Situationen geben, in denen man mit den Herausforderungen von dynamischen SQL konfrontiert wird. In diesen Situationen ist es wichtig, zu verstehen, welchen Einfluss solche Entscheidungen auf die Performance der Abfragen haben. Im gezeigten Fall sind – unter anderem – Statistiken ein Problem. Es muss also eine Lösung geschaffen werden, die darauf baut, dass Pläne wiederverwendet werden können – Parameter! Es muss eine Lösung gefunden werden, bei der zwei wichtige Voraussetzungen erfüllt werden:
- Der auszuführende Befehl darf sich nicht mehr verändern
- Ein einmal generierter Plan muss wiederverwendbar sein
Beide Voraussetzungen kann man mit leichten Modifikationen innerhalb der Prozedur schnell und einfach erfüllen.
ALTER PROC dbo.proc_SearchOrders
@Search_Shipping BIT,
@Search_Date DATE,
@Additional_Column NVARCHAR(64),
@Additional_Value VARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @stmt NVARCHAR(4000) = N'SELECT * FROM dbo.Orders';
DECLARE @vars NVARCHAR(1000) = N'@Search_Date DATE, @Additional_Value VARCHAR(64)';
IF @Search_Shipping = 1
SET @stmt = @stmt + N' WHERE ShippingDate = @Search_Date';
ELSE
SET @stmt = @stmt + N' WHERE OrderDate = @Search_Date';
IF @Additional_Column IS NOT NULL
SET @stmt = @stmt + N' AND ' + QUOTENAME(@Additional_Column) + N' = @Additional_Value';
SET @stmt = @stmt + N';'
SELECT @stmt;
EXEC sp_executesql @stmt, @vars, @Search_Date, @Additional_Value;
SET NOCOUNT OFF;
END
GO
Nachdem der Prozedur Cache gelöscht wurde, wird die Prozedur erneut in verschiedenen Varianten ausgeführt und die Abfragepläne werden analysiert:
EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160105',
@Additional_Column = NULL,
@Additional_Value = NULL;
GO

EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160111',
@Additional_Column = NULL,
@Additional_Value = NULL;
GO

Obwohl nun ein Datum verwendet wird, dass nachweislich noch nicht in den Statistiken erfasst ist, wird dennoch ein identischer Plan verwendet. Ursächlich für dieses Verhalten ist, dass Microsoft SQL Server für beide Ausführungen auf ein identisches Statement verweisen kann – somit kann ein bereits im ersten Durchlauf verwendeter Ausführungsplan angewendet werden. Dieses “Phänomen“ wird Parameter Sniffing genannt. Auch dieses Verfahren hat seine Vor- und Nachteile, die ich im nächsten Artikel beschreiben werde.
EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160105',
@Additional_Column = 'Customer_No',
@Additional_Value = '94485';
GO

EXEC dbo.proc_SearchOrders
@Search_Shipping = 0,
@Search_Date = '20160105',
@Additional_Column = 'Cancelled',
@Additional_Value = '1';
GO

Die nächsten zwei Beispiele zeigen die Ausführungspläne mit jeweils unterschiedlichen – zusätzlichen – Kriterien. Es ist erkennbar, dass Microsoft SQL Server nun für beide Ausführungen jeweils unterschiedliche Ausführungspläne verwendet. Unabhängig von dieser Tatsache werden nun aber nicht mehr für jeden unterschiedlichen Kunden EINZELNE Pläne gespeichert sondern der bei der ersten Ausführung gespeicherte Ausführungsplan wiederverwendet. Die nachfolgende Abfrage zeigt im Ergebnis die gespeicherten Ausführungspläne, die für 10 weitere – unterschiedliche – Kundennummern verwendet wurden:
SELECT DEST.text,
DECP.usecounts,
DECP.size_in_bytes,
DECP.cacheobjtype
FROM sys.dm_exec_cached_plans AS DECP
CROSS APPLY sys.dm_exec_sql_text (DECP.plan_handle) AS DEST
WHERE DEST.text LIKE '%Orders%' AND
DEST.text NOT LIKE '%dm_exec_sql_text%';
GO

Statt – wie bisher – für jede Ausführung mit unterschiedlichen Kundennummern einen eigenen Plan zu speichern, kann der einmal generierte Plan verwendet werden.
Zusammenfassung
Dynamisches SQL wird recht häufig verwendet, um mit möglichst einer – zentralen – Prozedur mehrere Möglichkeiten abzudecken. So legitim dieser Ansatz ist, so gefährlich ist er aber, wenn man dynamisches SQL und Konkatenation wie “gewöhnlichen“ Code in einer Hochsprache verwendet. Microsoft SQL Server muss dann für JEDE Abfrage einen Ausführungsplan generieren. Dieser Ausführungsplan beruht auf Statistiken, die für einen idealen Plan benötigt werden. Sind die Statistiken veraltet, werden unter Umständen schlechte Pläne generiert. Sind die Daten regelmäßig verteilt, bietet es sich an, mit Parametern statt konkatenierten SQL Statements zu arbeiten. Durch die Verwendung von Parametern wird einerseits der Plan Cache entlastet und andererseits muss Microsoft SQL Server bei wiederholter Ausführung mit anderen Werten nicht erneut einen Ausführungsplan erstellen und eine Prüfung der Statistiken entfällt.
Wo Licht ist, ist natürlich auch Schatten! Die oben beschriebene Methode bietet sich nur dann an, wenn die Daten regelmäßig verteilt sind. Wenn die abzufragenden Daten in der Anzahl ihrer Schlüsselattribute zu stark variieren, ist auch diese Lösung mangelhaft! Für das Projekt konnten wir mit dieser Methode sicherstellen, dass NEUE Daten geladen werden konnten und Statistiken nicht notwendiger Weise aktualisiert sein mussten. Die Verteilung der Daten ist für jeden Tag nahezu identisch!
Herzlichen Dank fürs Lesen!