SQL Server Blog
Installation | Konfiguration | Optimierung von Microsoft SQL Server
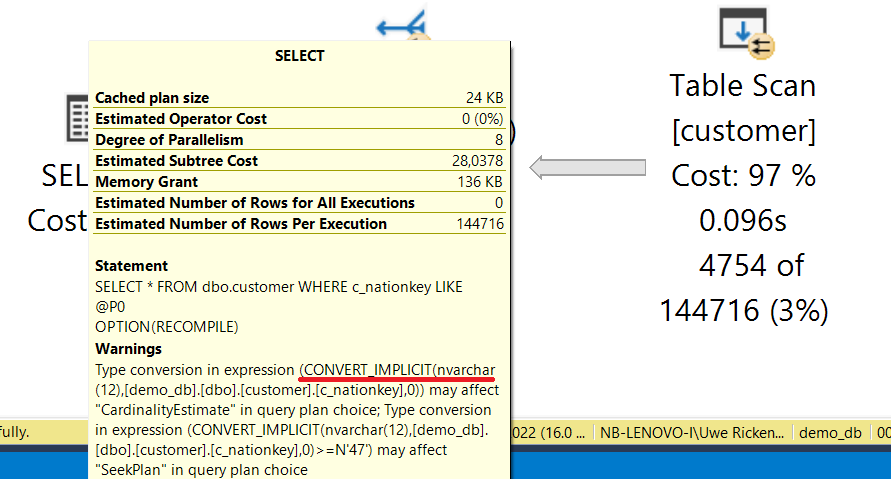
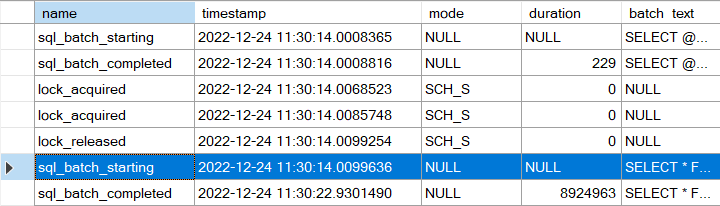
Error 3013 – mehr Details bitte!
Aktuell entwickeln wir eine Log Shipping Lösung für einen Kunden, der sehr viele Datenbanken (>100) auf einem Server hostet. Das standardisierte Log Shipping ist für diese Umgebung nicht geeignet, da für jede Datenbank Log Shipping separat konfiguriert werden muss....
Aggregation über Spalten mit CROSS APPLY
Ein Kunde betreibt eine Applikation, in der Messdaten in einer Tabelle gespeichert werden. Leider haben die Entwickler die Grundlagen der Normalformenlehre nicht beachtet und so kam es wie es kommen musste.
Tabellenobjekt in Management Studio verbergen
Heute Vormittag hatte ich einen Beratungstermin, in dem geklärt werden sollte, wie man Tabellenobjekt(e) in Management Studio verbergen kann. Es ging primär darum, dass Metadaten nicht einfach angezeigt/ausgelesen werden sollten. Die von mir gezeigte Variante schützt...
Transaktionale Replikation und Massendaten-Verarbeitung
Transaktionale Replikationen können eine wahre Herausforderung sein, wenn es darum geht, die Daten effizient zu den Subscribern zu übertragen.
Heaps – Update Operationen
Im vorherigen Artikel habe ich mich intensiv mit INSERT-Operationen und den Besonderheiten bei Heaps beschäftigt. Da aber in Datenbanken nicht nur neue Daten geschrieben werden, müssen auch Besonderheiten bei Aktualisierungen berücksichtigt werden. Dieser Artikel...
Heaps – INSERT Operationen
Nachdem sich die vorherigen Artikel mit den internen Strukturen und der Auswahl von Daten in Heaps beschäftigt haben, werden die nächsten Artikel beschreiben, wie DML-Operationen für einem Heap optimiert werden können. Standardverfahren - INSERT Wenn Datensätze...
SQL Server Internals Group
Im Juli 2017 haben Frank Geisler und Torsten Straus die SIG -SQL Server Internals Group gegründet. Da nach dem siebten Online Events keine Sprecher mehr gefunden wurden, wurde die Plattform nicht mehr aktiv beworben. Auf dem YouTube Channel sind bereits vier Sessions...
Heaps – NonClustered Indizes
Im vorherigen Artikel „Heaps – Lesen von Daten“ wurden die Möglichkeiten beschrieben, wie die Performance für das Auswählen von Daten aus einem Heap optimiert werden kann. Dieser Artikel beschreibt die Möglichkeit, mit Hilfe von NonClustered Indexes ebenfalls effektive Abfragezeiten für Heaps zu erreichen.
Heaps – Lesen von Daten
Heaps sind nicht unbedingt des Entwicklers liebstes Kind, da sie insbesondere bei der Auswahl von Daten nicht sehr performant sind (so denken die meisten!). Sicherlich ist da etwas Wahres dran – aber letztendlich entscheidet immer der Workload. In diesem Artikel beschreibe ich die Arbeitsweise eines Heaps, wenn Daten selektiert werden.
Heaps – Systemstrukturen
Dieser Artikel beschäftigt sich mit den – für Heaps relevanten – internen Strukturen einer Datenbank, die wichtig sind, um Vor- und Nachteile von Heaps für die einzelnen Anwendungsszenarien zu erkennen.