von Uwe Ricken | Feb. 20, 2024 | DB Engine, Optimierung, SQL Blog, Tipps und Tricks
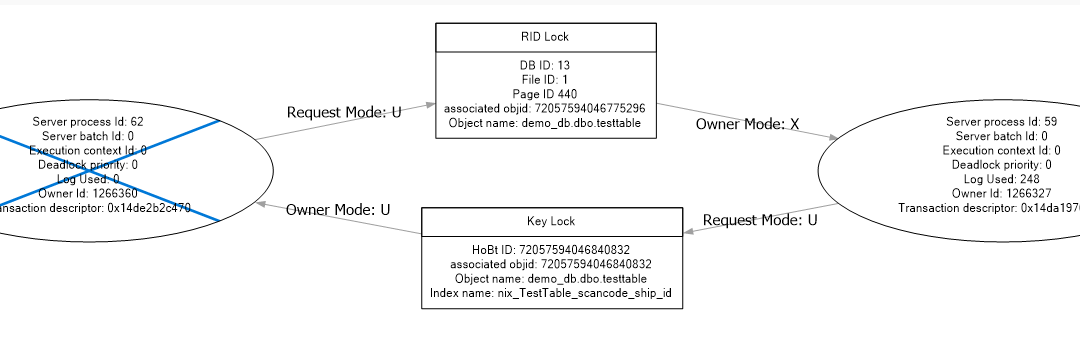
Deadlocks kennt fast jeder DBA, der täglich Datenbanken betreuen muss. Der klassische Deadlock wird – meistens – durch falsche Aufrufe von Prozessen verursacht. Diese Art von Deadlocks sind schnell und relativ einfach zu lösen. Wie aber sieht es aus, wenn...
von Uwe Ricken | Jan. 27, 2023 | SQL Blog
Ich hatte heute einen Kundentermin, in dem die Vorteile von „functional Indexes“, wie sie ORACLE oder POSTGRES kennen, hervorgehoben wurden. Leider kennt Microsoft SQL Server diese Art von Indexen nicht. Dennoch ist es auch mit Microsoft SQL Server...
von Uwe Ricken | Juni 18, 2020 | SQL Blog
Im vorherigen Artikel habe ich mich intensiv mit INSERT-Operationen und den Besonderheiten bei Heaps beschäftigt. Da aber in Datenbanken nicht nur neue Daten geschrieben werden, müssen auch Besonderheiten bei Aktualisierungen berücksichtigt werden. Dieser Artikel...
von Uwe Ricken | Juni 5, 2020 | SQL Blog
Nachdem sich die vorherigen Artikel mit den internen Strukturen und der Auswahl von Daten in Heaps beschäftigt haben, werden die nächsten Artikel beschreiben, wie DML-Operationen für einem Heap optimiert werden können. Standardverfahren – INSERT Wenn Datensätze...
von Uwe Ricken | Apr. 19, 2020 | 300, DB Engine, Indexierung, SQL Blog
Im vorherigen Artikel „Heaps – Lesen von Daten“ wurden die Möglichkeiten beschrieben, wie die Performance für das Auswählen von Daten aus einem Heap optimiert werden kann. Dieser Artikel beschreibt die Möglichkeit, mit Hilfe von NonClustered Indexes...





